

前言
React 现在将整体的数据结构从树改为了链表结构。所以相应的 Diff 算法也得改变,以为以前的 Diff 算法就是基于树的。
老的 Diff 算法提出了三个策略来保证整体界面构建的性能,具体是:
Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。
拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
基于以上三个前提策略,React 分别对 tree diff、component diff 以及 element diff 进行算法优化。
接下来就开始正式的讲解 React 16 的 Diff 策略吧!
Diff 简介
做 Diff 的目的就是为了复用节点。
链表的每一个节点是 Fiber,而不是在 16 之前的虚拟DOM 节点。
虚拟 DOM 节点是指 React.createElement 方法所产生的节点。虚拟 DOM tree 只维护了组件状态以及组件与 DOM 树的关系,Fiber Node 承载的东西比 虚拟 DOM 节点多很多。
React16 的 diff 策略采用从链表头部开始比较的算法,是层次遍历,算法是建立在一个节点的插入、删除、移动等操作都是在节点树的同一层级中进行的。
对于 Diff, 新老节点的对比,以新节点为标准,然后来构建整个 currentInWorkProgress,对于新的 children 会有四种情况。
TextNode(包含字符串和数字)
单个 React Element(通过该节点是否有
$$typeof区分)数组
可迭代的 children,跟数组的处理方式差不多
那么我们就来一步一步的看这四种类型是如何进行 diff 的。
前置知识介绍
介绍之前了解下只怎么进入到这个 diff 函数的,react 的 diff 算法是从 reconcileChildren 开始的
export function reconcileChildren(
current: Fiber | null,
workInProgress: Fiber,
nextChildren: any,
renderExpirationTime: ExpirationTime,
) {
if (current === null) {
workInProgress.child = mountChildFibers(
workInProgress,
null,
nextChildren,
renderExpirationTime,
);
} else {
workInProgress.child = reconcileChildFibers(
workInProgress,
current.child,
nextChildren,
renderExpirationTime,
);
}
}
reconcileChildren 只是一个入口函数,如果首次渲染,current 空 null,就通过mountChildFibers 创建子节点的 Fiber 实例。如果不是首次渲染,就调用reconcileChildFibers去做 diff,然后得出 effect list。
接下来再看看 mountChildFibers 和 reconcileChildFibers 有什么区别:
export const reconcileChildFibers = ChildReconciler(true);
export const mountChildFibers = ChildReconciler(false);
他们都是通过 ChildReconciler 函数来的,只是传递的参数不同而已。这个参数叫shouldTrackSideEffects,他的作用是判断是否要增加一些effectTag,主要是用来优化初次渲染的,因为初次渲染没有更新操作。
function reconcileChildFibers(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChild: any,
expirationTime: ExpirationTime,
): Fiber | null {
// 主要的 Diff 逻辑
}
reconcileChildFibers 就是 Diff 部分的主体代码,这个函数超级长,是一个包装函数,下面所有的 diff 代码都在这里面,详细的源码注释可以见这里。
参数介绍
returnFiber是即将 Diff 的这层的父节点。currentFirstChild是当前层的第一个 Fiber 节点。newChild是即将更新的 vdom 节点(可能是 TextNode、可能是 ReactElement,可能是数组),不是 Fiber 节点expirationTime是过期时间,这个参数是跟调度有关系的,本系列还没讲解,当然跟 Diff 也没有关系。
再次提醒,reconcileChildFibers 是 reconcile(diff) 的一层。
前置知识介绍完毕,就开始详细介绍每一种节点是如何进行 Diff 的。
Diff TextNode
首先看 TextNode,因为它是最简单的,担心直接看到难的,然后就打击你的信心。
看下面两个小 demo:
// demo1:当前 ui 对应的节点的 jsx
return (
<div>
// ...
<div>
<xxx></xxx>
<xxx></xxx>
</div>
//...
</div>
)
// demo2:更新成功后的节点对应的 jsx
return (
<div>
// ...
<div>
前端桃园
</div>
//...
