
前段时间在慕课申请了一个认证作者
就是这个标志
(不要以为我放个慕课认证作者的截图是在ZB,其实我就是在ZB, 你能怎么滴我吧....哈哈哈...........)
申请了作者之后,就想着将csdn的一些历史文章,迁移到慕课上面,首先,手动一个一个地复制进行发布肯定是不现实的,我比较懒,我宁愿不要认证作者也不会去一个一个搬迁. 咨询了一下慕课官方,有没有可以进行文章搬迁的工具,得到的答案很让人失望. 那么大一个系统,竟然连个迁移文章的功能都开发不了,真是让人怀疑慕课的技术实力.没办法...既然没人造轮子,只好自己扭扭手腕,自己造一个吧.谁让我太NB啊....
首先我们先分析一下目前的情况,
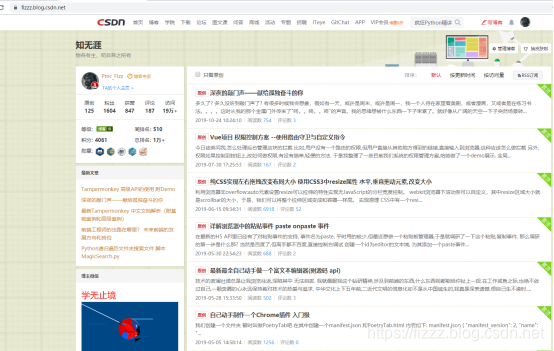
csdn每个作者都有一个文章首页,如下:
分页显示了该作者的所有文章,我们可以使用js脚本很简单地拿到当前页的所有文章链接,文章标题
我们在控制台使用
$('.article-list .article-item-box h4 a').each((i,x) => console.log(x))效果如下
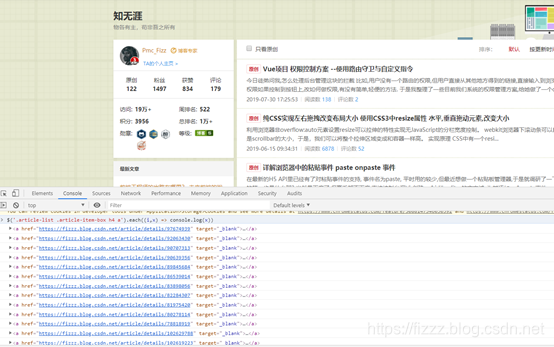
可以获取当前页所有的博客链接
一个用户的博客主页面 如下 https://fizzz.blog.csdn.net/
很简单地就拿到csdn的文章数据
再看慕课这边的发布文章页面,
慕课这个发布文章啊,真是忍不住吐槽,每次发布都要去滑个平图,WTF,那个产品设计出来的....
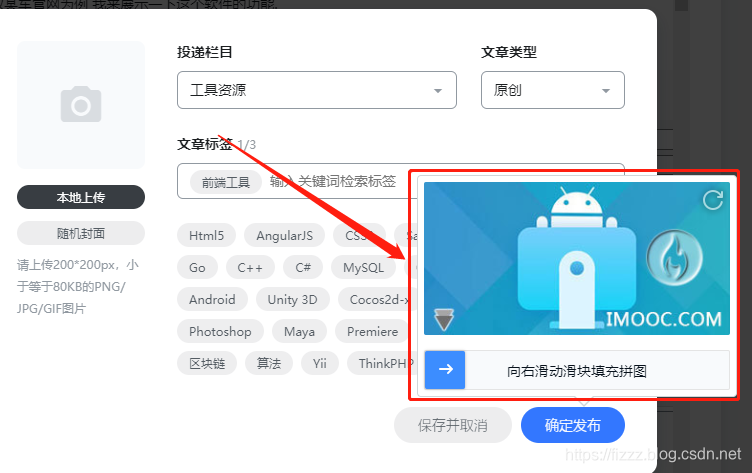
有了这东西之后, 批量发布和自动发布的功能基本死翘翘了.没办法只能一个一个点发布.选中文章标签.发布..
知道了两边的情况后,我们来分析一下技术方案
完美状态下,技术方案应该这样设计,
用户在使用这个工具时,输入一个博客首页的地址,如https://fizzz.blog.csdn.net/
工具根据地址去解析,批量分页获取所有博客标题,内容,地址,存储起来.
