
谷歌的开源框架 tesseract-ocr可以帮助我们进行识别图像,文字等等,tesseract可以识别多种语言(一些常用的语言),多种图片格式,非常强大。
首先体验一下tesseract的强大功能,先安装 tesseract_ocr ,下载地址为http://code.google.com/p/tesseract-ocr/,请务必下载3.0.1版本,我前面下的最新3.0.2版本,生成字符特征命令不能通过,最后勉强解决了,生成的字典识别出来的都是空字符
安装完成之后 看下根目录
tessdata文件夹主要存放字典文件,只要把字典文件放进去,就可以用tesseract 识别相关语言的文字
现在先来识别一张图片

把他放入任意一个文件夹,cmd 命令cd到图片放置的目录,然后执行
[code]
[html] view plain copy print?
tesseract 1.jpg 1
tesseract 1.jpg 1



可以看到文件夹下 生成了一个txt文本,发现识别的效果并不是很理想。为啥呢,因为我所用的这个图片中的字有所变形,我们的图片和 tesseract 存在的 字做匹配,找相近的,但是字典中没有这种变形的字体,自然识别容易出错,为了 提高识别率,所以我们需要 训练一套 字体来提高识别率
训练 字库还需要一个工具jTessBoxEditor,下载地址为 http://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
现在我们来实战一下,首先要生成一个 .tif 的图片集,我们使用 jTessBoxEditor 来合并多张 格式为tif的图片
1、打开 jTessBoxEditor,选择tools->merge tif ,选择 tif图片,生成一个 格式为tif的 图片集


2、我生成一个名为 why4.tif 的图片集, 进入 cd进入 why4.tif 所在的目录,生成对应的 .box 文件
执行命令
tesseract why.tif why4 batch.nochop makebox
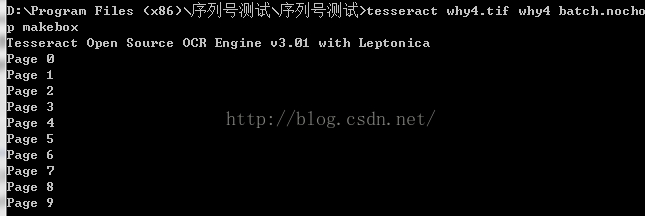
这个文件是通过 tesseract 识别出来的,标示了图片集中 文字的位置,大小,识别后的字符结果。
3、调整,因为 tesseract 识别的不准确,所以我们用 jTessBoxEditor来调整识别文字的位置、结果。
用 jTessBoxEditor打开生成的图片集why4.tif ,注意 why4.tif 对应的box文件一定要和他处于同一个文件夹下(请保持文件名),否则,用jTessBoxEditor打开没有 位置、识别结果等信息,然后就可以调整了,调整完之后保存

4、生成.tr文件
tesseract why4.tif why4 nobatch box.train

5、计算字符集,从生成的 box文件中提取
unicharset_extractor why4.box
6、生成字体特征文件,现在文件夹下新建文件名为“"font_properties.txt"” 特征文件,里面的内容格式为
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname为字体名称,保持和 图片集文件 .tif 和.box文件的前缀名一致 ,italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
例如我新建了一个 名为 font,内容 为
why4 0 0 0 0 0
的文件
输入命令
mftraining -F font_properties.txt -U unicharset why4.tr
7 、聚集tesseract 识别的训练文件
cntraining why4.tr
执行完这一步之后发现文件夹下生产了许多文件,把unicharset, inttemp, normproto, pffmtable, shapetable这几个文件加上前缀 why4.
8、最后一步,合并相关文件,生成字典文件
combine_tessdata why4.

好了,至此字典文件就生产了,我们把生成的字典文件why4.traineddata放入到 tesseract_ocr 根目录下的 tessdata文件夹下
开始使用我们训练过得字体库
随便找一张图片测试一下
tesseract 13.jpg 13 -l why4
tesseract 13.jpg 13 -l why4

可以看到,效果好了许多
说了这么多,生成一个字库还是挺麻烦的,尤其是调整,看得我眼睛都花了,心情烦躁,好不容易做好了一个字库,但是不够 ,还要多添加一些训练内容进去该怎么办呢,经过我的研究,终于找到了3.0.1版本合并字库的方法
首先,需要 生成的字符集.tif文件,位置文件 .box ,只要有这两个文件在,就可以合并字典
好了,我现在有三个 需要合并的字典 why3 why4 why5,他他们的名字修改为 name.num 的形式,分别改为 why.3 why.4 why.5
1、先生成相对应的 .tr 文件
tesseract why.3.tif why.3 nobatch box.train tesseract why.4.tif why.4 nobatch box.train tesseract why.5.tif why.5 nobatch box.train
2、从所有文件中提取字符
unicharset_extractor why.3.box why.4.box why.5.box
unicharset_extractor why.3.box why.4.box why.5.box
3、生成字体特征文件
新建的font文件中 把所有box文件对应的 字体特征都加进去
why.4 0 0 0 0 0 why.3 0 0 0 0 0 why.5 0 0 0 0 0
mftraining -F font -U unicharset why.3.tr why.4.tr why.5.tr
mftraining -F font -U unicharset why.3.tr why.4.tr why.5.tr
4 、聚集所有.tr 文件
cntraining why.3.tr why.4.tr why.5.tr
6 、重命名文件,我把unicharset, inttemp, normproto, pfftable 这几个文件加了前缀why.
7、合并所有文件 生成一个大的字库文件
combine_tessdata why.