</div>
)
对应的单链表结构图:

对于 diff TextNode 会有两种情况。
currentFirstNode 是 TextNode
currentFirstNode 不是 TextNode
currentFirstNode 是当前该层的第一个节点,reconcileChildFibers 传进来的参数。
为什么要分两种情况呢?原因就是为了复用节点
第一种情况。xxx 是一个 TextNode,那么就代表这这个节点可以复用,有复用的节点,对性能优化很有帮助。既然新的 child 只有一个 TextNode,那么复用节点之后,就把剩下的 aaa 节点就可以删掉了,那么 div 的 child 就可以添加到 workInProgress 中去了。
源码如下:
if (currentFirstChild !== null && currentFirstChild.tag === HostText) {
// We already have an existing node so let's just update it and delete
// the rest.
deleteRemainingChildren(returnFiber, currentFirstChild.sibling);
const existing = useFiber(currentFirstChild, textContent, expirationTime);
existing.return = returnFiber;
return existing;
}
在源码里 useFiber 就是复用节点的方法,deleteRemainingChildren 就是删除剩余节点的方法,这里是从 currentFirstChild.sibling 开始删除的。
第二种情况。xxx 不是一个 TextNode,那么就代表这个节点不能复用,所以就从currentFirstChild开始删掉剩余的节点,对应到上面的图中就是删除掉 xxx 节点和 aaa 节点。
对于源码如下:
deleteRemainingChildren(returnFiber, currentFirstChild);
const created = createFiberFromText(
textContent,
returnFiber.mode,
expirationTime,
);
created.return = returnFiber;
其中 createFiberFromText 就是根据 textContent 来创建节点的方法。
注意:删除节点不会真的从链表里面把节点删除,只是打一个 delete 的 tag,当 commit 的时候才会真正的去删除。
Diff React Element
有了上面 TextNode 的 Diff 经验,那么来理解 React Element 的 Diff 就比较简单了,因为他们的思路是一致的:先找有没有可以复用的节点,如果没有就另外创建一个。
那么就有一个问题,如何判断这个节点是否可以复用呢?
有两个点:1. key 相同。2. 节点的类型相同。
如果以上两点相同,就代表这个节点只是变化了内容,不需要创建新的节点,可以复用的。
对应的源码如下:
if (child.key === key) {
if (
child.tag === Fragment
? element.type === REACT_FRAGMENT_TYPE
: child.elementType === element.type
) {
// 为什么要删除老的节点的兄弟节点?
// 因为当前节点是只有一个节点,而老的如果是有兄弟节点是要删除的,是多于的。删掉了之后就可以复用老的节点了
deleteRemainingChildren(returnFiber, child.sibling);
// 复用当前节点
const existing = useFiber(
child,
element.type === REACT_FRAGMENT_TYPE
? element.props.children
: element.props,
expirationTime,
);
existing.ref = coerceRef(returnFiber, child, element);
existing.return = returnFiber;
return existing;
}
相信这些代码都很好理解了,除了判断条件跟前面 TextNode 的判断条件不一样,其余的基本都一样,只是 React Element 多了一个跟新 ref 的过程。
同样,如果节点的类型不相同,就将节点从当前节点开始把剩余的都删除。
deleteRemainingChildren(returnFiber, child);
到这里,可能你们就会觉得接下来应该就是讲解当没有可以复用的节点的时候是如果创建节点的。
不过可惜你们猜错了。因为 Facebook 的工程师很厉害,另外还做了一个工作来优化,来找到复用的节点。
我们现在来看这种情况:

这种情况就是有可能更新的时候删除了一个节点,但是另外的节点还留着。
那么在对比 xxx 节点和 AAA 节点的时候,它们的节点类型是不一样,按照我们上面的逻辑,还是应该把 xxx 和 AAA 节点删除,然后创建一个 AAA 节点。
但是你看,明明 xxx 的 slibling 有一个 AAA 节点可以复用,但是被删了,多浪费呀。所以还有另外有一个策略来找 xxx 的所有兄弟节点中有没有可以复用的节点。
这种策略就是从 div 下面的所有子节点去找有没有可以复用的节点,而不是像 TextNode 一样,只是找第一个 child 是否可以复用,如果当前节点的 key 不同,就代表肯定不是同一个节点,所以把当前节点删除,然后再去找当前节点的兄弟节点,直到找到 key 相同,并且节点的类型相同,否则就删除所有的子节点。
你有木有这样的问题:为什么 TextNode 不采用这样的循环策略来找可以复用的节点呢?这个问题留给你思考,欢迎在评论区留下你的答案。
对应的源码逻辑如下:
// 找到 key 相同的节点,就会复用当前节点
while (child !== null) {
if (child.key === key) {
if (
child.tag === Fragment
? element.type === REACT_FRAGMENT_TYPE
: child.elementType === element.type
) {
// 复用节点逻辑,省略该部分代码,和上面复用节点的代码相同
// code ...
