
1.问题
对展会数据分类后,我的新任务是如何通过公司名、公司地址、国家等海关数据推断出该公司的官网网站(若官网不存在则不考虑)
以下数据仅供参考:
| 公司名 | 国家 | 地址 |
|---|---|---|
| JPW INDUSTRIES INC | 427 NEW SANFORD RD LAVERGNE TN 37086 US | |
| Fujian Xishi Co., Ltd | CN, CHINA | |
| BusinessPartner Co.,ltd | ||
| BENKAI Co.,Ltd | ||
| GOLD INC | 18245 E 40TH AVE AURORA CO 80011 US |
需要得到结果:
| 公司名 | 官方网站 |
|---|---|
| JPW INDUSTRIES INC | http://http://www.jpwindustries.com/ |
| Fujian Xishi Co., Ltd | http://www.xishigroup.com/ |
| BusinessPartner Co.,ltd | http://www.traderthailand.com/ |
| BENKAI Co.,Ltd | http://www.benkaico.com |
| GOLD INC | https://goldbuginc.com/ |
2.解决
由数据可看出,公司名是绝对存在的,故解决思路是从公司名出发,而不怎么全面的国家以及地址信息则用来提高准确度。
大体思路是这样的,若公司官网存在,那么通过搜索引擎定会被检索到,搜索引擎自然首选google,所以可以先通过获取谷歌搜索的结果,然后分析获取的结果,从而得出最可能是该公司网站的url。
初步搜索一下,看看各种情况:
第一种情况,检索即可很直观地得出结果
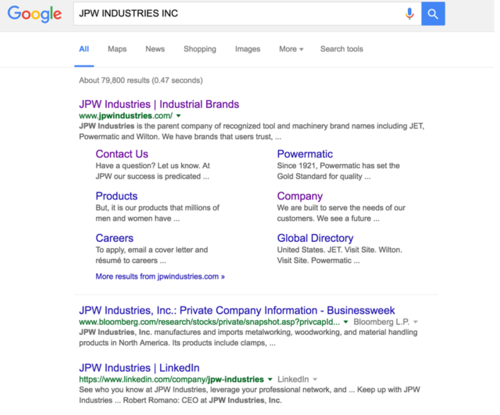 JPW INDUSTRIES INC
JPW INDUSTRIES INC
第二种情况,检索不能直观地得出结果,但官网确实存在(第二检索个结果)
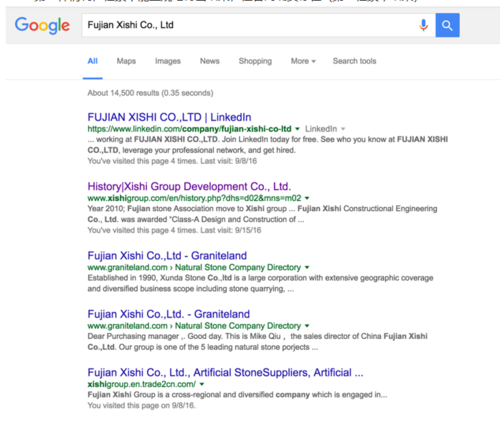 Fujian Xishi Co., Ltd
Fujian Xishi Co., Ltd
第三种情况,输入公司名+公司地址和只输入公司名得出的结果不一样
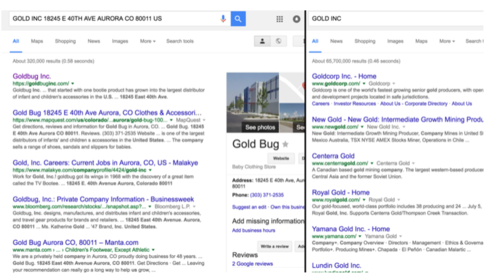 GOLD INC
GOLD INC
对于第三种情况,可以看出输入公司名+公司地址得出的结果是绝对正确的。
观察第三种情况,当输入公司名+公司地址时,返回结果的右侧会出现公司的详细信息,经过验证,若出现这种情况,则其website对应的url绝对正确。
故代码的第一步骤可以首先检索公司名+公司地址,观察website元素是否存在,若存在,返回公司官网,否则,对公司名进行检索。
代码:
def searchWeb(query, tld='com', lang='en', tbs='0', num=10, safe='off', tpe='', user_agent=None): query = quote_plus(query) get_page(url_home % vars()) url = url_search_num % vars() # Request the Google Search results page. html = get_page(url) try: href = re.findall(r'Directions</a><a\s*class="fl"\s*href="(.*?)".*?>Website', str(html))[0] link = filter_result(href) return link except: pass return None
 直接返回公司官网
直接返回公司官网
能直接获取公司官网毕竟是少数,大多数据还是要通过一步步计算得出,主要经过以下步骤:
获取搜索引擎检索结果提取url->初步排除某些url->余弦相似度计算最可能的结果
2.1.获取搜索引擎检索结果提取url
对于谷歌搜索,我使用了MarioVilas的项目google,毕竟在国内,为了以防万一我也写了yahoo搜索,代码如下:
#!/usr/bin/env # -*-coding:utf-8-*- # script: yahooSearch.py __author__ = 'howie' import sys import time if sys.version_info[0] > 2: from urllib.request import Request, urlopen from urllib.parse import quote_plus, urlparse else: from urllib import quote_plus from urllib2 import Request, urlopen from urlparse import urlparse, parse_qs try: from bs4 import BeautifulSoup is_bs4 = True except ImportError: from BeautifulSoup import BeautifulSoup is_bs4 = False url_search = "https://search.yahoo.com/search?p=%(query)s&b=%(start)s&pz=%(num)s" headers = { 'accept-encoding': 'gzip, deflate, sdch, br', 'accept-language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4', 'upgrade-insecure-requests': '1', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'cache-control': 'max-age=0', 