
[TOC]
第一节 Kafka 集群
承前
如果你是开发, 对搭建kafka集群没什么兴趣, 可以跳过这一章, 直接看明天的内容.
如果你觉得多了解一点没有什么坏处的话, 请继续看下去.
提醒一下, 本章图多
Kafka 集群搭建
概述
kafka集群的搭建还是比较繁琐的, 虽然只是下载文件,修改配置,但数据比较多.
基本环境需要3台zk服务器 和3台 kafka服务器.
操作流程
看图

看上去就比较长, 所以我不用这种方法, 使用docker 来简化一点流程.
Kafka 集群快速搭建
安装 Docker
算复习
uname -a
yum -y install docker
service docker start
# 或
curl -fsSL https://get.docker.com -o get-docker.sh
sh get-docker.sh
镜像加速
vi /etc/docker/daemon.json
{
"registry-mirrors": ["https://uzoia35z.mirror.aliyuncs.com"]
}
zookeeper集群
docker-compose 已装好
新建docker网络
docker network create --driver bridge --subnet 172.29.0.0/25 \
--gateway 172.29.0.1 elk_zoo
docker network ls
yml 脚本
配置太长,这里先放个结构, 源文件稍后会放在博客上.
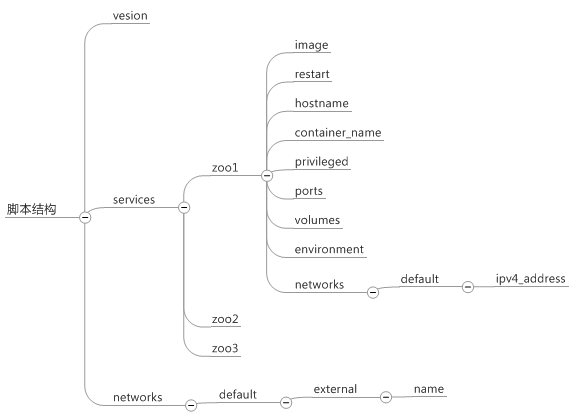
列出的项目基本都要配置, 重点注意:
- ports: # 端口
- volumes: # 挂载卷
- environment: 环境变量
- networks: 有两部分, ip 和共有网络
请参考配置文件印证.
docker-compose up -d
验证
ZooInspector
cd zookeeper/src/contrib/zooinspector/
# 打开失败,需要验证
Kafka集群
镜像
docker pull wurstmeister/kafka
docker pull sheepkiller/kafka-manager
yml 脚本
配置太长,这里先放个结构, 源文件稍后会放在博客上.
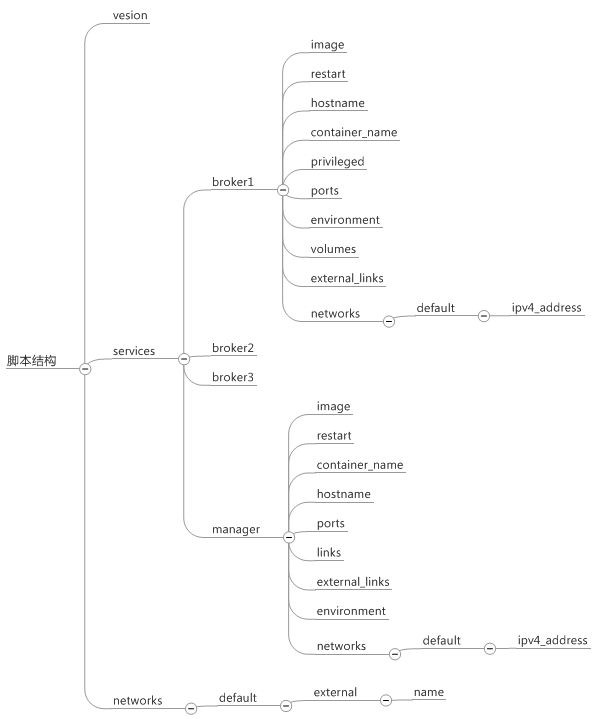
列出的项目基本都要配置, 重点注意:
- ports: # 端口
- volumes: # 挂载卷
- environment: 环境变量
- external_links 外连
- networks: 有两部分, ip 和共有网络
请参考配置文件印证.