在博客首页或者在慕课发布文章页面,注入一个div,显示所有博客,并且每条博客都有,是否已导入这个属性
用户点击一条博客,自动将这条博客的内容填充到慕课的文章编辑器了,一是标题,二是内容,发布成功后将文章自动标记为已搬迁
完美的技术方案是这样的,但现实总是会给你泼冷水的.
他会给你抛出一系列的问题难为你
你怎么分页去取所有的文章?
你用什么存储所有的文章数据?并在两个域名下共同使用,如果使用localStorage还是indexDB都存在跨域问题
你怎么处理文章格式?
你怎么处理csdn里加了防盗链的图片?
....
....
你怎么在工作的百忙之中完整这么牛逼的工具?
遇到问题我不喜欢放弃,我一定要知道困难在那里?那里真的无法实现?有没有变通的方案?真的就没有解决方案吗?前人难道就没有遇到这样的问题?
在所有疑问都得到否定之前,我绝不会停止探索的脚步.这便是我对技术的热情,对所做事情的执著.
让我们一步一步拆分困难,姑且抱着走一步算一步的态度去做这个工具.
经过我的充分的思考,仔细评估了一下完美技术方案的难度,和要耗费的时间,
我觉得,先把最简单地功能,最核心的功能做出来把,即产品中的MVP ---最小可行性产品
所以技术方案改为以下
进入一篇csdn文章的页面,在文章底部注入一个搬迁按钮
点击搬迁按钮,获取当前文章的标题和内容,并打开慕课发表文章页面
将获取的文章标题和内容填充进去
思考够了就捋捋袖子,开始干吧...
看到这里的朋友大概会有人说我,真是啰嗦,写了几千字还不知道你用啥技术写工具,代码也没贴一行,但我向对你说的是,作为一名软件开发工程师,设计思路永远要比编码重要的,重要地多,多地多....除了设计思路还有两个技能也是非常重要,下文也会体现出来.
首先我选择的是Tampermonkey 这个浏览器插件来进行写脚本,脚本当然是js语言编写.至于为什么选择它,我这里就不做过多的介绍了,有兴趣的朋友可以去搜索一下Tampermonkey, 前端是个包揽万物的职位,知识的宽度可以决定你有多少种解决方案.(认真的同学已经拿笔记下来了,这是鲁迅先生说的一句话)
为了使用Tampermokeny 我先去看官网看了一天的API,(我们是996,白天和晚上都没有时间,我是周日看了一天) 将所有基础api和高级api都尝试了一遍,并写下了两篇博客,
以下:
最新Tampermonkey 中文文档解析(附基础案例和高级案例)
总的来说还有很大收获的,比如,TM提供了一种数据存储的方式使用GM_*function 高级函数
具体是这几个

这种存储方式不被js跨域安全策略所限制,完美解决多tab也,数据共享的问题.具体存储到哪里我也不知道.
另外还可以使用
unsafeWindow
对象来访问页面的js函数和变量,但考虑到大部分js都是压缩,并封装了,实际用处要小很多.
其他高级用法都去上面两篇文章里去找吧. 不要做伸手党.别人给的不一定是你要的.
按照最简单地技术方案,我用两行简单的代码就获取了博客的标题和内容,就是这样简单
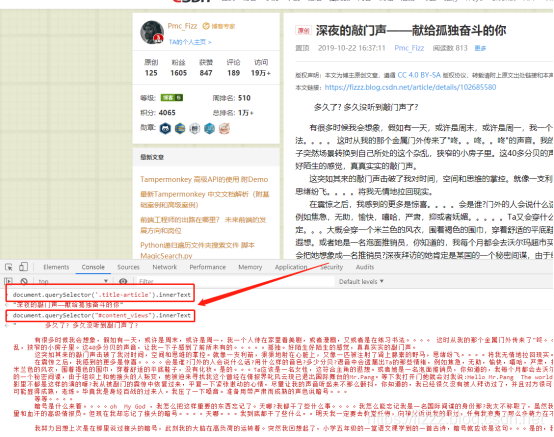
这里不得不说一下,这里我踩了两个坑,
一开始我是想着使用js来模拟鼠标选中文章内容的事件,之所以会这样设计,是因为当我用鼠标选中文章内容复制,再粘贴到慕课的编辑器里,格式,图片什么的都有,而且表现也比较良好,除了文章中的代码.所以我就想着使用js选中选中文章内容,然后再执行复制命令,后来才发现,我真是一个大笨蛋.按照这个错误的思路我搜索了选中事件,发现只能在input和textarea中使用,我总不能用js把文章内改成一个文本域textarea,差点就这么做了.在这个错误的技术实现上浪费很多时间后,我觉得先用innerText 试试,不管怎么说先获取文章的字体内容吧,图片晚点再考虑吧.
