
如果❤️我的文章有帮助,欢迎点赞、关注。这是对我继续技术创作最大的鼓励。[更多系列文章在我博客] coderdao.github.io/
HTTP 协议
作为一个 爬虫工程师,HTTP 几乎是天天要打交道的东西,但我发现大部分人对 HTTP 只是浅尝辄止,对更多的细节及原理就了解不深了,在面试的时候感觉非常吃力。
这篇文章就是为了帮助大家树立完整的 HTTP 知识体系,并达到一定的深度,从容地应对各种开发、面试问题。
GET/POST 区别?
- 从
缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。 - 从
编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。 - 从
参数的角度,GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。 - 从
幂等性的角度,GET是幂等的,而POST不是。(幂等使用同样的条件,一次请求和重复请求对同一系统的资源影响是一致) - 从
TCP的角度,GET 请求会把请求报文一次性发出去,而 POST 会分为两个 TCP 数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。(火狐浏览器除外,它的 POST 请求只发一个 TCP 包)
除 GET、POST 意外,http/1.1 规定了以下请求方法:
- GET: 通常用来获取资源
- HEAD: 获取资源的元信息
- POST: 提交数据,即上传数据
- PUT: 修改数据
- DELETE: 删除资源(几乎用不到)
- CONNECT: 建立连接隧道,用于代理服务器
- OPTIONS: 列出可对资源实行的请求方法,用来跨域请求
- TRACE: 追踪请求-响应的传输路径
HTTP 1.0、1.1、2.0 区别
HTTP 1.0:
总结:
- 无连接
- 无状态
最早在1996年在网页中使用,内容简单。
浏览器的每次请求都需要与服务器建立一个TCP连接,服务器处理完成后立即断开TCP连接(无连接),服务器不跟踪每个客户端也不记录过去的请求(无状态)。
HTTP 1.1:
总结:
- 默认持久连接
- 请求管道化
- 增加缓存处理(新的字段如cache-control)
- 增加Host字段、支持断点传输等(把文件分成几部分)
1999年广泛被应用,HTTP/1.0中默认使用Connection: close。在HTTP/1.1中已经 默认使用Connection: keep-alive(长连接),避免了连接建立和释放的开销。
但服务器须按照客户端请求顺序依次响应结果 ,以保证客户端区分出每次请求的响应内容。通过Content-Length字段来判断当前请求数据是否已经全部接收。不允许同时多个并行响应。
HTTP 2.0:
总结:
- 二进制分帧并行传输
- 多路复用
- 头部压缩
- 服务器推送
HTTP/2引入二进制数据帧和流的概念,其中帧对数据进行顺序标识,如下所示,
- 流(stream)—— 已建立连接上的双向字节流
- 消息 —— 与逻辑消息对应的完整的一系列数据帧
- 帧 —— HTTP2.0通信的最小单位,每个帧包含帧头部,至少也会标识出当前帧所属的流(stream id)。
每个请求是一个数据流,数据流以消息的方式发送,而消息又分为多个帧,帧头部记录着stream id用来标识所属的数据流,不同属的帧可以在连接中随机混杂在一起。接收方可以根据stream id将帧再归属到各自不同的请求当中去。
多路复用:
1、所有的HTTP2.0通信都在一个TCP连接上完成,这个连接可以承载任意数量的双向数据流。
2、每个数据流以消息的形式发送,而消息由一或多个帧组成。这些帧可以乱序发送,然后再根据每个帧头部的流标识符(stream id)重新组装。
举个例子,每个请求是一个数据流,数据流以消息的方式发送,而消息又分为多个帧,帧头部记录着stream id用来标识所属的数据流,不同属的帧可以在连接中随机混杂在一起。接收方可以根据stream id将帧再归属到各自不同的请求当中去。
3、另外,多路复用(连接共享)可能会导致关键请求被阻塞。HTTP2.0里每个数据流都可以设置优先级和依赖,优先级高的数据流会被服务器优先处理和返回给客户端,数据流还可以依赖其他的子数据流。
4、可见,HTTP2.0实现了真正的并行传输,它能够在一个TCP上进行任意数量HTTP请求。而这个强大的功能则是基于“二进制分帧”的特性。