return existing;
} else {
deleteRemainingChildren(returnFiber, child);
break;
}
} else {
// 如果没有可以复用的节点,就把这个节点删除
deleteChild(returnFiber, child);
}
child = child.sibling;
}
在上面这段代码我们需要注意的是,当 key 相同,React 会认为是同一个节点,所以当 key 相同,节点类型不同的时候,React 会认为你已经把这个节点重新覆盖了,所以就不会再去找剩余的节点是否可以复用。只有在 key 不同的时候,才会去找兄弟节点是否可以复用。
接下来才是我们前面说的,如果没有找到可以复用的节点,然后就重新创建节点,源码如下:
// 前面的循环已经把该删除的已经删除了,接下来就开始创建新的节点了
if (element.type === REACT_FRAGMENT_TYPE) {
const created = createFiberFromFragment(
element.props.children,
returnFiber.mode,
expirationTime,
element.key,
);
created.return = returnFiber;
return created;
} else {
const created = createFiberFromElement(
element,
returnFiber.mode,
expirationTime,
);
created.ref = coerceRef(returnFiber, currentFirstChild, element);
created.return = returnFiber;
return created;
}
对于 Fragment 节点和一般的 Element 节点创建的方式不同,因为 Fragment 本来就是一个无意义的节点,他真正需要创建 Fiber 的是它的 children,而不是它自己,所以createFiberFromFragment 传递的不是 element,而是element.props.children。
Diff Array
Diff Array 算是 Diff 中最难的一部分了,比较的复杂,因为做了很多的优化,不过请你放心,认真看完我的讲解,最难的也会很容易理解,废话不多说,开始吧!
因为 Fiber 树是单链表结构,没有子节点数组这样的数据结构,也就没有可以供两端同时比较的尾部游标。所以React的这个算法是一个简化的两端比较法,只从头部开始比较。
前面已经说了,Diff 的目的就是为了复用,对于 Array 就不能像之前的节点那样,仅仅对比一下元素的 key 或者 元素类型就行,因为数组里面是好多个元素。你可以在头脑里思考两分钟如何进行复用节点,再看 React 是怎么做的,然后对比一下孰优孰劣。
1. 相同位置(index)进行比较
相同位置进行对比,这个是比较容易想到的一种方式,还是举个例子加深一下印象。

这已经是一个非常简单的例子了,div 的 child 是一个数组,有 AAA、BBB 然后还有其他的兄弟节点,在做 diff 的时候就可以从新旧的数组中按照索引一一对比,如果可以复用,就把这个节点从老的链表里面删除,不能复用的话再进行其他的复用策略。
那如果判断节点是否可以复用呢?有了前面的 ReactElement 和 TextNode 复用的经验,这个也类似,因为是一一对比嘛,相当于是一个节点一个节点的对比。
不过对于 newChild 可能会有很多种类型,简单的看下源码是如何进行判断的。
const key = oldFiber !== null ? oldFiber.key : null;
前面的经验可得,判断是否可以复用,常常会根据 key 是否相同来决定,所以首先获取了老节点的 key 是否存在。如果不存在老节点很可能是 TextNode 或者是 Fragment。
接下来再看 newChild 为不同类型的时候是如何进行处理的。
当 newChild 是 TextNode 的时候
if (typeof newChild === 'string' || typeof newChild === 'number') {
// 对于新的节点如果是 string 或者 number,那么都是没有 key 的,
// 所有如果老的节点有 key 的话,就不能复用,直接返回 null。
// 老的节点 key 为 null 的话,代表老的节点是文本节点,就可以复用
if (key !== null) {
return null;
}
return updateTextNode(
returnFiber,
oldFiber,
'' + newChild,
expirationTime,
);
}
如果 key 不为 null,那么就代表老节点不是 TextNode,而新节点又是 TextNode,所以返回 null,不能复用,反之则可以复用,调用 updateTextNode 方法。
注意,updateTextNode 里面包含了首次渲染的时候的逻辑,首次渲染的时候回插入一个 TextNode,而不是复用。
当 newChild 是 Object 的时候
newChild 是 Object 的时候基本上走的就是 ReactElement 的逻辑了,判断 key 和 元素的类型是否相等来判断是否可以复用。
if (typeof newChild === 'object' && newChild !== null) {
// 有 `$$typeof` 代表就是 ReactElement
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE: {
// ReactElement 的逻辑
}
case REACT_PORTAL_TYPE: {
// 调用 updatePortal
}
}
if (isArray(newChild) || getIteratorFn(newChild)) {
if (key !== null) {
return null;
}
return updateFragment(
returnFiber,
oldFiber,
newChild,
expirationTime,
null,
);
}
}
首先判断是否是对象,用的是 typeof newChild === 'object' && newChild !== null ,注意要加 !== null,因为 typeof null 也是 object。
然后通过 $$typeof 判断是 REACT_ELEMENT_TYPE 还是 REACT_PORTAL_TYPE,分别调用不同的复用逻辑,然后由于数组也是 Object ,所以这个 if 里面也有数组的复用逻辑。
我相信到这里应该对于应该对于如何相同位置的节点如何对比有清晰的认识了。另外还有问题,那就是如何循环一个一个对比呢?
