
研究 Spring 源码的小伙伴可能会发现,Spring 源码中有很多名称特别相近的 Bean,我就不挨个举例了,今天我是想和小伙伴们聊一聊 Spring 中 BeanFactoryPostProcessor 和 BeanPostProcessor 两个处理器的区别。
我将从以下几个方面来和小伙伴们分享。
1. 区别
这两个接口说白了都是 Spring 在初始化 Bean 时对外暴露的扩展点,因为 Spring 框架提供的功能不一定能够满足我们所有的需求,有的时候我们需要对其进行扩展,那么这两个接口就是用来做扩展功能的。
其实不用看源码,单纯从字面上看,大家应该也能理解个差不多:
- BeanFactoryPostProcessor 是针对 BeanFactory 的处理器。
- BeanPostProcessor 则是针对 Bean 的处理器。
我们先来看下 BeanFactoryPostProcessor 接口:
@FunctionalInterface
public interface BeanFactoryPostProcessor {
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}
可以看到,这里的参数实际上就是一个 BeanFactory,在这个地方,我们可以对 BeanFactory 进行修改,重新进行定制。例如可以修改一个 Bean 的作用域,可以修改属性值等。
再来看看 BeanPostProcessor 接口:
public interface BeanPostProcessor {
@Nullable
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
@Nullable
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}
可以看到,这里是两个方法,这两个方法都有一个 bean 对象,说明这里被触发的时候,Spring 已经将 Bean 初始化了,然后才会触发这里的两个方法,我们可以在这里对已经到手的 Bean 进行额外的处理。其中:
- postProcessBeforeInitialization:这个方法在
InitializingBean#afterPropertiesSet和init-method方法之前被触发。 - postProcessAfterInitialization:这个方法在
InitializingBean#afterPropertiesSet和init-method方法之后被触发。
总结一下:
在 Spring 中,BeanFactoryPostProcessor 和 BeanPostProcessor 是两个不同的接口,它们在 Bean 的生命周期中扮演不同的角色。
- BeanFactoryPostProcessor 接口用于在 Bean 工厂实例化 Bean 之前对 Bean 的定义进行修改。它可以读取和修改 Bean 的定义元数据,例如修改 Bean 的属性值、添加额外的配置信息等。BeanFactoryPostProcessor 在 Bean 实例化之前执行,用于对 Bean 的定义进行预处理。
- BeanPostProcessor 接口用于在 Bean 实例化后对 Bean 进行增强或修改。它可以在 Bean 的初始化过程中对 Bean 进行后处理,例如对 Bean 进行代理、添加额外的功能等。BeanPostProcessor 在 Bean 实例化完成后执行,用于对 Bean 实例进行后处理。
一言以蔽之,BeanFactoryPostProcessor 主要用于修改 Bean 的定义,而 BeanPostProcessor 主要用于增强或修改 Bean 的实例。
2. 代码实践
2.1 BeanFactoryPostProcessor
BeanFactoryPostProcessor 在 Spring 容器中有一个非常典型的应用。
当我们在 Spring 容器中配置数据源的时候,一般都是按照下面这样的方式进行配置的。
首先创建 db.properties,将数据源各种信息写入进去:
db.username=root
db.password=123
db.url=jdbc:mysql:///db01?serverTimezone=Asia/Shanghai
然后在 Spring 的配置文件中,首先把这个配置文件加载进来,然后就可以在 Spring Bean 中去使用对应的值了,如下:
<context:property-placeholder location="classpath:db.properties"/>
<bean class="com.alibaba.druid.pool.DruidDataSource" id="dataSource">
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
<property name="url" value="${db.url}"/>
</bean>
但是大家知道,对于 DruidDataSource 来说,毫无疑问,它要的是具体的 username、password 以及 url,而上面的配置很明显中间还有一个转换的过程,即把 ${db.username}、${db.password} 以及 ${db.url} 转为具体对应的值。那么这个转换是怎么实现的呢?
这就得分析 <context:property-placeholder location="classpath:db.properties"/> 配置了,小伙伴们知道,这个配置实际上是一个简化的配置,点击去可以看到真正配置的 Bean 是 PropertySourcesPlaceholderConfigurer,而 PropertySourcesPlaceholderConfigurer 恰好就是 BeanFactoryPostProcessor 的子类,我们来看下这里是如何重写 postProcessBeanFactory 方法的:
源码比较长,松哥这里把一些关键部分列出来和小伙伴们展示:
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
if (this.propertySources == null) {
//这里主要是如果没有加载到 properties 文件,就会尝试从环境中加载
}
//这个就是具体的属性转换的方法了
processProperties(beanFactory, new PropertySourcesPropertyResolver(this.propertySources));
this.appliedPropertySources = this.propertySources;
}
/**
* 这个属性转换方法中,对配置文件又做了一些预处理,最后调用 doProcessProperties 方法处理属性
*/
protected void processProperties(ConfigurableListableBeanFactory beanFactoryToProcess,
final ConfigurablePropertyResolver propertyResolver) throws BeansException {
propertyResolver.setPlaceholderPrefix(this.placeholderPrefix);
propertyResolver.setPlaceholderSuffix(this.placeholderSuffix);
propertyResolver.setValueSeparator(this.valueSeparator);
StringValueResolver valueResolver = strVal -> {
String resolved = (this.ignoreUnresolvablePlaceholders ?