头部压缩
在HTTP1.x中,头部元数据都是以纯文本的形式发送的,通常会给每个请求增加500~800字节的负荷。
HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。高效的压缩算法可以很大的压缩header,减少发送包的数量从而降低延迟。
服务器推送:
服务器除了对最初请求的响应外,服务器还可以额外的向客户端推送资源,而无需客户端明确的请求。
HTTP 和 HTTPS 的区别
HTTPS 简介
HTTPS 实际为了解决 HTTP为明文发送内容,不利于敏感数据, 而在 HTTP 基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
HTTPS协议的主要作用可以分为两种:
- 一种提供
信息安全通道,保证数据安全传输; - 一种确认网站
真实性。
区别
- https相对于http加入了ssl层,需要到ca申请证书(收费的),
- https相对于http身份认证(认知用户、服务器),数据加密。防止数据被窃取、改变。
- 现行架构下最安全但是耗时多,缓存不是很好,
- https使用 443 端口;http使用 80 端口。注意兼容http和https
HTTPS 传输过程
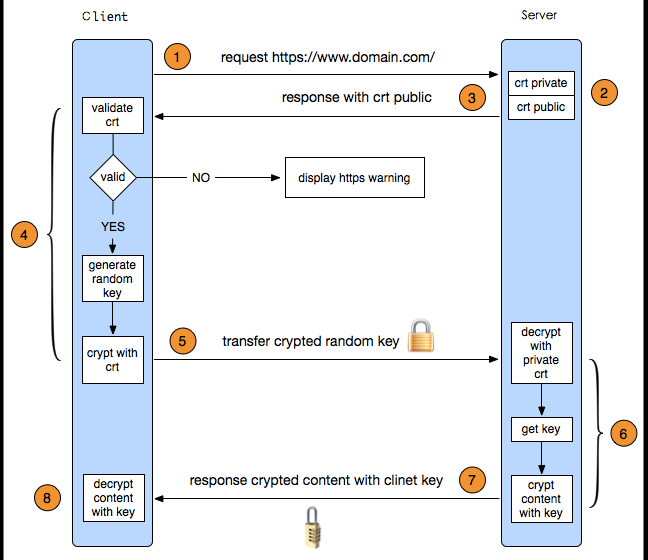
前置条件:
服务端 生成 TSL/SSL 公钥、私钥。把公钥给 CA 签发带有公钥的证书。
- Client发起一个HTTPS请求,根据RFC2818的规定,Client知道需要连接Server的443(默认)端口。
- Server有事先配置好的密钥对(公钥、私钥),这里把公钥证书(public key certificate)返回给客户端。
- Client验证公钥证书:比如是否在有效期内,证书的用途是不是匹配Client请求的站点,是不是在CRL吊销列表里面,它的上一级证书是否有效,这是一个递归的过程,直到验证到根证书(操作系统内置的Root证书或者Client内置的Root证书)。如果验证通过则继续,不通过则显示警告信息。
- Client使用伪随机数生成器生成加密所使用的会话密钥,然后用证书的公钥加密这个会话密钥,发给Server。
- Server使用自己的私钥(private key)解密这个消息,得到会话密钥。至此,Client和Server双方都持有了相同的会话密钥。
- Server使用会话密钥加密“明文内容A”,发送给Client。
- Client使用会话密钥解密响应的密文,得到“明文内容A”。
- Client再次发起HTTPS的请求,使用会话密钥加密请求的“明文内容B”,然后Server使用会话密钥解密密文,得到“明文内容B”。
输入 URL 到页面渲染的过程
总体分 6 步:
- 输入网址
- DNS域名解析
- 建立TCP连接
- 发送HTTP请求,服务器处理请求,返回响应结果
- 关闭TCP连接
- 浏览器渲染
细致问每一步具体做了什么?又有以下答案:
DNS域名解析
本质:把域名 imooc.com 转换成具体 IP地址
应用场景:当爬虫请求数据为空时,可以 ping 一下请求域名。是否能成功。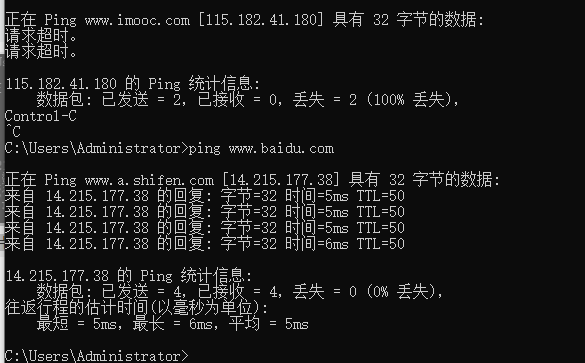
www.baidu.com 是成功例子;www.imooc.com 可能是 禁止ping/ 绑hosts / 网站挂了 等几种情况。这个可以结合 curl / 浏览器访问… 等更多方法结合判断
DNS的解析过程,是在浏览器、本地DNS 之间 递归查询;找不到就继续在 本地DNS 与 根域服务器、顶级域名服务器、权威域名服务器之间 迭代查询;
发送HTTP请求,服务器处理请求,返回响应结果
TCP连接建立后,浏览器就可以利用HTTP/HTTPS协议向服务器发送请求了。
服务器接受到请求,就解析请求头,如果头部有缓存相关信息如if-none-match与if-modified-since,则验证缓存是否有效返回状态码为304,
如果是301/302表示服务器已更换域名需要重定向,这时网络进程会从响应头的Location字段里面读取重定向的地址,然后再发起新的HTTP或者HTTPS请求,跳回第4步。
如果是200,就检查Content-Type字段,值为text/html说明是HTML文档,是application/octet-stream说明是文件下载;