这里要注意,新的节点的 children 是虚拟 DOM,所以这个 children 是一个数组,而对于之前提到的老的节点树是链表。
那么循环一个一个对比,就是遍历数组的过程。
let newIdx = 0 // 新数组的索引
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
// 遍历老的节点
nextOldFiber = oldFiber.sibling;
// 返回复用节点的函数,newFiber 就是复用的节点。
// 如果为空,就代表同位置对比已经不能复用了,循环结束。
const newFiber = updateSlot(
returnFiber,
oldFiber,
newChildren[newIdx],
expirationTime,
);
if (newFiber === null) {
break;
}
// 其他 code,比如删除复用的节点
}
这并不是源码的全部源码,我只是把思路给贴出来了。
这是第一次遍历新数组,通过调用 updateSlot 来对比新老元素,前面介绍的如何对比新老节点的代码都是在这个函数里。这个循环会把所以的从前面开始能复用的节点,都复用到。比如上面我们画的图,如果两个链表里面的 ???节点,不相同,那么 newFiber 为 null,这个循环就会跳出。
跳出来了,就会有两种情况。
新节点已经遍历完毕
老节点已经遍历完毕
2. 新节点已经遍历完毕
如果新节点已经遍历完毕的话,也就是没有要更新的了,这种情况一般就是从原来的数组里面删除了元素,那么直接把剩下的老节点删除了就行了。还是拿上面的图的例子举例,老的链表里???还有很多节点,而新的链表???已经没有节点了,所以老的链表???不管是有多少节点,都不能复用了,所以没用了,直接删除。
if (newIdx === newChildren.length) {
// 新的 children 长度已经够了,所以把剩下的删除掉
deleteRemainingChildren(returnFiber, oldFiber);
return resultingFirstChild;
}
注意这里是直接 return 了哦,没有继续往下执行了。
3. 老节点已经遍历完毕
如果老的节点在第一次循环的时候就被复用完了,新的节点还有,很有可能就是新增了节点的情况。那么这个时候只需要根据把剩余新的节点直接创建 Fiber 就行了。
if (oldFiber === null) {
// 如果老的节点已经被复用完了,对剩下的新节点进行操作
for (; newIdx < newChildren.length; newIdx++) {
const newFiber = createChild(
returnFiber,
newChildren[newIdx],
expirationTime,
);
}
return resultingFirstChild;
}
oldFiber === null 就是用来判断老的 Fiber 节点变量完了的代码,Fiber 链表是一个单向链表,所以为 null 的时候代表已经结束了。所以就直接把剩余的 newChild 通过循环创建 Fiber。
到这里,目前简单的对数组进行增、删节点的对比还是比较简单,接下来就是移动的情况是如何进行复用的呢?
4. 移动的情况如何进行节点复用
对于移动的情况,首先要思考,怎么能判断数组是否发生过移动操作呢?