propertyResolver.resolvePlaceholders(strVal) :
propertyResolver.resolveRequiredPlaceholders(strVal));
if (this.trimValues) {
resolved = resolved.trim();
}
return (resolved.equals(this.nullValue) ? null : resolved);
};
doProcessProperties(beanFactoryToProcess, valueResolver);
}
protected void doProcessProperties(ConfigurableListableBeanFactory beanFactoryToProcess,
StringValueResolver valueResolver) {
BeanDefinitionVisitor visitor = new BeanDefinitionVisitor(valueResolver);
String[] beanNames = beanFactoryToProcess.getBeanDefinitionNames();
for (String curName : beanNames) {
// Check that we're not parsing our own bean definition,
// to avoid failing on unresolvable placeholders in properties file locations.
if (!(curName.equals(this.beanName) && beanFactoryToProcess.equals(this.beanFactory))) {
BeanDefinition bd = beanFactoryToProcess.getBeanDefinition(curName);
try {
visitor.visitBeanDefinition(bd);
}
catch (Exception ex) {
throw new BeanDefinitionStoreException(bd.getResourceDescription(), curName, ex.getMessage(), ex);
}
}
}
// New in Spring 2.5: resolve placeholders in alias target names and aliases as well.
beanFactoryToProcess.resolveAliases(valueResolver);
// New in Spring 3.0: resolve placeholders in embedded values such as annotation attributes.
beanFactoryToProcess.addEmbeddedValueResolver(valueResolver);
}
上面第三个 doProcessProperties 方法我要稍微和小伙伴们说两句:
使用 PropertySourcesPlaceholderConfigurer 对配置中的占位符进行处理,虽然我们只是在 DruidDataSource 中用到了相关变量,但是系统在处理的时候,除了当前这个配置类之外,其他的 Bean 都要处理(因为你可以在任意 Bean 中注入那三个变量)。
这就是 BeanFactoryPostProcessor 一个经典实践,即在 Bean 初始化之前,把 Bean 定义时候的一些占位符给改过来。
2.2 照猫画虎
上面的源码看完了,如果小伙伴们还觉得不过瘾,我们自己也来写一个试试。
我自己的需求是这样,假设我配置 Bean 的时候,按照下面这种方式来配置:
<bean class="org.javaboy.bean.User">
<property name="username" value="^username"/>
</bean>
这里的 ^username 是我自定义的一个特殊的占位符,这个占位符表示 javaboy,我希望最终从 Spring 容器中拿到的 User Bean 的 username 属性值是 javaboy。
为了实现这个需求,我可以自定义一个 BeanFactoryPostProcessor,如下:
public class MyPropBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
String[] beanDefinitionNames = beanFactory.getBeanDefinitionNames();
for (String beanDefinitionName : beanDefinitionNames) {
BeanDefinition beanDefinition = beanFactory.getBeanDefinition(beanDefinitionName);
BeanDefinitionVisitor beanDefinitionVisitor = new BeanDefinitionVisitor(strVal -> {
if ("^username".equals(strVal)) {
return "javaboy666";
}
return strVal;
});
beanDefinitionVisitor.visitBeanDefinition(beanDefinition);
}
}
}
这个 Bean 基本上是照着前面 2.1 小节的 Bean 来写的。我跟大家来大致说一下我的逻辑:
- 首先获取到所有的 Bean 定义对象,然后进行遍历。
- 遍历的时候创建一个 BeanDefinitionVisitor 对象,这个对象需要一个字符解析器,也就是 lambda 表达式那一段,我这里就是说,如果传进来的字符串是
^username,那么我就返回 javaboy,如果传进来其他值,那我原封不动,不做修改。 - 最后调用 visitBeanDefinition 方法去重新设置一下 Bean 的定义。
上面这几行代码基本上就是照着 2.1 小节敲的,最后,我们把 MyPropBeanFactoryPostProcessor 注册到 Spring 容器中就行了:
<bean class="org.javaboy.bean.User">
<property name="username" value="^username"/>
</bean>
<bean class="org.javaboy.bean.MyPropBeanFactoryPostProcessor"/>
