


Kubernetes调度程序负责确定您的Pod在集群中的部署位置。这听起来很简单,但是实际上却相当复杂!
调度器的工作原理
这里我们就一起来理解一下调度器是如何工作的吧。

每次创建Pod时,它会被添加到调度器(Scheduler)队列中。调度程序通过两个阶段逐个处理Pod:
- 调度阶段(scheduling phase) - 我应该选择哪个节点?
- 绑定阶段(binding phase) - 让我们将这个Pod所属节点的信息写入数据库
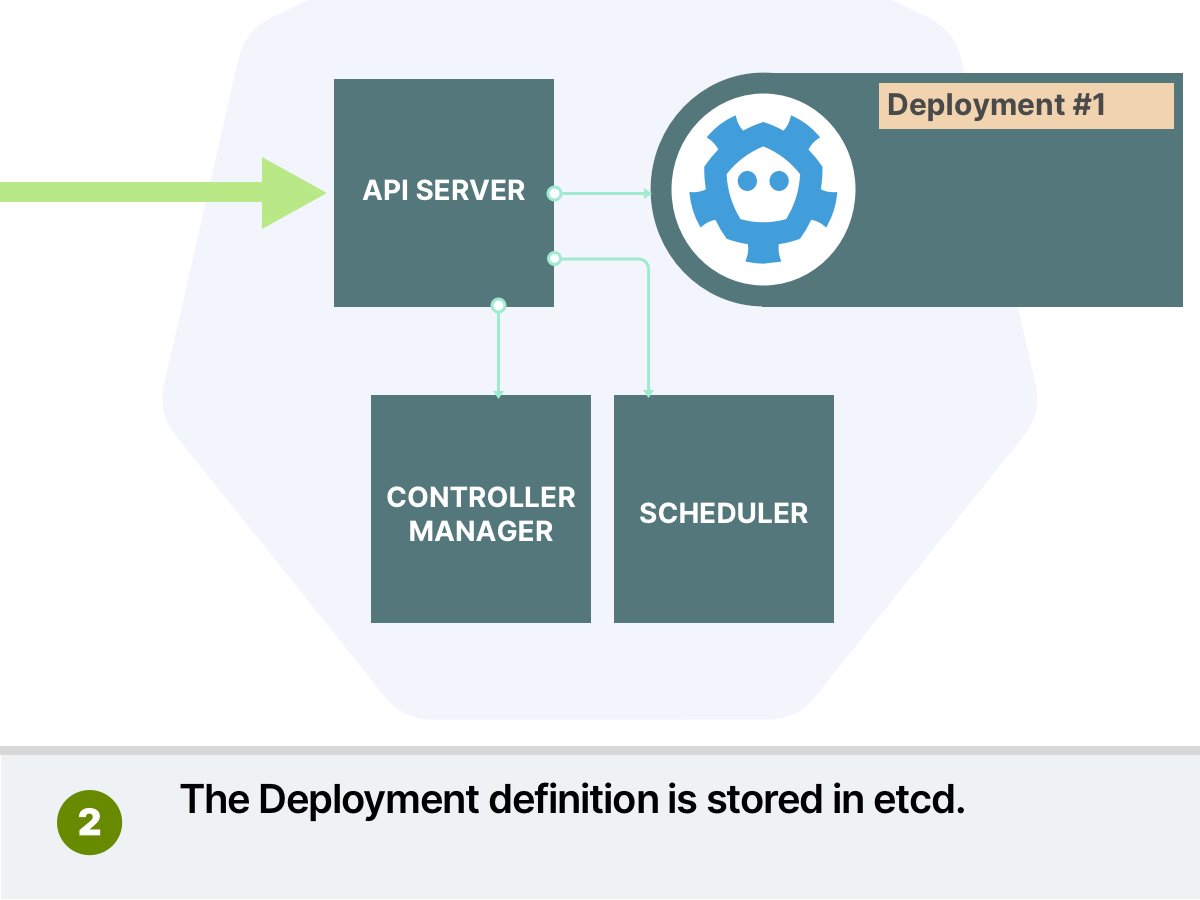
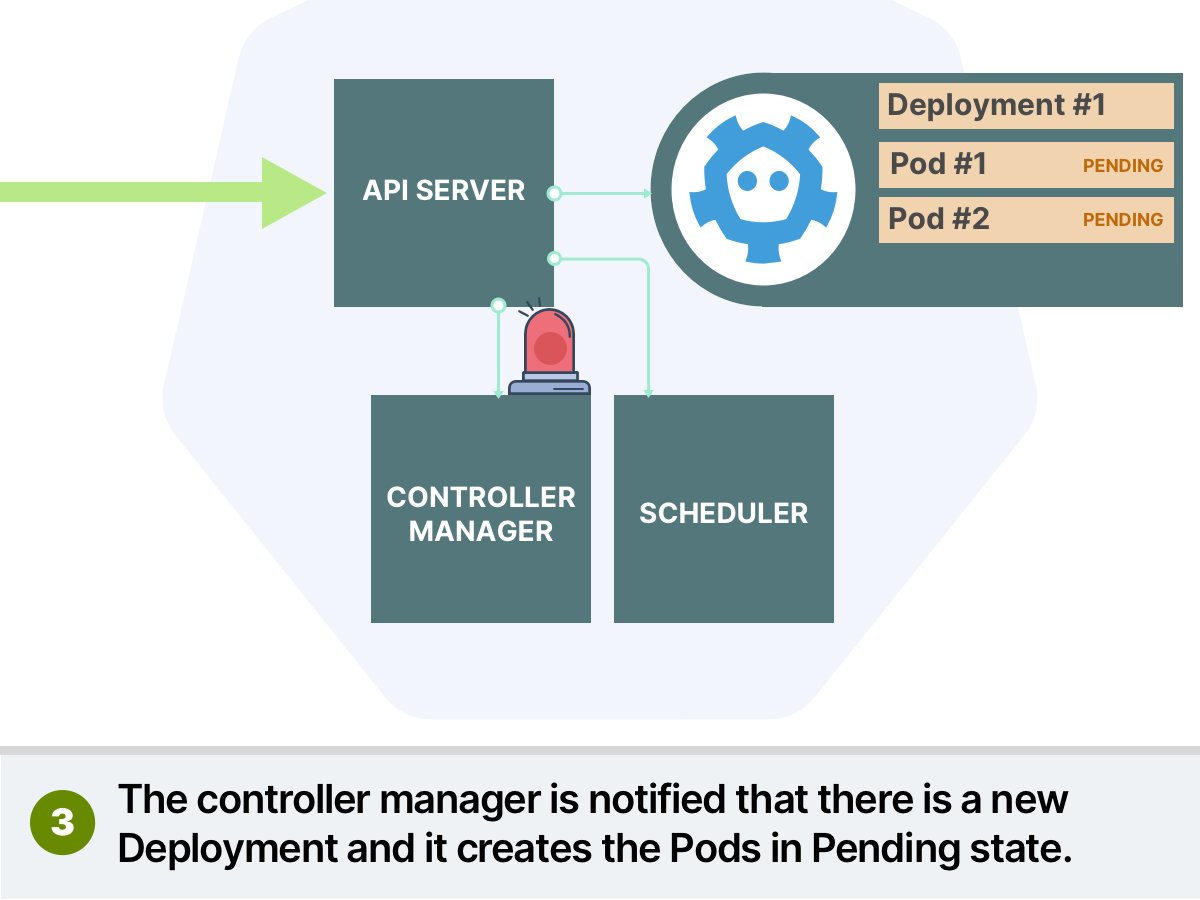

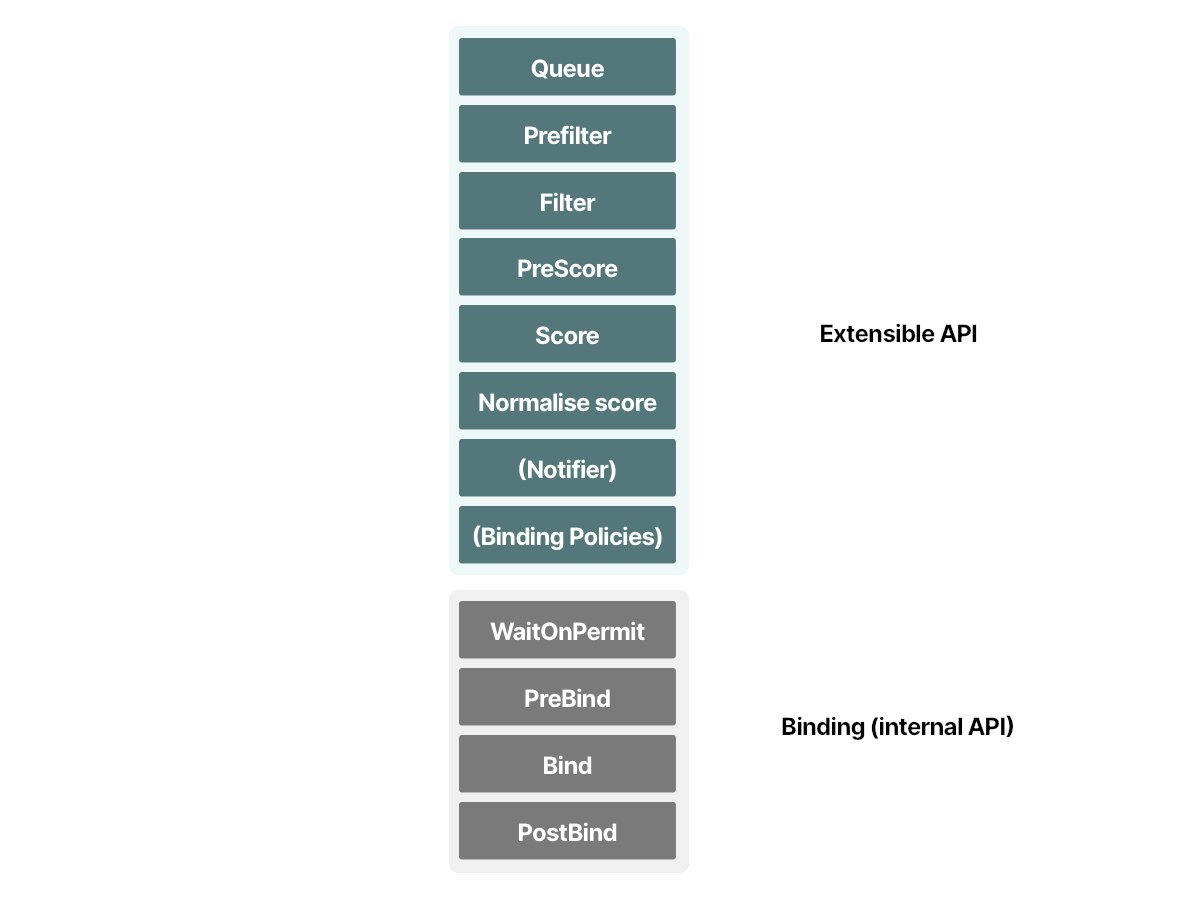
调度阶段也分为两部分。调度器:
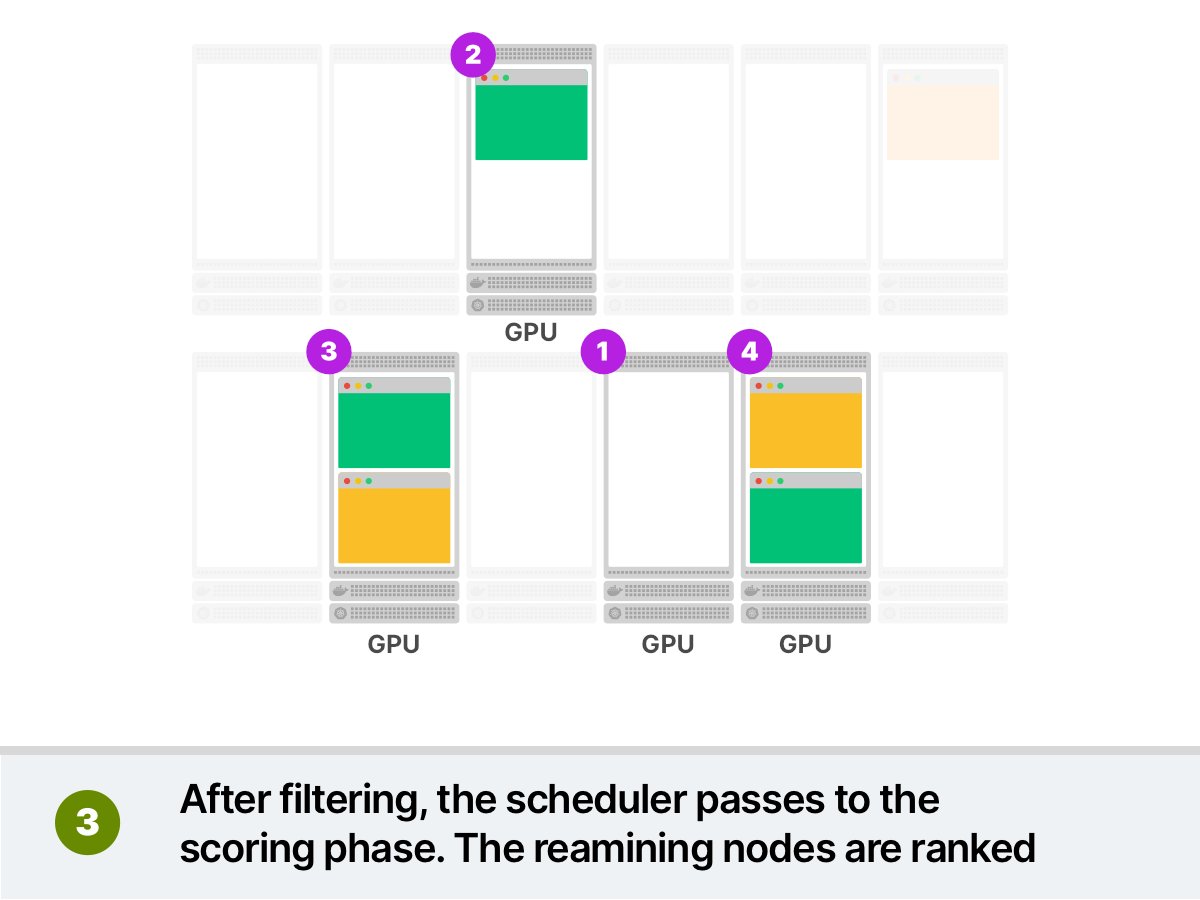
- 过滤相关节点(使用一组被称为谓词(predicate)的函数)
