
0x00 前言
大家好我是小蕉。上一次我们说完了线性回归。不知道小伙伴有没有什么意见建议,是不是发现每个字都看得懂,但是全篇都不知道在说啥?哈哈哈哈哈哈,那就对了。
这次我们来聊聊,有小伙伴说,如果我的结果不是想找到一个连续型的规律,而是理想型的变量,也就是说如果我么想把结果分为两拨,就这样的,咋办?大蕉大笔一挥。啊这不是分好了吗?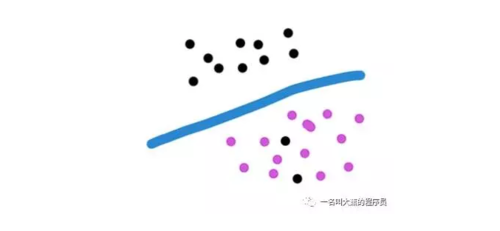
我敢说,现在百分之很多十(目测七八十)说自己在做人工智能的,都只是用Logistic回归在做分析。
“就你事多。我不会分。”
“想学啊你?我教你啊。”
0x01 Logistic是啥玩意
想法大概是这样。把数据映射到Sigmoid函数上边,大于0.5我们就认为是类别y1 = 0,小于0.5我们认为是类别y2 = 1。
y ∈ {0 , 1}
这个函数长啥样?就长下面这样。

因为是二分类问题,所以我们假设数据服从伯努利分布,而伯努利分布的概率分布函数,也就是Y=1的概率函数就是Simoid函数。所以我们在这种情况下,我们观察到各个样本的概率长下面这样。

进而比值比ODD 长这样
对数比值比刚刚好
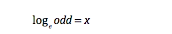
你说神不神奇!!当然我们不仅仅只有一个参数是吧?所以对原始数据变成

其中θ是一个N维的向量,跟每一个样本X的维度保持一致这样。
所以LR的映射函数做一下线性变换就变成这样了。

到这里,我们已经知道Logistic回归是什么鸟了,其实就是把数据映射到Sigmoid函数上,得到一个概率,然后我们最终通过概率来进行分类,一般是取0.5这样。
0x02 极大似然估计
那我们要怎么得到损失函数loss呢?不要急跟大蕉一步一步来。
上面我们已经看到了每个样本的概率。现在说一下极大似然估计是什么东西。极大似然估计,就是我们装作这些个参数啊,我们老早就知道了,然后借此来估计现在这些样本被观察到的概率。你脑子wata啦?既然这些样本都已经发现了,所以实际概率肯定是百分之百啊!!概率要越大越好越大越好,而又只是一个估计值,所以我们就叫它极大似然估计啦。
所以我们观察到样本的概率是

怎么容易一点去理解这行蜈蚣一样的公式呢?把Y的值0跟1代进去就行了,你就懂了,Y等于0的时候就是(1 - p ),y等于1时就是 p。就是这么简单。
下面是重点。敲黑板,划重点!!!我就是卡在这里想了很多天,完全不知道损失函数怎么来的!
因为所有样本都是相互独立的,所以他们的联合概率分布是他们的概率乘积。

yi是每个样本的实际Y值。我们这里要求最大值嘛,那要变成损失函数咋变?我们知道这个值永远是 ( 0 , 1)的,所以直接加个负号,本来求最大就变成求最小了。
∴ loss = - L(θ)
当然我们习惯这样加,看起来比较高端,m是样本的个数
∴ loss = - 1/m * L(θ)
无所谓,原理一样的。
乘法是很消耗资源的,我们可以把它转换成对数,这样所有的乘法都变成加法啦!!而且而且函数的性质不变。所以最终的损失函数长这样。
loss(θ) = - log L(θ)
下面开始我们用Andrew NG大大的方式变换一下好了,仅仅是为了后面比较好算而已。
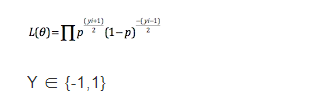
跟上面没什么本质的差别,只是把Y的值域变成-1跟1了。下面就是普通的公式变换。
0x03 损失函数咋来的
进行log变换,幂乘变成乘法。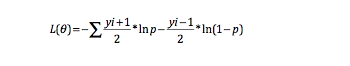
把p代进去,也就是把把负号放到P里边了。变成直接取倒数。就得到下面这个
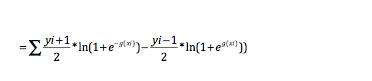
观察一下,就可以看出来。自己代进去就知道啦。

所以最终的损失函数长这样。
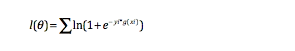
好了,到这里我们的推导就结束了,接下来就按照梯度下降算法去求最小值就好啦。
0x04 怎么用呢
然后我们就可以用最终得到的参数进行预测,大于0就当成类别Y1 ,即Y = 1,小于0当成类别Y1,即Y = -1。当然,这只能用于二分类。
那这玩意有什么用呢?应用场景比比皆是。
用户点击还是不点击?客户是欺诈还是没欺诈?客户逾期还是不逾期?这个产品是推荐还是不推荐?
传说中的人工智能预测高端引擎就出来了,小伙伴自己试试看吧。
但那我就是想进行多分类?怎么办?也是有办法的。一般来说有两种方式。我们假设有N个类别。OVR(One Versus Rest)。每个类别和剩余的其他类别进行对比,可以训练出N-1个分类器,然后这N-1个分类器进行投票,就可以生成多分类器啦。OVO(One Versus One)。每次只取两个类别进行训练,然后训练出N(N-1)个分类器,然后这些分类器进行投票,也可以生成多分类器。
至于怎么投票,也有很多种方式。可以直接投票啦,也可以根据AUC对每个分类器进行赋予权重。
0x05 剩下的一点东西
Logistic回归跟线性回归有什么差异性?1、Logistic回归的目标值(Y值)是离散的,而线性回归的目标值是连续的。2、Logistic回归和线性回归都是做了线性变换,区别是Logistic回归还做了Simoid变换。3、Logistic回归出结果值后还要进行概率判断进行分类,线性回归出结果值后可以直接使用。
Logistic回归的归一化值如何理解为概率?Logistic回归其实先验于数据是服从伯努利分布的,从而概率分布函数为Sigmoid函数。在进行Logistic回归模型训练后,最好对每个变量进行显著性检验,证明自变量和Y变量确实存在线性相关关系。
Logistic损失有何优化空间?跟线性回归一样,可以加正则项进行参数稀疏化,防止过拟合。
特征预处理和数据标准化,如何操作?1、变量要进行相关性分析,去除自变量间的相关变量,以及自变量与因变量相关性太高的变量2、多分类变量应该进行ont-hot编码,变成多个哑变量,防止分类数字影响3、如果是连续型变量,可以进行分箱操作,保留相对的大小即可。如,年龄0-20岁为1,20-40岁为2,这样子,可以分箱又保留了数据的顺序性。4、跟其他特征预处理一样,可以使用一些特征选择模型,先进行一次筛选,再进行特征组合等,多次进行模型训练。
0x06 结束语
以上说的都是个人感悟,不一定全对。今天就酱,掰~跪在地上求不掉粉。(T_T又掉了几个读者,蓝瘦)