于是就这样我获取了文章的标题和内容文本
获取数据后就用 TM的GM_setValue存储吧,这一步水到渠成,
数据存好了就打开慕课的文章发布页面折腾呗,于是在调用TM的GM_openInTab 打开一个聚焦的子窗口. 这一步也是自然天成.
好了到了最后一步,将数据填充到慕课的编辑器中
文章标题很好操作,
document.querySelector("#article_title").value = '文章的标题就是我'但是下面的这个富文本编辑器怎么办啊, 这是一个难题啊,这个工具的最难难的部分.
我们知道富文本编辑器 都有一套自己的api,操作编辑器中内容,如获取编辑器的内容,设置编辑器的内容, 归根节点我们要找的是慕课这个编辑器的设置内容的api, 先不谈能不能找到知道编辑器的对象.
那么问题的难点就转化为了寻找编辑器设置内容的api
那么问题来了,什么慕课到底用的是什么编辑器啊?
于是问题就变成了,慕课 到底用的是什么富文本编辑器?
既然要找答案,那就去看代码吧
F12搞起来.
细心而认真的同学很快就能找到答案.
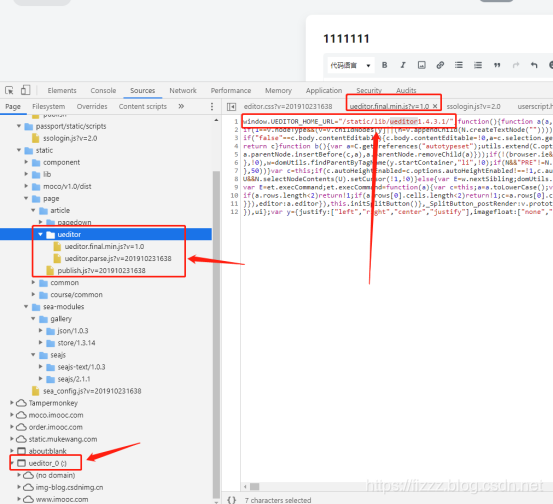
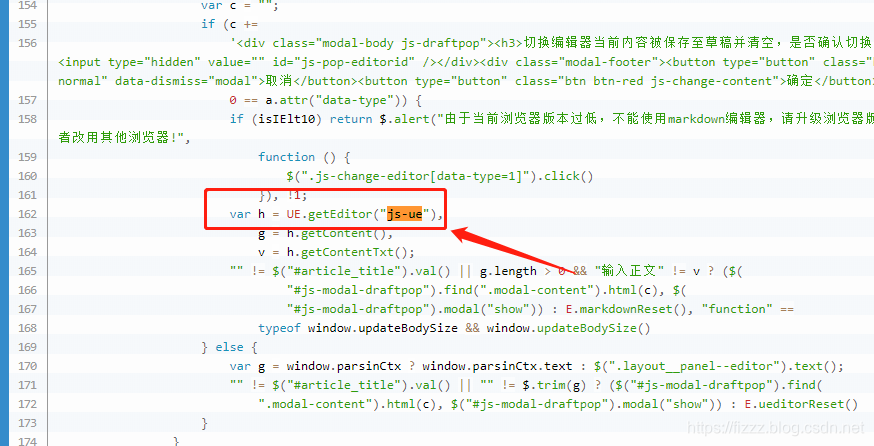
代码里有很多证据都指向了同一个编辑器 ueditor 条条大路通罗马,柳暗花明又一村.我们找到了答案,目前慕课用的富文本编辑器是百度家生产的ueditor
ueditor官网 可以看到这东西很多没更新了,16年5月份发了最新的一版,就不再维护了.