如果给你两个数组,你是否能判断出来数组是否发生过移动。
答案是:老的数组和新的数组里面都有这个元素,而且位置不相同。
从两个数组中找到相同元素(是指可复用的节点),方法有很多种,来看看 React 是如何高效的找出来的。
把所有老数组元素按 key 或者是 index 放 Map 里,然后遍历新数组,根据新数组的 key 或者 index 快速找到老数组里面是否有可复用的。
function mapRemainingChildren(
returnFiber: Fiber,
currentFirstChild: Fiber,
): Map<string | number, Fiber> {
const existingChildren: Map<string | number, Fiber> = new Map();
let existingChild = currentFirstChild; // currentFirstChild 是老数组链表的第一个元素
while (existingChild !== null) {
// 看到这里可能会疑惑怎么在 Map 里面的key 是 fiber 的key 还是 fiber 的 index 呢?
// 我觉得是根据数据类型,fiber 的key 是字符串,而 index 是数字,这样就能区分了
// 所以这里是用的 map,而不是对象,如果是对象的key 就不能区分 字符串类型和数字类型了。
if (existingChild.key !== null) {
existingChildren.set(existingChild.key, existingChild);
} else {
existingChildren.set(existingChild.index, existingChild);
}
existingChild = existingChild.sibling;
}
return existingChildren;
}
这个 mapRemainingChildren 就是将老数组存放到 Map 里面。元素有 key 就 Map 的键就存 key,没有 key 就存 index,key 一定是字符串,index 一定是 number,所以取的时候是能区分的,所以这里用的是 Map,而不是对象,如果是对象,属性是字符串,就没办法区别是 key 还是 index 了。
现在有了这个 Map,剩下的就是循环新数组,找到 Map 里面可以复用的节点,如果找不到就创建,这个逻辑基本上跟 updateSlot 的复用逻辑很像,一个是从老数组链表中获取节点对比,一个是从 Map 里获取节点对比。
// 如果前面的算法有复用,那么 newIdx 就不从 0 开始
for (; newIdx < newChildren.length; newIdx++) {