docker-compose up -d
验证
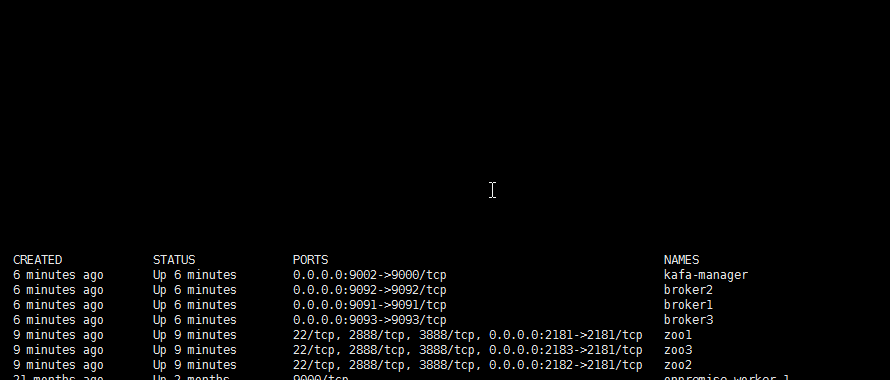
使用 kafka-manager 的管理页面,本机ip加9000端口
搞定收工.
本着对懒惰之神的信仰, 用docker短时间搞定了集群的搭建, 鼓掌.
明天开始命令行实操,敬请期待.
今天的三张图都比较复杂, 不需要记忆, 对照配置文件理清楚流程即可.
第二节 集群管理工具
先来一个问题吧, 昨天我搭完了kafka的集群, 管理工具也装好了, 一切如截图所示.
有没有同学能看出或猜出该集群存在的问题呢? 对自己有信心的可以加我好友私聊, 思路对的话, 我也可以发个小红包鼓励的.
集群管理工具
概述
kafa-manager 是一个常用的 kafka集群管理工具, 类似工具还有很多, 也有公司自己开发类型的工具.
操作流程
当集群配置好之后, 可以通过浏览器登录kafa-manager , 并添加集群管理.
添加完毕后, 会显示这样
查看Broker信息
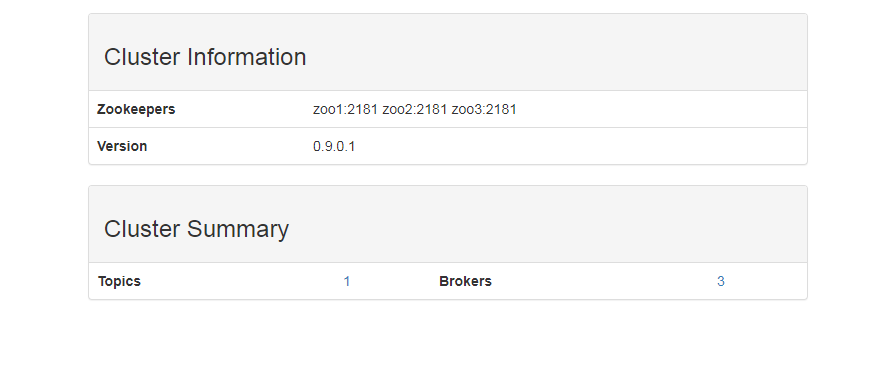
点击Topic 可以查看Topic
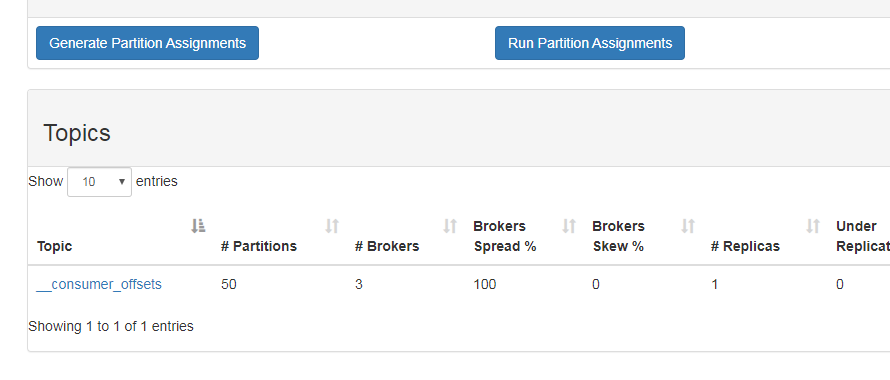
再点击可以进行单条信息的设置
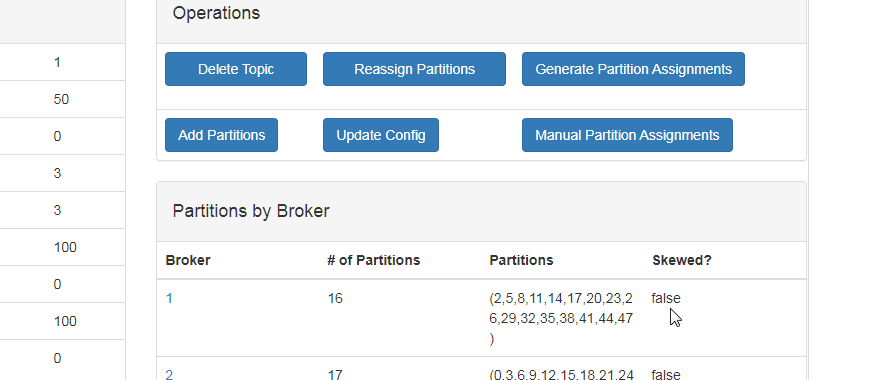
其他
Preferred Replica Election
Reassign Partitions
Consumers
分别涉及副本选举, 分区和消费者, 后续讲到了再介绍.
因为集群刚建好, 很多信息会看不到,后面几篇会结合命令行操作一同展示.
集群 Issues
下面记录一些常见故障,及排查思路:
-
单机可以用, 集群发送信息失败
host 名字不能设置为127.0.0.1
-
升级后不能消费信息
检查 默认的topic
__consumer_offsets
-
响应比较慢
使用性能测试脚本:
kafka-producer-perf-test.sh
分析生成报告
检查 jstack信息 或定位源码排查
-
日志持续报异常
检查kafka日志, 检查GC日志, 检查zk日志和GC日志, 检查节点内存监控
最后把报异常的节点下线再回复解决
-
docker遇到 挂载数据卷无限重启
查看logs发现没权限, 配置