看下执行效果:

2.3 BeanPostProcessor
BeanPostProcessor 主要是对一个已经初始化的 Bean 做一些额外的配置,这个接口中包含两个方法,执行时间如下图:
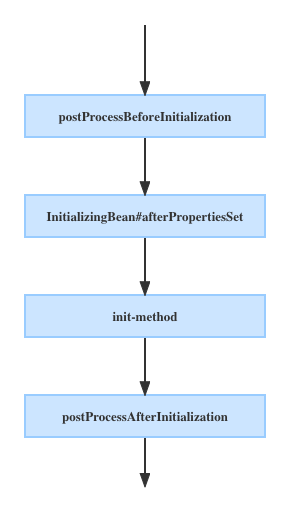
我写一个简单例子我们来验证下:
public class UserService implements InitializingBean {
public UserService() {
System.out.println("UserService>Constructor");
}
public void init() {
System.out.println("UserService>init");
}
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("UserService>afterPropertiesSet");
}
}
再开发一个 BeanPostProcessor:
public class MyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("postProcessBeforeInitialization:beanName"+beanName+";beanClass:"+bean.getClass());
return BeanPostProcessor.super.postProcessBeforeInitialization(bean, beanName);
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("postProcessAfterInitialization:beanName"+beanName+";beanClass:"+bean.getClass());
return BeanPostProcessor.super.postProcessAfterInitialization(bean, beanName);
}
}
然后我们将这两个 Bean 都注册到 Spring 容器中:
<bean class="org.javaboy.bean.MyBeanPostProcessor"/>
<bean class="org.javaboy.bean.UserService" id="us" init-method="init">
</bean>
最后启动容器,来看下控制台打印的内容:

可以看到,跟我们所预想的是一样的。在 MyBeanPostProcessor 中,第一个参数其实就是已经初始化的 Bean 了,如果想在这里针对 Bean 做任何修改都是可以的。
2.4 典型应用
BeanPostProcessor 其实有很多经典的应用,我在写文章的时候,想到一个地方,就是我们在 SpringMVC 中做数据验证的时候,往往只需要加几个注解就可以了(对此不熟悉的小伙伴可以在公众号后台回复 ssm 有松哥录制的 ssm 入门视频),那么这个注解是在哪里进行的校验的呢?就是 BeanPostProcessor,我们来看一眼源码:
public class BeanValidationPostProcessor implements BeanPostProcessor, InitializingBean {
@Nullable
private Validator validator;
private boolean afterInitialization = false;
public void setAfterInitialization(boolean afterInitialization) {
this.afterInitialization = afterInitialization;
}
@Override
public void afterPropertiesSet() {
if (this.validator == null) {
this.validator = Validation.buildDefaultValidatorFactory().getValidator();
}
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (!this.afterInitialization) {
doValidate(bean);
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (this.afterInitialization) {
doValidate(bean);
}
return bean;
}
/**
* Perform validation of the given bean.
* @param bean the bean instance to validate
* @see jakarta.validation.Validator#validate
*/
protected void doValidate(Object bean) {
//...
}
}
这段代码其实很好懂,可以看到,我们可以控制是在具体是在 postProcessBeforeInitialization 还是 postProcessAfterInitialization 方法中进行数据校验。
好了,现在小伙伴们应该搞懂 BeanFactoryPostProcessor 和 BeanPostProcessor 的区别了吧?
3. 小结
我再把前文的小结内容拿过来,小伙伴们现在看是不是更清晰了?
在 Spring 中,BeanFactoryPostProcessor 和 BeanPostProcessor 是两个不同的接口,它们在 Bean 的生命周期中扮演不同的角色。
- BeanFactoryPostProcessor 接口用于在 Bean 工厂实例化 Bean 之前对 Bean 的定义进行修改。它可以读取和修改 Bean 的定义元数据,例如修改 Bean 的属性值、添加额外的配置信息等。BeanFactoryPostProcessor 在 Bean 实例化之前执行,用于对 Bean 的定义进行预处理。
- BeanPostProcessor 接口用于在 Bean 实例化后对 Bean 进行增强或修改。它可以在 Bean 的初始化过程中对 Bean 进行后处理,例如对 Bean 进行代理、添加额外的功能等。BeanPostProcessor 在 Bean 实例化完成后执行,用于对 Bean 实例进行后处理。
一言以蔽之,BeanFactoryPostProcessor 主要用于修改 Bean 的定义,而 BeanPostProcessor 主要用于增强或修改 Bean 的实例。