const newFiber = updateFromMap(
existingChildren,
returnFiber,
newIdx,
newChildren[newIdx],
expirationTime,
);
// 省略删除 existingChildren 中的元素和添加 Placement 副作用的情况
}
到这里新数组遍历完毕,也就是同一层的 Diff 过程完毕,接下来进行总结一下。
效果演示
以下效果动态演示来自于文章:React Diff 源码分析,我觉得这个演示非常的形象,有助于理解。
这里渲染一个可输入的数组。
 1
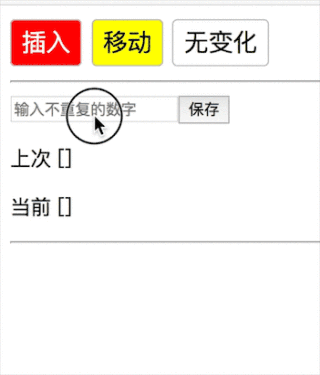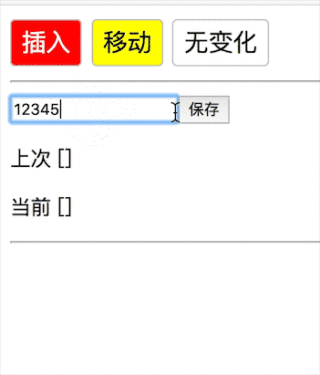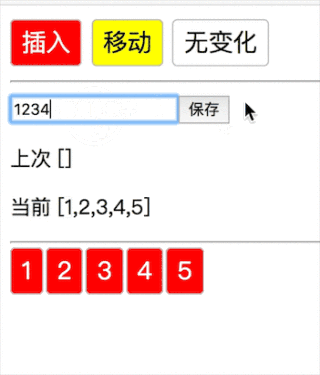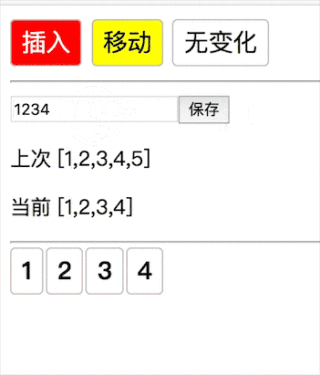
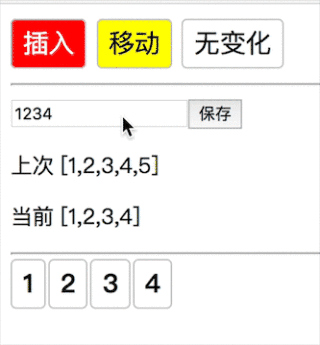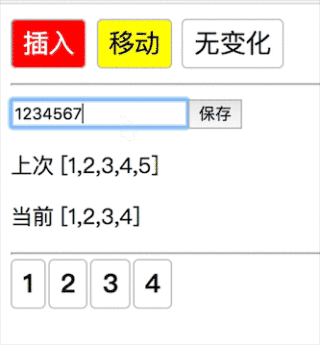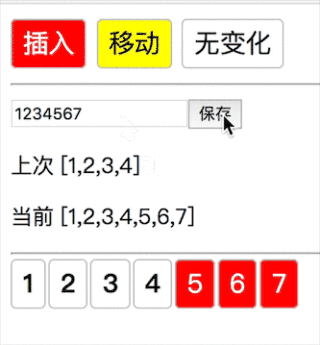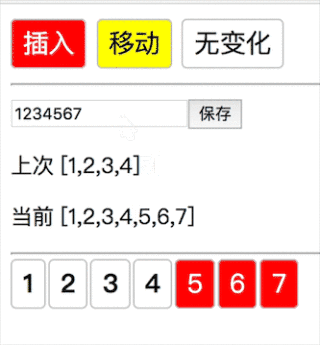
1当第一种情况,新数组遍历完了,老数组剩余直接删除(12345→1234 删除 5):
新数组没完,老数组完了(1234→1234567 插入 567):
移动的情况,即之前就存在这个元素,后续只是顺序改变(123 → 4321 插入4,移动2 1):
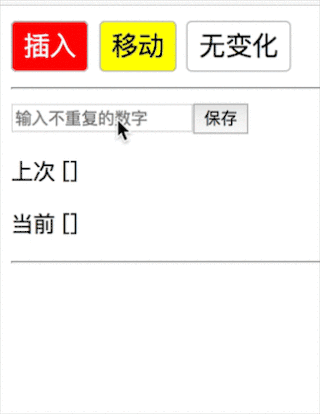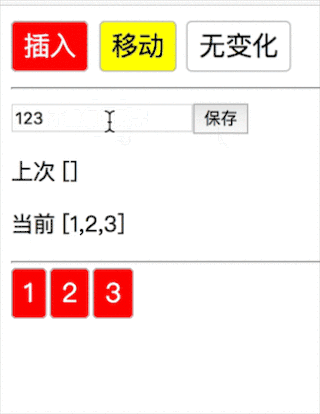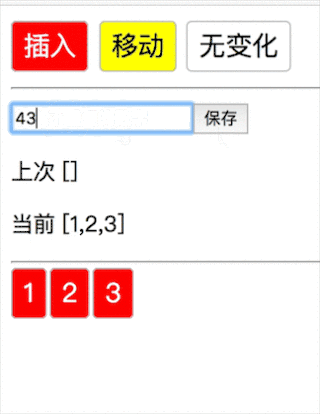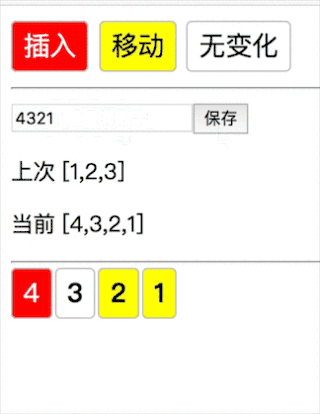
最后删除没有涉及的元素。
总结
对于数组的 diff 策略,相对比较复杂,最后来梳理一下这个策略,其实还是很简单,只是看源码的时候比较难懂。
我们可以把整个过程分为三个阶段:
第一遍历新数组,新老数组相同 index 进行对比,通过
updateSlot方法找到可以复用的节点,直到找到不可以复用的节点就退出循环。第一遍历完之后,删除剩余的老节点,追加剩余的新节点的过程。如果是新节点已遍历完成,就将剩余的老节点批量删除;如果是老节点遍历完成仍有新节点剩余,则将新节点直接插入。
把所有老数组元素按 key 或 index 放 Map 里,然后遍历新数组,插入老数组的元素,这是移动的情况。