privileged: true
-
docker里运行kafka命令时提示地址被占用
unset JMX_PORT;bin/kafka-topics.sh …
比较取巧的一个办法, 取消掉 kafka-env.sh 脚本定义了JMX_PORT变量.
第三节 使用命令操纵集群
正常情况下, Kafka都是通过代码连接的.
但是, 偶然你想确认下是Kafka错了,还是你的代码错了.
或者并没有条件及时间搞出一段代码的时候, 简单用命令行还是可以的.
docker
docker inspect zookeeper
zookeeper
集群查看
登录集群,判断状态
docker exec -it zoo1 bash
zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Mode: leader
# 注意 Mode: standalone 为单机
配置文件
如果状态是单机, 检查以下文件:
vi zoo.cfg # server.1=zoo1:2888:3888 之类, 多台
vi myid # 1或2等
# 也可能是环境变量形式
ZOO_MY_ID=3 \
ZOO_SERVERS="server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888"
启动zk集群
./zkServer.sh start
jps # QuorumPeerMain
kafka查看
docker exec -it zoo1 bash
zkCli.sh
ls /
ls /brokers/ids
# 查看kafka 的节点id
[1, 2, 3]
topic
创建topic
注意, 以下命令全部在kafka的目录下执行
cd /opt/kafka_2.12-2.3.0/
unset JMX_PORT;bin/kafka-topics.sh --create --zookeeper zoo1:2181 --replication-factor 1 --partitions 1 --topic test1
# 加参数 --bootstrap-server localhost:9091 可以用自带zk
# --config delete.retention.ms=21600000 日志保留6小时
创建集群topic
副本因子1, 分区数3, 名字为test.