在UEditor文档中我们很容易就找到来我们需要的api 设置编辑器内容的api

UE.getEditor('container').setContent('其实要填写编辑器的内容');找了api那我们就在控制台试试能不能用吧,是骡子是马牵出来溜溜
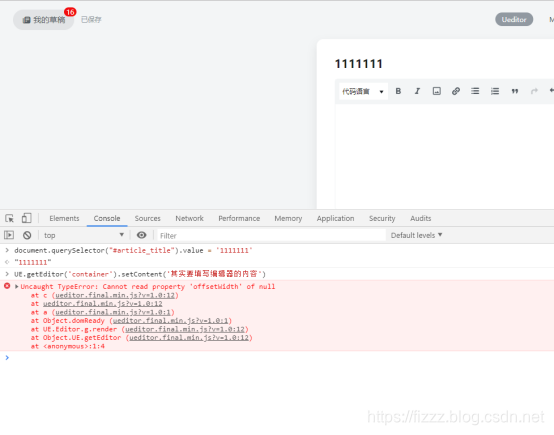
这一试还真是发现了问题,看错误信息,是已将找到了UE的对象了, 要不然错误堆栈不会由ueditor产生. 就是有个对象没有 offsetWidth 这个属性, 我稍微发挥一下想象力并结合这行代码,
这行代码实际变量只有两个一个container 一个'其实要填写编辑器的内容 ' 那么问题只能出现在这个"container" 变量上. 这个变量就是富文本编辑器的容器id,用于生成富文本编辑器的dom元素id, 在这个页面找不到 id为"container"的元素,就是说慕课的富文本编辑器的容器id不是container, 那是什么那? 答案我们还是需要在源码里寻找. 分析吧
写到这里大家应该知道作为软件工程师的第二个重要技能了吧,对
就是分析能力 分析能力即是能够透过现象看本质,找到问题的本源,清楚地理清各个部分之间的联系.这是一个很厉害的能力,能不能成为中高级程序员,这个能力很关键.希望各位同学拿笔记下来.
分析呗,F12还没关,打开选中编辑器的节点看看dom结构,

根据这个节点往上找吧,不要问我为啥往上找,而不是往下找,自己思考.我都给你嚼明白,你吃这还有什么味道啊
当我们看到这一行dom时就要提起精神了,从这个dom的有id和calss分析,这个id很有可能就是我们要寻找的富文本编辑器的容器id
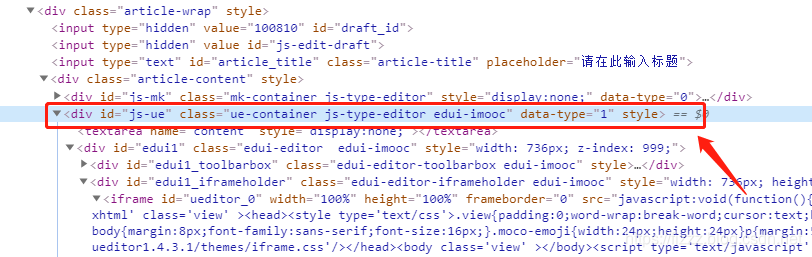
有的同学会问,为啥下面下面的edui1 或者edui_toolbarbox 其实很好排除这个两个 一是鼠标放上去,二是使用
UE.getEditor('container').setContent('其实要填写编辑器的内容');这行代码测试,有的人会问,如果这个编辑器上面有很多id,我就是找不到编辑器的容器id,怎么办? 很简单 那就一个一个试吧,
牛顿发明灯泡的时候,试了几千种材料,才发现钨丝是最适合做灯泡的材料
如果你多去尝试几种可能性,你都不愿意,那你真是不适合做探索,扩展工作.实验的次数多了,你就会养成一种直觉,问题就出在这里,这个id就是我要找的东西,我要的东西就在这个对象里面. 这种直觉和经验在经历多次探索后自觉地养成.我称之为: 程序员的隐形查克拉 哈哈....
言归正传,js-ue 到底是不是编辑器的容器id我们一试便知

看到这个结果是不是很激动,很兴奋,想鼓掌,想喝彩.....哈哈哈.....
我也是.
截止到这里我们已经接近了技术方案的所有问题
那就编写代码走一下彩排吧
我迅速地写好代码,执行.结果,效果很差劲
使用innerText获取的文章内容,在填充到慕课编辑器中时,会出现格式错误.并且没有相应的图片,
源文章格式与迁移后文章格式对比

看到这样的结果,我心里心里失望极了.为什么?为什么要这样对我? 努力了那么久,到头来,还是这个样子, 这样的工具根本不会有人用,文章排版全都错了,而且没有图片.毫无美感而言,文章也无法阅读.
