
>今天说说mybatis,之前说过spring ioc,aop,mvc,接下来就到数据库的持久层了。从上到下的顺序,mvc,ioc,最下面就是数据库的持久层。mybatis是互联网和企业内广为应用的框架。官方参考文档这个文档很详细:www.mybatis.org/mybatis-3/zh/index.html

数据库访问层的4种实现方案对比
JDBC
>当初最早的实现dao层,都是通过jdbc的方式
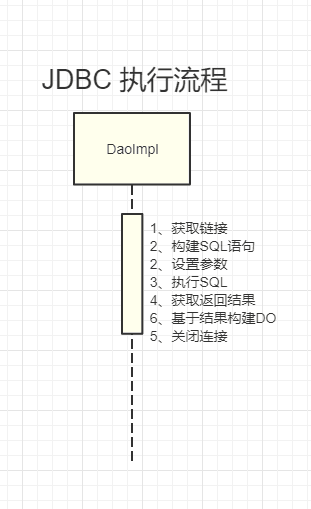
- 获取链接,通过DriverManager.getConnection
- 构建sql语句,可能这个sql语句,增删改查都有可能
- 设置参数,跟jdbc数据库是一一对应的
- 执行sql,通过execute
- 获取返回结果
- 基于结果构建DO
- 关闭链接
> 非常的繁琐,可以基于一个组件,开发一个工具类,获取链接和关闭链接肯定是两个方法,1-7步可以通过代理方法构建。第二步可以通过参数的形式传递给方法。自动帮我们获取链接,设置参数,执行sql。大大简化了我们开发。后来就开始企业开发使用jdbc template。
JdbcTemplate
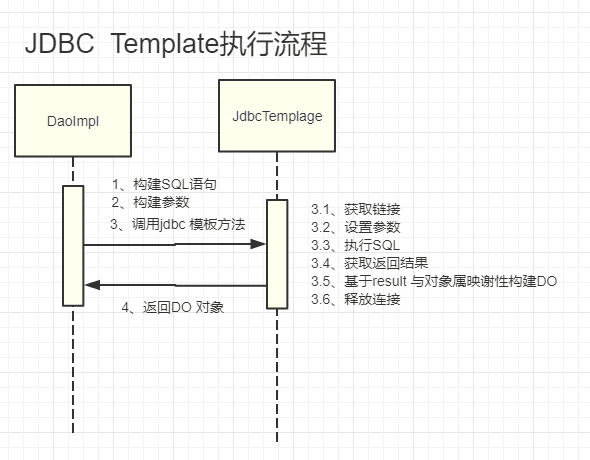
- 构建sql语句
- 构建参数
- 调用jdbc模板方法
3.1 获取链接
3.2 设置参数
3.3 执行sql
3.4 获取返回结果
3.5 基于result对象属性映射构建DO
4 返回DO对象
>虽然JdbcTemplate 简化我们对数据库的操作,但是它有个问题,sql语句都要java类,代码的方式拼接sql,最后导致代码非常的混乱,数据库的类型和java的类型进行映射。写sql语句本身就是很繁琐的事情,ORM的出现对象关系映射,数据库里面的二维和java里面的bean,做一对一的配置。根本就不需要写sql语句了,后来开始普及hibernate。
hibernate
> hibernate 是一个完完整整的ORM框架,包含基本的查询,插入,修改,删除。通过java api的方式进行调用,还包括二级缓存这种附加的,天生支持sql防注入的。
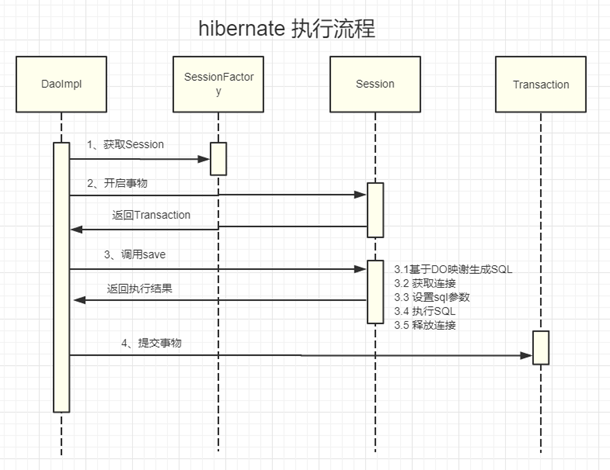
- 获取session
- 开启事务,返回transaction对象
- 调用save,返回执行结果
3.1 配置映射
3.2 预计DO映射生成SQL(底层还是jdbc,就好像我们spring mvc底层还是用的servlet)
3.3 获取链接
3.4 设置sql参数
3.5 执行sql