unset JMX_PORT;bin/kafka-topics.sh --create --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --replication-factor 1 --partitions 3 --topic test
查看topic
列表及详情
unset JMX_PORT; bin/kafka-topics.sh --list --zookeeper zoo1:2181,zoo2:2181,zoo3:2181
unset JMX_PORT;bin/kafka-topics.sh --describe --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --topic __consumer_offsets
删除topic
默认标记删除
unset JMX_PORT;bin/kafka-topics.sh --delete --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --topic test
#设置 delete.topic.enable=true 真实删除
生产者
发送消息
cat config/server.properties |grep listeners # 获取监听地址
unset JMX_PORT;bin/kafka-console-producer.sh --broker-list broker1:9091 --topic test2
# 运行起来后可以输入信息
吞吐量测试
unset JMX_PORT;bin/kafka-producer-perf-test.sh --num-records 100000 --topic test --producer-props bootstrap.servers=b
roker1:9091,broker2:9092,broker3:9093 --throughput 5000 --record-size 102400 --print-metrics
# 3501 records sent, 699.2 records/sec (68.28 MB/sec), 413.5 ms avg latency, 1019.0 ms max latency.
消费者
接受消息
unset JMX_PORT;bin/kafka-console-consumer.sh --bootstrap-server broker1:9091 --topic test2
# 实时接受, 要从头接收使用 --from-beginning
列出消费者
unset JMX_PORT;bin/kafka-consumer-groups.sh --bootstrap-server broker1:9091 --list
# KafkaManagerOffsetCache
# console-consumer-26390
查看分区消息
查看当前分区最新收到的消息
unset JMX_PORT;bin/kafka-console-consumer.sh --bootstrap-server broker1:9091 --topic test2 --offset latest --partition 0
吞吐量测试
bin/kafka-consumer-perf-test.sh --topic test --messages 100000 --num-fetch-threads 10 --threads 10 --broker-list broker1:9091,broker2:9092,broker3:9093 --group console-consumer-26390
容错
unset JMX_PORT;bin/kafka-topics.sh --describe --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --topic test2
docker stop broker3
# 干掉一台broker, 再用上述命令查看, 注意 Leader: -1
unset JMX_PORT;bin/kafka-topics.sh --describe --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --topic test2
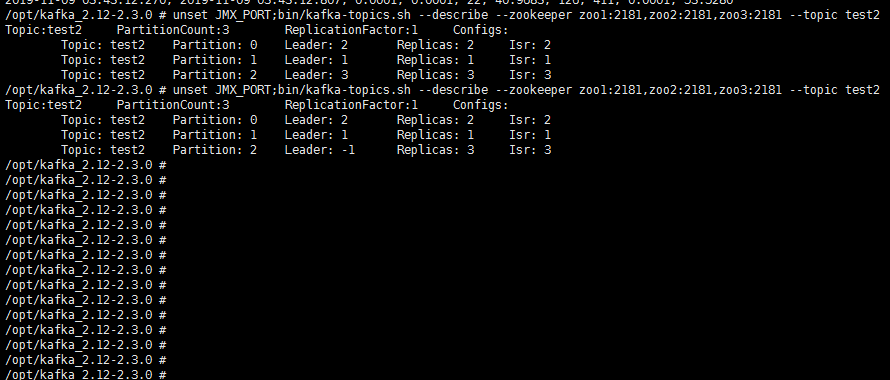
全部命令都手打了一遍, 保证可用.
涉及的命令都比较长, 请把代码框的命令一次复制上去, 不要考虑换行.
第四节 Kafka 术语说明
昨天说到命令行操作kafka集群, 其实有个小小故障的.
在运行生产者吞吐量测试时, 把集群打挂了.
阿里云的空间有限,kafka-producer-perf-test.sh 命令短时间填满了所有的磁盘空间.
