
年前写过一篇爬网易云音乐评论的文章,爬不了多久又回被封,所以爬下来那么点根本做不了什么分析,后面就再改了下,加入了多线程,一次性爬一个歌手最热门50首歌曲的评论,算是进阶版了~
思路梳理
进入歌手页可以看到展示了该歌手的「热门50单曲」,通过BeautifulSoup获取到song_id和song_name;
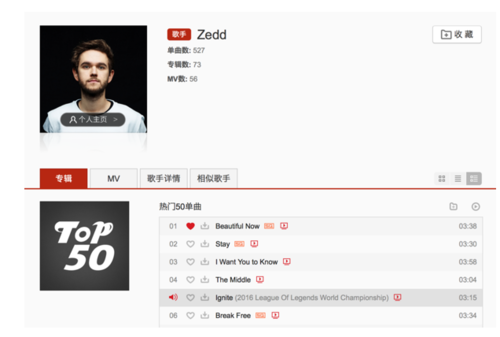
image.png
Notes:
不过这里有一点需要注意,一般像平常我都会选择request或者urllib获取到页面代码,然后通过BeautifulSoup提取我们需要的数据,但去尝试了之后发现歌曲id等都是动态加载的,而像request请求操作都是瞬间完成,并不会等待页面完成加载了再获取页面代码,所以后面便使用了最安全的selenium+BeautifulSoup来获取song_id和song_name。
def get_song_id(url):
driver=webdriver.PhantomJS()
driver.get(url)
time.sleep(2)
driver.switch_to_frame('g_iframe')
time.sleep(5)
web_data = driver.page_source
soup=BeautifulSoup(web_data,'lxml')
top_50_song=soup.find_all('tr', class_='even ')
driver.quit() return top_50_song有了song_id之后就好做了,之前的文章中已经说过了,每个歌曲的评论是通过一个包含song_id的地址传递的,然后加入多线程分别保存50首歌曲,然后等着被封或者完成就好了
def save_comment(song_id,song_name):
url_comment = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_'+str(song_id)+'?csrf_token='
page = get_page(url_comment,song_name) if page == 0: print 'IP地址被封,请稍后再试!!!'
else:
for i in range(page): try:
params = get_params(i);
encSecKey = get_encSecKey();
json_text = get_json(url_comment, params, encSecKey)
json_dict = json.loads(str(json_text))['comments'] for t in list(range(len(json_dict))): if t == 0:
rdata=pd.DataFrame(pd.Series(data=json_dict[t])).T else:
rdata=pd.concat([rdata,pd.DataFrame(pd.Series(data=json_dict[t])).T]) if i == 0:
commentdata=rdata else:
commentdata=pd.concat([commentdata,rdata]) print '***正在保存>>%s<<第%d页***'%(song_name.encode('utf-8'),i+1)
time.sleep(random.uniform(0.2,0.5))
path = song_name.encode('utf-8')+'.xlsx'
except Exception, e: print 'IP地址被封,%s未保存完全!!!'%song_name.encode('utf-8')
commentdata.to_excel(path)其他部分在上篇文章已经说过了,包括加密部分,可移步
Python爬虫爬取网易云音乐全部评论查看。
完整代码:
# -*- coding: utf-8 -*-#date : 2018-02-28#author : Awesome_Tang#version : Python 2.7.9'''
网易云音乐评论爬虫
'''from Crypto.Cipher import AESimport base64import requestsimport jsonimport timeimport pandas as pdimport randomfrom threading import Threadfrom bs4 import BeautifulSoup
from selenium import webdriverimport threading
headers = { 'Referer': 'http://music.163.com/song?id=531051217', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', 'Cookie': 'JSESSIONID-WYYY=%5CuiUi%5C%2FYs%2FcJcoQ5xd3cBhaHw0rEfHkss1s%2FCfr92IKyg2hJOrJquv3fiG2%2Fn9GZS%2FuDH8PY81zGquF4GIAVB9eYSdKJM1W6E2i1KFg9%5CuZ4xU6VdPCGwp4KOUZQQiWSlRT%2F1r07OmIBn7yYVYN%2BM2MAalUQnoYcyskaXN%5CPo1AOyVVV%3A1516866368046; _iuqxldmzr_=32; _ntes_nnid=7e2e27f69781e78f2c610fa92434946b,1516864568068; _ntes_nuid=7e2e27f69781e78f2c610fa92434946b; __utma=94650624.470888446.1516864569.1516864569.1516864569.1; __utmc=94650624; __utmz=94650624.1516864569.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmb=94650624.8.10.1516864569'}
proxies = { "https": "218.94.255.11:8118", "http": "110.73.43.110:8123",}
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'second_param = "010001"third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"forth_param = "0CoJUm6Qyw8W8jud"def get_params(i):