3.6 释放链接 - 提交事务
>hibernate虽然好,但是也有弊端的,最不方便的地方,状态的把握(游离态,持久化态,瞬态数据态),特别是模型比较复杂的时候什么一对一,一对多,多对一,多对多,很容易绕晕,还有HQL语句,这些语句都是hibernate自己生成的,这样DBA是非常郁闷的,对性能研究把握比较大的,这样会感觉它比较重了。 后来很多人从hibernate转成了JdbcTemplate ,JdbcTemplate 虽然比较繁琐,但是sql语句都是可控的。sql语句的写法完全可以考数据库的经验。
mybatis
- 历史
>Mybaits的前身是Apache的一个开源项目iBatis,2010年这个项目由apache software foundation 迁移到了 google code 并且改名为Mybatis,2013年11月迁移到Github,目前mybaits是由Github维护的。

- 获取session
- 开启事务返回Transaction
- 调用select
3.1 拉取映射配置
3.1.1 基于配置构建configstatement
3.2 执行sql
3.2.1 基于configstatement生成sql
3.2.2 获取链接
3.2.3 设置sql参数
3.2.4 执行sql
3.2.5 释放链接,返回Do对象,返回执行结果
>hiberate都是通过映射自己生成sql语句,mybatis是根据xml,你配置什么sql就执行什么sql,sql语句是可控的,是可以看的到的。出了问题可以通过经验执行sql。
四种的对比
| 分类 | 优点 | 缺点 |
|---|---|---|
| jdbc | 简单、纯粹 | 1、需要手动关闭链接 2、结果集不能自动映谢 |
| jdbcTemplate | 简单、纯粹、自动会话管理、结果集映谢 | 1、手动拼装SQL管理混乱 |
| hirbernate | 编程效率高,无需编写sql。数据库更换成本低、较完善的二级缓存、自动防SQL注入 | 完全掌握的门槛高、性能优化较麻烦、复杂映谢 |
| myBatis | 学习成本低、可以进行更为细致的SQL优化,减少查询字段、统一的SQL管理 | 功能相对简陋、需要手动编写维护SQL、表结构变更之后需要手动维护SQL与映谢(尽可能的多关联查询什么的,都写在业务代码里面,这样可以良好的完成分布式) |
mybatis的定位
>myBatis 专注于sql 本身,其为sql 映谢而非完整的ORM,需要自己编写sql 语句,这是其优点也是缺点。优点是:优化方便,可更好利用sql编写经验。缺点是当数据修改之后调整麻烦耗费时间长.