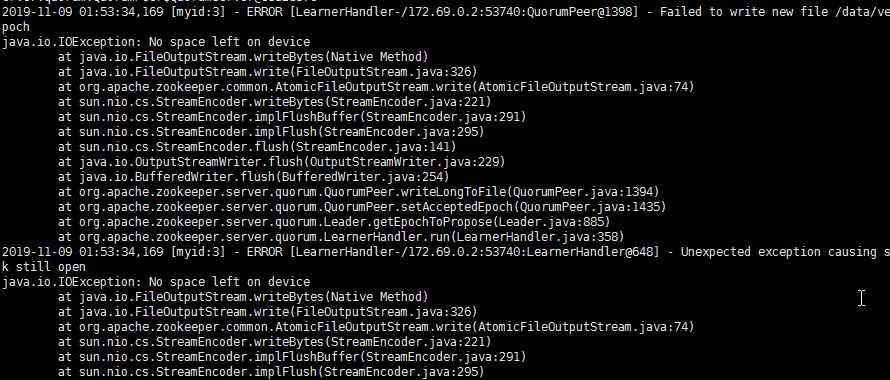
今天会科普一些kafka的基础知识. 新手向, 大牛请略过
简介
- Kafka是用Scala语言写的,
- 官方主页 kafka.apache.org ,
- 定义为分布式实时流处理平台,
- 其性能严重依赖磁盘的性能,
- 消息无状态, 需要定时或定量删除.
用途
消息系统
这个没什么说的, 著名的消息中间件.
应用监控
监控中主要配合ELK使用.
用户行为追踪
记录承载用户多方面的海量信息, 再转给各种大数据软件处理, 如Hadoop,Spark,Strom
流处理
收集流数据
这块是我的空缺, 昨天命令行操作时, 配置文件出了点错误, 后面会补上.
持久性日志
主要应用Kafka的性能特性, 再配合Flume + HDFS, 相当好用.
性能
据说Kafka千万级的性能, 我司没有这么大的量, 不敢评论. 不过百万级是公认的.
性能好的原因是大量使用操作系统页缓存,不直接参与物理I/O操作. 同时使用追加写入方式, 避免随机写入导致硬盘的性能噩梦.
还以sendfile为代表的零拷贝技术, 在内核区完成数据拷贝, 避开用户缓存.
数据保存
以下为Zookeeper中 Kafka 保存信息的几个目录, 可以适当了解. 查看方法:
docker exec -it zoo1 bash
zkCli.sh
ls /
ls /brokers/ids
...
| 目录名 | 用途 |
|---|---|
| brokers | 存放集群和topic信息 |
| controller | 存放节点选举相关信息 |
| admin | 存放脚本命令的输出结果 |
| isr_change_notification | 记录变化的ISR |
| config | 记录集群id 和版本号 |
| controller_epoch | 记录 controller版本号, 避免墓碑问题 |
专用名词
| 名称 | 用途 |
|---|---|
| broker | 指Kafka的服务器 |
| 集群 | 指多个broker组成的工作单元 |
| 消息 | 最基础数据单元 |
| 批次 | 指一组消息 |
| 副本 | 消息的冗余形式 |
| 消息模式 | 消息序列化的方式 |
| 提交 | 更新分区当前位置 |
| 主题 | mysql 中表格, 对应命令是topic |
| 分区 | 对应命令是 partition |
| 生产者 | 负责消息输入 |
| 消费者 | 负责消息输出 |
补充:
-
消息定位:
由tpoic, partition, offset 可以定位到唯一的一条消息. -
副本分为 leader replica和follower replica.
follower作用就是复制数据
在leader挂掉时, 从follower中选出新的leader.
follower作用就是复制数据, 并在leader挂掉 时,从中选出新的leader.
- topic可以设置多个分区,其中有多个segment以存放消息
配置文件
主要有以下4个相关配置文件:
| 用途 | 文件名 |
|---|---|
| broker 配置 | server.properties |
| zookeeper 配置 | zookeeper.properties |
| 消费者配置 | consumer.properties |
| 生产者配置 | producer.properties |
基础就是基础. yann也是学完这些基础的东西, 再次看到时才能鄙视以上内容的. 所以, 加油.
第五节 Kafka 集群工作原理
承前
昨天把自己的公众号发给大佬看, 结果被批评了. 说格式太乱, 看不下去. 然后我就开始进行调整格式之旅, 连着发了几十个预览, 感觉自己都晕掉了.
所以,今天的内容会有点水, 见谅.