苍天啊, 大地啊,你为何要这样对待一个前端工程师?我到底前世做错了什么事情?才让你这样折磨我? 你让我的头发日益稀疏,你让我的颈肩日益畸形,你让痘痘爬满我的脸,你让公交天天堵着,让我天天迟到....
我不服.我不服,我一万个不服.....我只想想为社会主义共同理想做自己的一份贡献,为了让人们节省时间,做自己喜欢的事,你为什么要处处和我作对,让我连最小可行性产品也无法做出来,我努力了那么久,就换来了这样一个结果.
骂天骂地之后,我又恢复了作为一名战士的仪态.活还要继续干.
天行贱,君子当以自强不息
我仔细分析代码,并在脑海中飞速地过滤自己以前学的前端知识
最后,一道闪电在我脑海中闪过, UEditor这个编辑器不是可以直接设置html嘛? 卧槽,卧槽,卧槽....
这段代码只要修改一个单词就效果就可以翻天覆地,从狂风暴雨瞬间变成春光明媚,
我小心翼翼的把原有的单词删掉,又小心翼翼地写下新单词, ctrl+s 保存,
刷新页面,点击搬迁按钮. 我赶紧闭上眼睛,不敢看即将出现的结果.我怕自己再次失望.再次身处失望的深渊.绝望.
在做了几次深呼吸后,我慢慢地,慢慢地睁开了一只眼,
哇!!!!!!!
突然我体会到了哥伦布发现新大陆的兴奋了,抗日战争胜利的喜悦,新中国成立的自豪, 哈哈哈哈.........
源文件与迁移后的文章对比
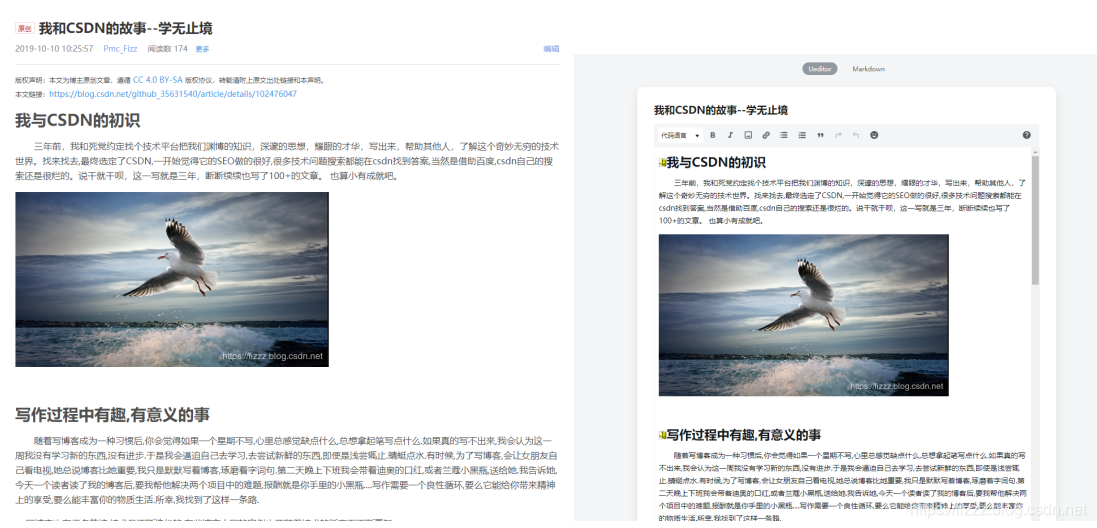
perfect!!!
我的心情久久不能平静,除了感叹自己的聪明才智外,更多的是对技术的敬畏.