>试用场景:适用于对性能要求较高,有大批量的查询修改,并且业务实现没有过多依懒数据关系模型,比如:电商、O2O等互联网项目。
>互联网项目对DAO层的要求:
1.对数据库的访问更新纯粹
2.尽可能不要使用数据库做运算
3.SQL语句可以针对性的优化(减少查询字段、查条件排序例 、查询条件尽可能命中索引)
myBatis 体系结构图
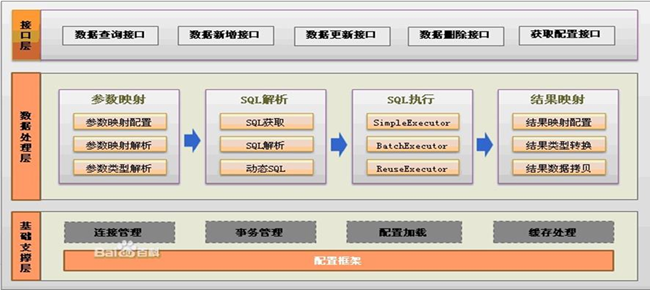
myBatis 应用知识结构图
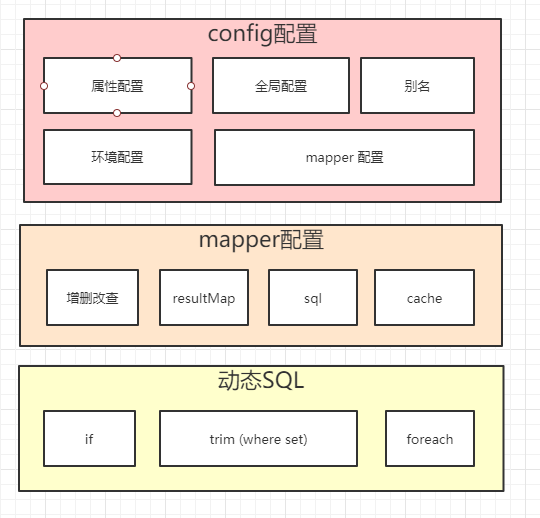
- Config
> 属性配置
> 三种设置方式:
1.构建sessionFactory 时传递 (优先级:高)
2.基于resource 属性加载 或 url 加载 (优先级:中)
3.基于 属性设置 (优先级:低)
>全局参数配置
具体参考:http://www.mybatis.org/mybatis-3/zh/configuration.html#settings
>环境配置
> 数据源:
unpooled 普通连接,每次获取时都会重新建立一个新的连接.属性下如下:
• driver :数据库驱动类
• url: URL地址
• username:用户名。
• password :登录数据库的密码。
pooled: 连接池模式,所有连接从连接池当中获取,由连接池来来进行连接的建立与回收关于等操作,除支持unpooled属性外还支持属性如下:
• poolMaximumActiveConnections : 最大活跃数,默认值:10
• poolMaximumIdleConnections :最大空闲连接数
• poolMaximumCheckoutTime :获取连接超时等待最大(checked out)时间,默认值:20000 毫秒
• poolTimeToWait : 单次获取连接 最大等待时间 默认:20000 毫秒(即 20 秒)。
• poolMaximumLocalBadConnectionTolerance 获取连接重试次数 默认:3
• poolPingQuery 用于检测连接是否断开的测试 语句
• poolPingEnabled 是否通过执行poolPingQuery 语句做检测,默认值:false。
• poolPingConnectionsNotUsedFor 连接检测间隔时间 ,默认60000。
>typeAliases 别名配置
- mappers 文件引入
>基于 mapper 引入指定资源文件: resource| url |class
基于package 引入:扫描指定包路径当下的url
>mapper 映谢文件配置
mapper 常用元素
• select – 映射查询语
• insert – 映射插入语句
• update – 映射更新语句
• sql – 可被其他语句引用的可重用语句块。
• delete – 映射删除语句
• resultMap 用来描述如何从数据库结果集中来加载对象。
• cache – 给定命名空间的缓存配置。
• cache-ref – 其他命名空间缓存配置的引用。
>select 查询标签
select * from user_info where id = #{id}
其支持属性如下:
参数的引用的办法
#{id, mode=in, jdbcType=INT, jdbcTypeName=MY_TYPE}
>insert update delete 标签
INSERT INTO user_info (user_name,nick_name,password) VALUES
(#{userName},#{nickName},#{password})
update user_info set user_name=#{userName} where id=#{id}
DELETE from user_info where id=#{id}
> 标签
将重复的sql 语句定文为一个字段
id,user_name,nick_name
可通过 进行引入 如:
>resultMap
resultMap 是myBatis 对象的映谢
- 动态SQL配置
标签
trim (where, set) 标签
foreach 标签
PS:其实mybatis,我比较习惯自动生成对应的xml,里面只有简单的增删查改,所有的业务逻辑不在表里面进行处理包括关联查询,都在service里面处理,然后new 新的vo 展示就可以了,这样把压力都给程序来完成,数据库更单纯一些。