集群原理
这里简单说一下, kafka的集群原理. 之前就说明过, kafka的集群是由三台ZooKeeper, 和三台kafka的集群组成的.
想互的关系大约类似下面这张图:
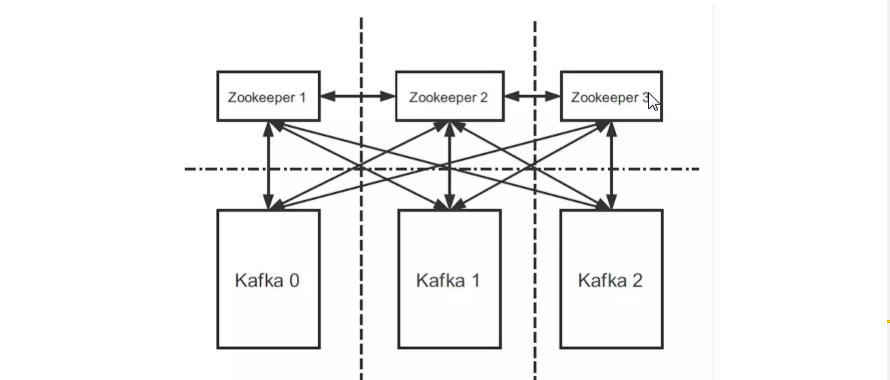
相互的关系不重要, 只要知道 ZooKeeper相当于数据库, Kakka 相当于实例. 双方个体都足够强(有三个节点), 组合起来就更强了.
那Kafka为什么要报zk的大腿呢? 其实是使用zk解决分布一致性的问题. 三个节点分布在三台服务器上, 要保持数据一致, 虽然很多系统是自己维护的, 不过Kafak是叫外援了.
但是, 光有 ZooKeeper 还不够, 自身也要做相当的努力.
Kafka的集群主要是通过数据复制和领袖选举来保证一致性的.
数据复制是指虽然有三个副本, 但只有 leader 对外服务. follower 时刻观察着 leader 副本的动向, 一但有新的变更, 就果断拉给自己.
领袖选举是指如果劳模 leader 不幸挂掉了, 会从 follower 里面选一个最接近的, 荣升新的 leader.
那怎么知道, leader 挂掉了呢, 每个Kafka实例启动后,都会以会话形式把自己注册到ZooKeeper服务中, 一但出了问题, 其与ZooKeeper的会话便不能维持下去了,从而超时失效.
就像上班打卡一样, 一段时间没打卡了, 就知道 leader 凉了.
补充一个名词
ISR: leader 节点将会跟踪与其保持同步的副本列表,该列表称为ISR(In-Sync Replica)
工作流程
知道了集群原理后, 再来看一下工作的流程.
应用程序先连接 ZooKeeper 集群, 获取Kafka集群的一些消息. 其中, 最重要的是知道谁是 leader. 下面的事情就简单了:
- 应用程序把消息发送给 leader
- leader 将消息写入本地文件
- follower 知道后来同步消息
- follower 同步好消息后告诉 leader
- leader 收集到所有副的ACK信号后告诉应用程序
大致的流程就是以上几步, 但还会有一些细节, 同时可以用参数微调.
比方说, leader 不是一收到消息就写入硬盘的, 会有时间或条数的一个阀值. Partiton在物理上对应一个文件夹, 一个分区的多个副本一般不会分配在同一台物理机上等. 而是先反馈给应用还是先保证同步, 消息写到哪个分区, 则时靠参数来控制了.
Kafka有一个重要的特性, 保证消息在单个分区内的顺序. 原因就是 Kafka会单独开辟一块磁盘空间,顺序写入数据. 分区内会有多组segment文件, 满足条件就写入磁盘, 写完就再开新的segment 片段.
消费机制
最后说一下消费, 消费者其实也是应用程序. 其实应用是主动到Kafka拉取消息的. 当然也是找 leader 拉取. 鉴于Kafka的强悍性能, 可以同时加多个消费者, 同时消费者可以组成消费者组. 同一个消费组者的消费者可以消费同一topic下不同分区的数据.