if i == 0:
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
else:
offset =str(i*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}'%(offset,'flase')
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv) return h_encTextdef get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text) return encrypt_textdef get_json(url, params, encSecKey):
data = { "params": params, "encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data,proxies = proxies ,timeout =5) return response.contentdef get_page(url,song_name):
params = get_params(0);
encSecKey = get_encSecKey();
json_text = get_json(url, params, encSecKey)
json_dict = json.loads(json_text) try:
total_comment = json_dict['total']
page=(total_comment/20)+1
print '***查询到歌曲>>>%s<<<评论共计%d条,%d页***'%(song_name.encode('utf-8'),total_comment,page) return page except Exception, e: return 0def save_comment(song_id,song_name):
url_comment = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_'+str(song_id)+'?csrf_token='
page = get_page(url_comment,song_name) if page == 0: print 'IP地址被封,请稍后再试!!!'
else:
for i in range(page): try:
params = get_params(i);
encSecKey = get_encSecKey();
json_text = get_json(url_comment, params, encSecKey)
json_dict = json.loads(str(json_text))['comments'] for t in list(range(len(json_dict))): if t == 0:
rdata=pd.DataFrame(pd.Series(data=json_dict[t])).T else:
rdata=pd.concat([rdata,pd.DataFrame(pd.Series(data=json_dict[t])).T]) if i == 0:
commentdata=rdata else:
commentdata=pd.concat([commentdata,rdata]) print '***正在保存>>%s<<第%d页***'%(song_name.encode('utf-8'),i+1)
time.sleep(random.uniform(0.2,0.5))
path = song_name.encode('utf-8')+'.xlsx'
except Exception, e: print 'IP地址被封,%s未保存完全!!!'%song_name.encode('utf-8')
commentdata.to_excel(path)
def get_song_id(url):
driver=webdriver.PhantomJS(executable_path='/Users/XXXXX/phantomjs-2.1.1-macosx/bin/phantomjs')
driver.get(url)
time.sleep(2)
driver.switch_to_frame('g_iframe')
time.sleep(5)
web_data = driver.page_source
soup=BeautifulSoup(web_data,'lxml')
top_50_song=soup.find_all('tr', class_='even ')
driver.quit() return top_50_songif __name__ == "__main__":
start_time = time.time()
url_artist = 'http://music.163.com/#/artist?id=46376'
top_50_song = get_song_id(url_artist)
thread_list = [] for song in top_50_song:
song_id = song.select('td.w1 div span.ply ')[0].get('data-res-id')
song_name = song.select('span.txt b')[0].get('title').replace(u'\xa0',u' ')
my_thread = threading.Thread(target=save_comment, args=(str(song_id),song_name))
my_thread.setDaemon(True)
thread_list.append(my_thread) for my_thread in thread_list:
my_thread.start() for my_thread in thread_list:
my_thread.join()
end_time = time.time() print "程序耗时%f秒." % (end_time - start_time) print '***NetEase_Music_Spider@Awesome_Tang***'Peace~
作者:Awesome_Tang
链接:https://www.jianshu.com/p/867c5df661cc