- 排列其余节点(使用一组被称为优先级(priority)的函数)
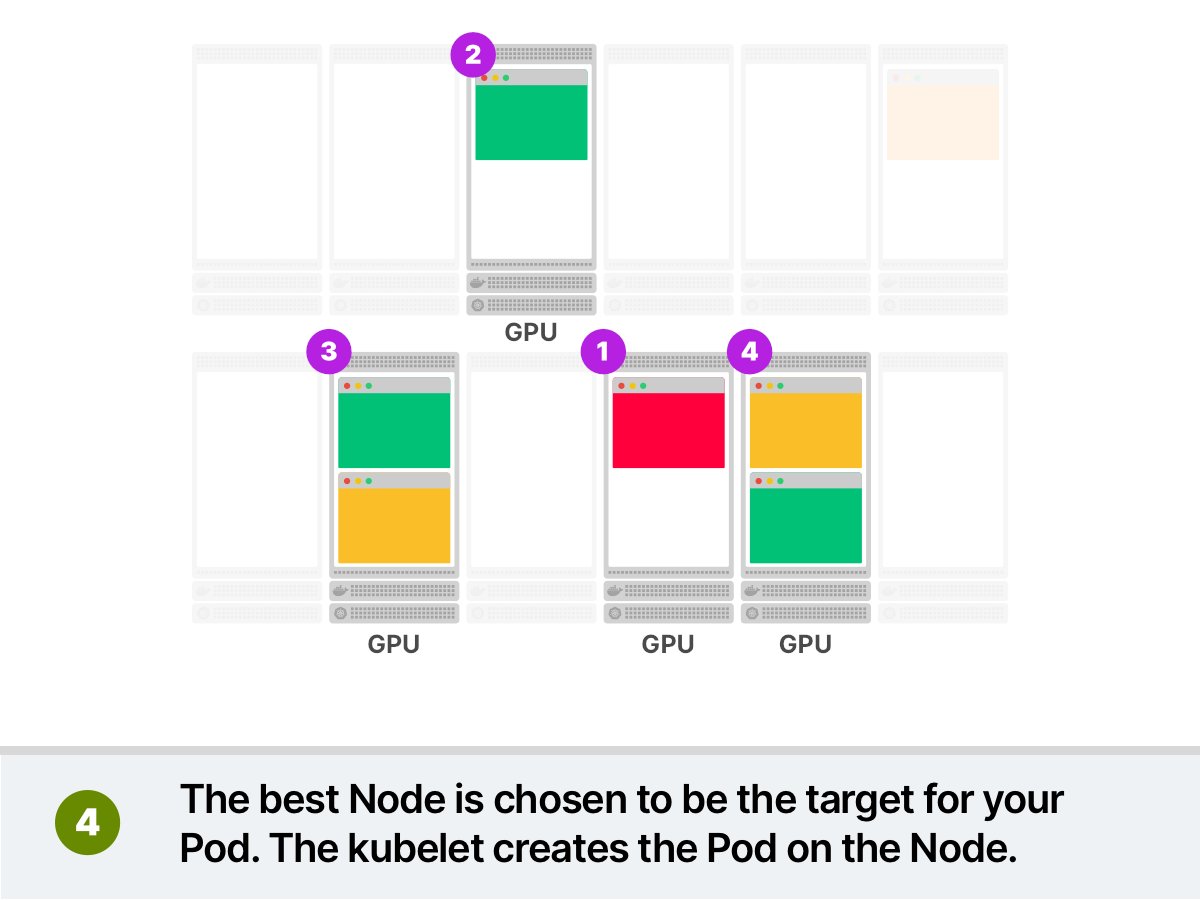
让我们举个例子。 比如,你要部署一些对GPU有需求的Pod。你将Pod提交给集群,然后:
- 调度器过滤掉所有不具有GPU的节点;
- 调度器对其余节点进行排名,并选择利用率最低的节点;
- 将pod调度到该节点上运行。


截至目前,过滤阶段有13个谓词。这是13个函数,用于确定调度器是否排除该节点作为Pod的可能目标节点。
计分阶段也有13个priority函数。这13个函数决定如何对节点评分和排名。


如何影响调度器的决策?
- nodeSelector
- 节点亲和力(node affinity)
- pod亲和力/反亲和力(pod affinity/anti-affinity)
- taint和容忍度(toleration)
如何自定义调度器?
您可以为调度器编写插件。您可以在调度阶段自定义任何过滤和打分函数。 但是,绑定阶段尚未公开任何公共API。
其他学习资料
你还可以通过下面链接了解更多有关调度程序的信息:
本文翻译自[《How does the scheduler work in Kubernetes?》(https://threadreaderapp.com/thread/1309090938673868801.html)]。
讲师主页:tonybai_cn
讲师博客: Tony Bai
专栏:《改善Go语言编程质量的50个有效实践》