在分区量充足的时候, 可能有一个消费者消费多个分区的情况, 但如果消费都多于分区数量, 可能就有消费者什么事都不做, 躺在一边待机了.所以,不要让消费者的数量超过主题分区的数量.
所有权
客户端崩溃时消息的处理.
- 消费者组共享接收
- 所有权转移 再均衡 rebalance
- 消费者向broker发送心跳来维持所有权
- 客户端拉取数据, 记录消费
日志压缩
- 针对一个topic的partition
- 压缩不会重排序消息
- 消息的offset是不会变
- 消息的offset是顺序
总结
实在抱歉, 感觉有些虎头蛇尾的感觉。 前两节写的很详细, 后面却草草结束。毕竟Kafka是一个中间件, 而不是一个平台。 再深入的话, 就需要写生产架构或叙述业务流程,与初衷不付。毕竟本来打算写一个简单的 Kafka科普的。
先打个挂点吧, 有其他的想法再补充进来。 后面搭 ELK 的时候遇到了再补充一点。
谢谢阅读。
附 Kafka配置文件:
# 创建网络:docker network create --driver bridge --subnet 172.69.0.0/25 --gateway 172.69.0.1 kafka_zoo
version: '2'
services:
broker1:
image: wurstmeister/kafka
restart: always
hostname: broker1
container_name: broker1
ports:
- "9091:9091"
external_links:
- zoo1
- zoo2
- zoo3
environment:
KAFKA_BROKER_ID: 1
KAFKA_ADVERTISED_HOST_NAME: broker1
KAFKA_ADVERTISED_PORT: 9091
KAFKA_HOST_NAME: broker1
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
KAFKA_LISTENERS: PLAINTEXT://broker1:9091
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:9091
JMX_PORT: 9988
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- "/root/kafka/broker1/:/kafka"
networks:
default:
ipv4_address: 172.69.0.11
broker2:
image: wurstmeister/kafka
restart: always
hostname: broker2
container_name: broker2
ports:
- "9092:9092"
external_links:
- zoo1
- zoo2
- zoo3
environment:
KAFKA_BROKER_ID: 2
KAFKA_ADVERTISED_HOST_NAME: broker2
KAFKA_ADVERTISED_PORT: 9092
KAFKA_HOST_NAME: broker2
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
KAFKA_LISTENERS: PLAINTEXT://broker2:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker2:9092
JMX_PORT: 9988
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- "/root/kafka/broker2/:/kafka"
networks:
default:
ipv4_address: 172.69.0.12
broker3:
image: wurstmeister/kafka
restart: always
hostname: broker3
container_name: broker3
ports:
- "9093:9093"
external_links:
- zoo1
- zoo2
- zoo3
environment:
KAFKA_BROKER_ID: 3
KAFKA_ADVERTISED_HOST_NAME: broker3
KAFKA_ADVERTISED_PORT: 9093
KAFKA_HOST_NAME: broker3
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
KAFKA_LISTENERS: PLAINTEXT://broker3:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker3:9093
JMX_PORT: 9988
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- "/root/kafka/broker3/:/kafka"
networks:
default:
ipv4_address: 172.69.0.13
kafka-manager:
image: sheepkiller/kafka-manager
restart: always
container_name: kafa-manager
hostname: kafka-manager
ports:
- "9002:9000"
links: # 连接本compose文件创建的container
- broker1
- broker2
- broker3
external_links: # 连接本compose文件以外的container
- zoo1
- zoo2
- zoo3
environment:
ZK_HOSTS: zoo1:2181,zoo2:2181,zoo3:2181
KAFKA_BROKERS: broker1:9091,broker2:9092,broker3:9093
APPLICATION_SECRET: letmein
KM_ARGS: -Djava.net.preferIPv4Stack=true
networks:
default:
ipv4_address: 172.69.0.10
networks:
default:
external:
name: kafka_zoo
# mkdir -p /root/kafka/broker1
# mkdir -p /root/kafka/broker2
# mkdir -p /root/kafka/broker3
本文由博客一文多发平台 OpenWrite 发布!
发布在平台的文章, 和原文存在格式差异, 阅读不便请见谅