'authority': ' search.yahoo.com' } # 默认user_agent user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36' def filter_link(link): try: linkData = urlparse(link) if linkData.netloc and "yahoo.com" not in linkData.netloc and "/search/srpcache" not in linkData.path: return link except Exception: pass return None def yahooSearch(query, start=0, num=10, page=1, pause=1.0): """ 获取雅虎搜索url :param query: 搜索关键词 :param start: 开始条目,最好为0 :param num: 搜索条目 建议10的倍数 :param page: 页数 :param pause: 停顿时间 :return: 返回url """ query = quote_plus(query) while page > 0: url = url_search % vars() time.sleep(pause) request = Request(url) request.add_header('User-Agent', user_agent) response = urlopen(request) html = response.read() if is_bs4: soup = BeautifulSoup(html, 'html.parser') else: soup = BeautifulSoup(html) anchors = soup.find(id="web").find_all('a') for a in anchors: try: link = filter_link(a["href"]) if link: yield link except KeyError: continue start += num + 1 page -= 1 if __name__ == '__main__': # GOLD INC 18245 E 40TH AVE AURORA CO 80011 US for url in yahooSearch("GOLD INC 18245 E 40TH AVE AURORA CO 80011 US"): print(url)2.2.初步排除某些url
这个可根据个人需求来配置,可添加webConfig.py脚本,排除某些url:
# -*-coding:utf-8-*- __author__ = 'howie' config = dict( # www开头或分割后数组大于二的网站 forbid_www=["www.linkedin.com", "www.alibaba.com"], # 非www开头的网站 forbid=["imexbb.com", "made-in-china.com"] )
以公司名BENKAI Co.,Ltd为例,初步获取url:
['http://www.benkaico.com', 'http://hisupplier.com', 'http://www.hktdc.com/en']
2.3.余弦相似度计算最可能的结果
对于公司BENKAI Co.,Ltd,我们获得了三个结果,现在又该如何从该列表中取得最可能的结果呢。
这里可以采用余弦相似度,具体公式可google,稍稍解释下:
对于这三个网站:
['http://www.benkaico.com', 'http://hisupplier.com', 'http://www.hktdc.com/en']``` 可以通过计算各个网站的`title`和`BENKAI Co.,Ltd`的相似程度来取得最可能的结果。 #####2.3.1:对各网站title进行分词 ```python {'http://www.benkaico.com': ['benkai', 'co.', ',', 'ltd', '.'], 'http://www.hktdc.com/en': ['hktdc.com', 'â\x80\x93', 'page', 'not', 'found'], 'http://hisupplier.com': ['china', 'suppliers', ',', 'suppliers', 'directory', ',', 'china', 'manufacturers', 'directory', '-', 'hisupplier.com']}2.3.2:构建单词向量
{'http://www.benkaico.com': [[0, 1, 1, 1, 1], [1, 1, 1, 1, 1]], 'http://www.hktdc.com/en': [[1, 1, 0, 0, 1, 0, 0, 0, 1], [0, 0, 1, 1, 0, 1, 1, 1, 0]], 'http://hisupplier.com': [[0, 0, 0, 1, 0, 0, 1, 1, 0, 1], [2, 1, 1, 0, 2, 1, 2, 0, 2, 0]]}2.3.3:计算余弦相似度
{'http://www.benkaico.com': 0.94427190999915878, 'http://www.hktdc.com/en': 0.0, 'http://hisupplier.com': 0.31451985913875646}通过比较,可以看到http://www.benkaico.com相似度最高的结果,跟真实结果一样。
 http://www.benkaico.com
http://www.benkaico.com
全部步骤代码如下:
# -*-coding:utf-8-*- __author__ = 'howie' from urllib import parse from bs4 import BeautifulSoup from collections import defaultdict import requests import re import nltk import time from config.webConfig import config from CosineSimilarity import CosineSimilarity from search.yahooSearch import yahooSearch from search.gooSearch import search, searchWeb class Website(object): """ 通过公司名等信息获取网站官网 """ def __init__(self, engine='google'): self.forbid_www = config["forbid_www"] self.forbid = config["forbid"] self.engine = engine def get_web(self, query, address=""): """ 获取域名 :param query: 搜索词 :param address: 在此加上地址时,query最好是公司名 :return: 返回最可能是官网的网站 """ if self.engine == 'google' and address: allQuery = query + " " + address result = searchWeb(query=allQuery, num=5) if result: return result allDomain = self.get_domain(query) if len(allDomain) == "1": website = allDomain[0] else: # 初步判断网站域名 counts = self.get_counts(allDomain) largest = max(zip(counts.values(), counts.keys())) if largest[0] > len(allDomain) / 2: website = largest[1] else: # 获取对应域名标题 domainData = self.get_title(set(allDomain)) # 计算相似度 initQuery = nltk.word_tokenize(query.lower(), language='english') # 余弦相似性计算相似度 cos = CosineSimilarity(initQuery, domainData) wordVector = cos.create_vector() resultDic = cos.calculate(wordVector) website = cos.get_website(resultDic) return website def get_domain(self, query): """ 获取谷歌搜索后的域名 :param query:搜索条件 :return:域名列表 """ allDomain = [] if self.engine == "google": for url in search(query, num=5, stop=1): allDomain += self.parse_url(url) elif self.engine == "yahoo": for url in yahooSearch(query): allDomain += self.parse_url(url) if not allDomain: allDomain.append('') return allDomain def parse_url(self, url): allDomain = [] domainParse = parse.urlparse(url) # 英文网站获取 if "en" in domainParse[2].lower().split('/'): domain = domainParse[1] + "/en" else: domain = domainParse[1] domainList = domain.split('.') # 排除干扰网站 if len(domainList) >= 3 and domainList[0] != "www": isUrl = ".".join(domain.split('.')[-2:]) if isUrl not in self.forbid: allDomain.append(domainParse[0] + "://" + isUrl) elif domain not in self.forbid_www: allDomain.append(domainParse[0] + "://" + domain) return allDomain def get_title(self, setDomain): """ 获取对应网站title,并进行分词 :param allDomain: 网站集合 :return: 网站:title分词结果 """ domainData = {} for domain in setDomain: headers = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "Accept-Encoding": "gzip, deflate, sdch", "Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4", "Cache-Control": "max-age=0", "Proxy-Connection": "keep-alive", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36", } try: data = requests.get(domain, headers=headers).text soup = BeautifulSoup(data, 'html.parser') title = soup.title.get_text() title = re.sub(r'\r\n', '', title.strip()) titleToken = nltk.word_tokenize(title.lower(), language='english') domainData[domain] = titleToken except: pass return domainData def get_counts(self, allDomain): """ 返回网站列表各个域名数量 :param allDomain: 网站列表 :return: 网站:数量 """ counts = defaultdict(int) for eachDomain in allDomain: counts[eachDomain] += 1 return counts if __name__ == '__main__': # allQuery = ["National Sales Company, Inc.", "Decor Music Inc.","Fujian Xishi Co., Ltd","Kiho USA Inc.","BusinessPartner Co.,ltd","BENKAI Co.,Ltd"] # GOLD INC 18245 E 40TH AVE AURORA CO 80011 US allQuery = ["ALZARKI INTERNATIONAL"] website = Website(engine='google') for query in allQuery: time.sleep(2) website = website.get_web(query=query) print(website)计算余弦相似度代码
# -*-coding:utf-8-*- # script: CosineSimilarity.py __author__ = 'howie' import numpy as np from functools import reduce from math import sqrt class CosineSimilarity(object): """ 余弦相似性计算相似度 """ def __init__(self, initQuery, domainData): self.title = initQuery self.data = domainData def create_vector(self): """ 创建单词向量 :return: wordVector = {} 目标标题以及各个网站标题对应的单词向量 """ wordVector = {} for web, value in self.data.items(): wordVector[web] = [] titleVector, valueVector = [], [] allWord = set(self.title + value) for eachWord in allWord: titleNum = self.title.count(eachWord) valueNum = value.count(eachWord) titleVector.append(titleNum) valueVector.append(valueNum) wordVector[web].append(titleVector) wordVector[web].append(valueVector) return wordVector def calculate(self, wordVector): """ 计算余弦相似度 :param wordVector: wordVector = {} 目标标题以及各个网站标题对应的单词向量 :return: 返回各个网站相似度值 """ resultDic = {} for web, value in wordVector.items(): valueArr = np.array(value) # 余弦相似性 squares = [] numerator = reduce(lambda x, y: x + y, valueArr[0] * valueArr[1]) square_title, square_data = 0.0, 0.0 for num in range(len(valueArr[0])): square_title += pow(valueArr[0][num], 2) square_data += pow(valueArr[1][num], 2) squares.append(sqrt(square_title)) squares.append(sqrt(square_data)) sum_of_squares = reduce(lambda x, y: x * y, squares) resultDic[web] = numerator / sum_of_squares return resultDic def get_website(self, resultDic): """ 获取最可能是官网的网站 :param resultDic: 各个网站相似度值 :return: 最可能的网站 也可能为空 """ website = '' largest = max(zip(resultDic.values(), resultDic.keys())) if largest[0]: website = largest[1] # 当相似度为0 else: websites = [key for key, values in resultDic.items() if values == 0.0] for eachWebsite in websites: keyword = ','.join(self.data[eachWebsite]).lower() if 'home' in keyword or "welcome" in keyword: website = eachWebsite return website3.总结
至此,若有更好的解决方案,欢迎赐教,谢谢。
作者:howie6879
链接:https://www.jianshu.com/p/d1cf6c6df6bb