相信很多读者已经猜到了答案,
将获取文章的innerText 改为innerHTML
直接获取文章内容的dom结果,填充到编辑器里,效果是最棒的.不仅格式正确,而且图片也出现了,
看到这里的人肯定已经等不及要源码了
部分源码如下:
// ==UserScript==// @name C2M// @namespace http://tampermonkey.net/// @version 0.1// @description copy csdn article to imooc// @author Fizz// @match *://www.imooc.com/article/publish// ==/UserScript==(function() { 'use strict';const mukPulicArticleUlr = `https://www.imooc.com/article/publish#`let body = document.querySelector('body')let injectDiv = document.createElement('div')injectDiv.classList.add('myinject')injectDiv.innerHTML = `搬迁`injectDiv.onclick = function (e) {let articleContent = document.querySelector("#content_views").innerHTMLlet title = document.querySelector('.title-article').innerText// 使用GM_setValue存储文章数据// ......}// 注入的样式,搬迁按钮的样式let injectStyle = ` .myinject{ width: 50px; height: 50px; border-radius: 50%; background-color: #fec04e; border-color: #fec04e; position: fixed; bottom: 20px; right: 20px; opacity: .6; color: brown; line-height: 50px; vertical-align: middle; text-align: center; cursor: pointer; } .myinject:hover{ opacity: 1; color: #fff; }`GM_addStyle(injectStyle)let href = location.href// 根据当前url判断 是慕课发布文章页面还是csdn博客文章详情页页面 从而进行不同的操作// ....})();
分析了那么久,一共写了73行代码,包括注释和空行.重要的是这个分析,调试的过程. 是不是很有意思啊.
脚本效果:
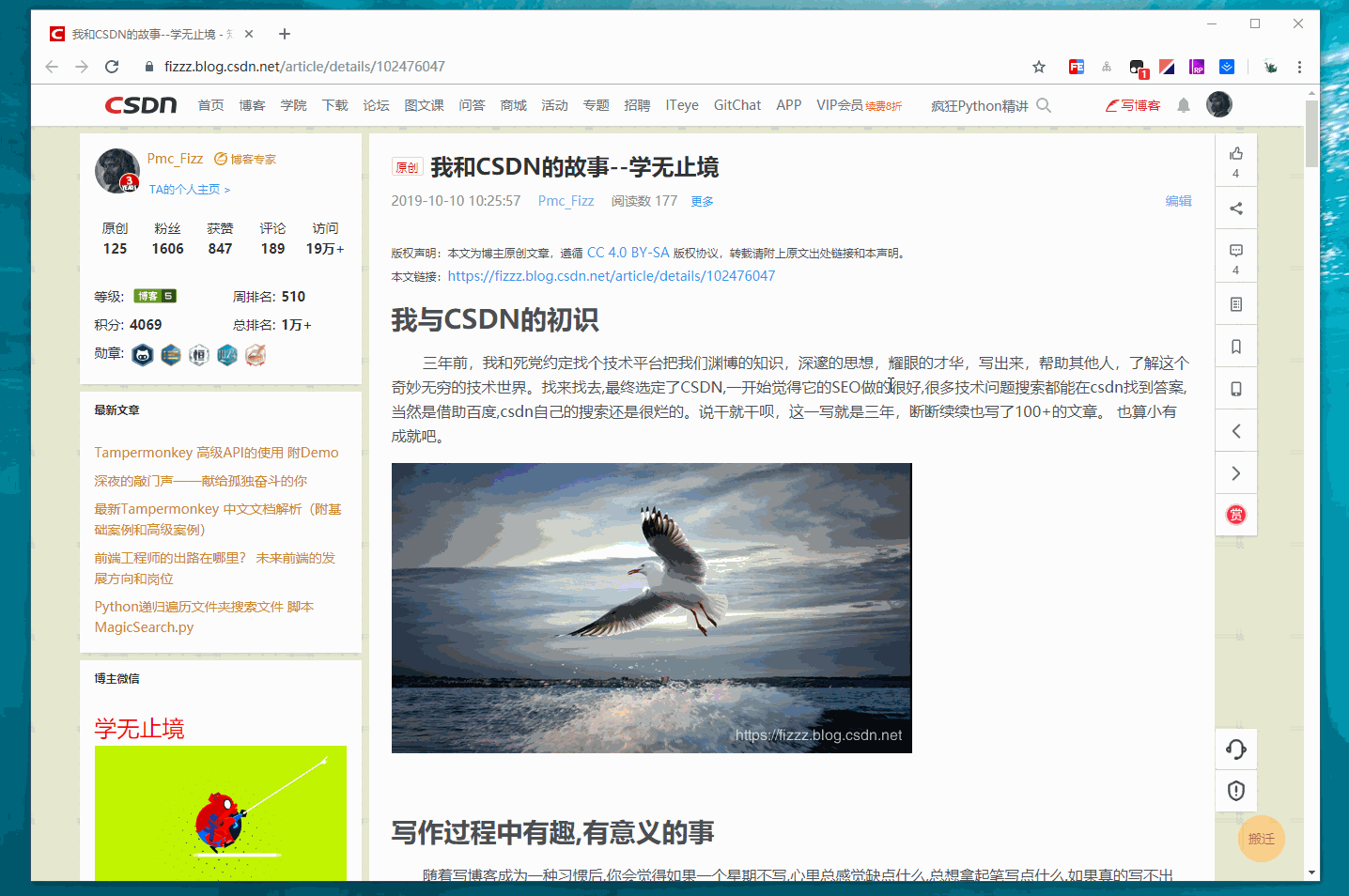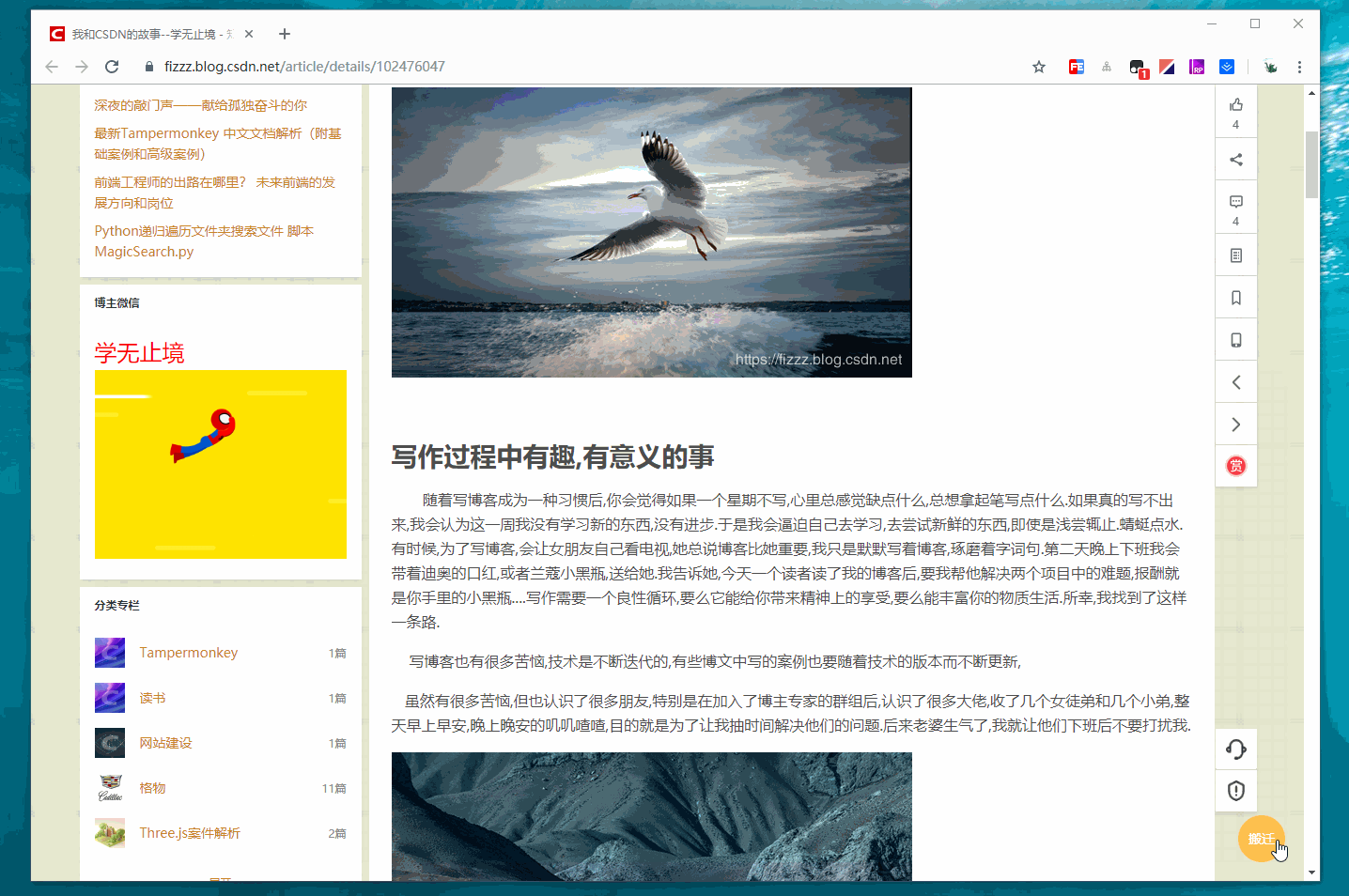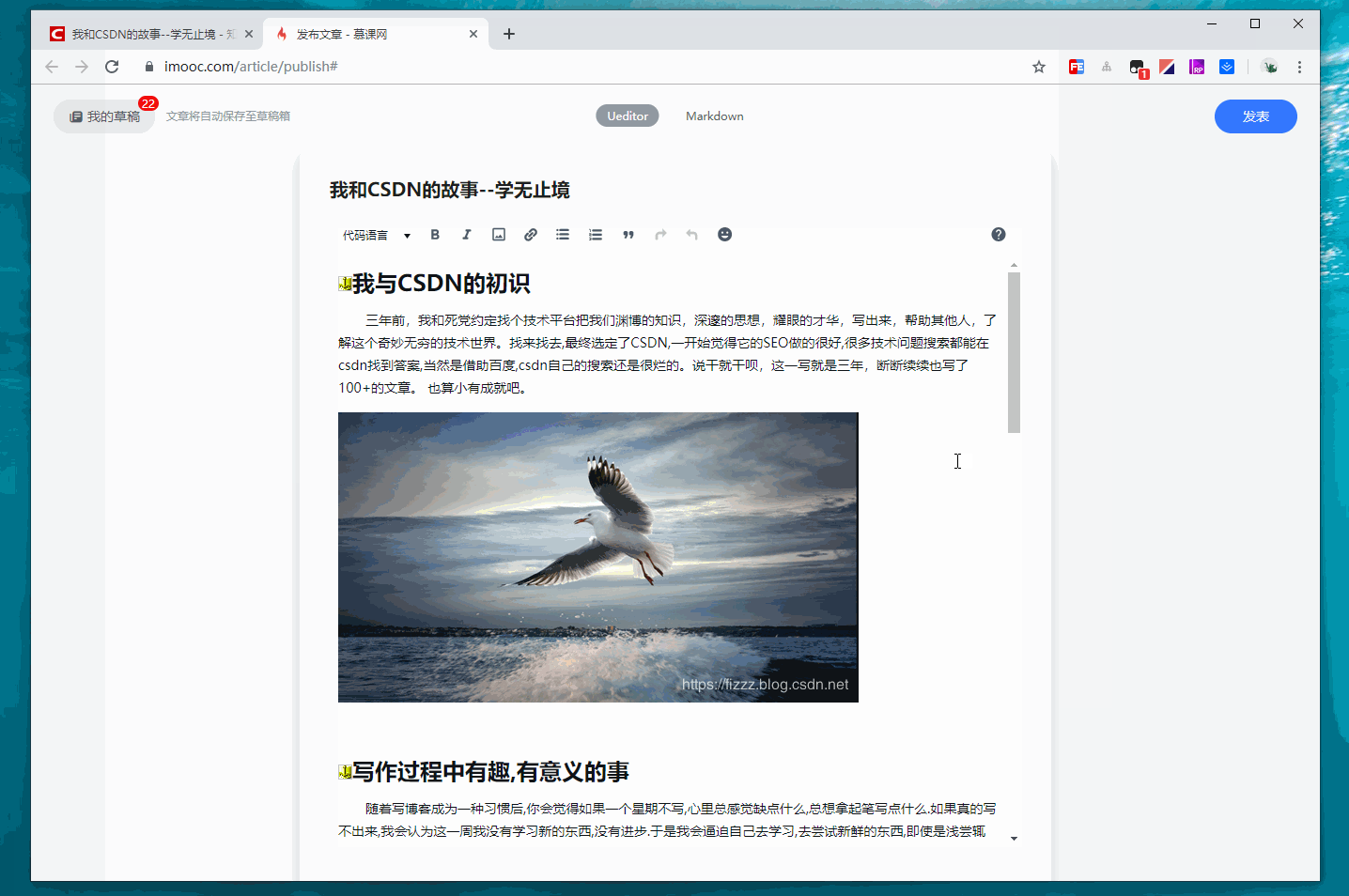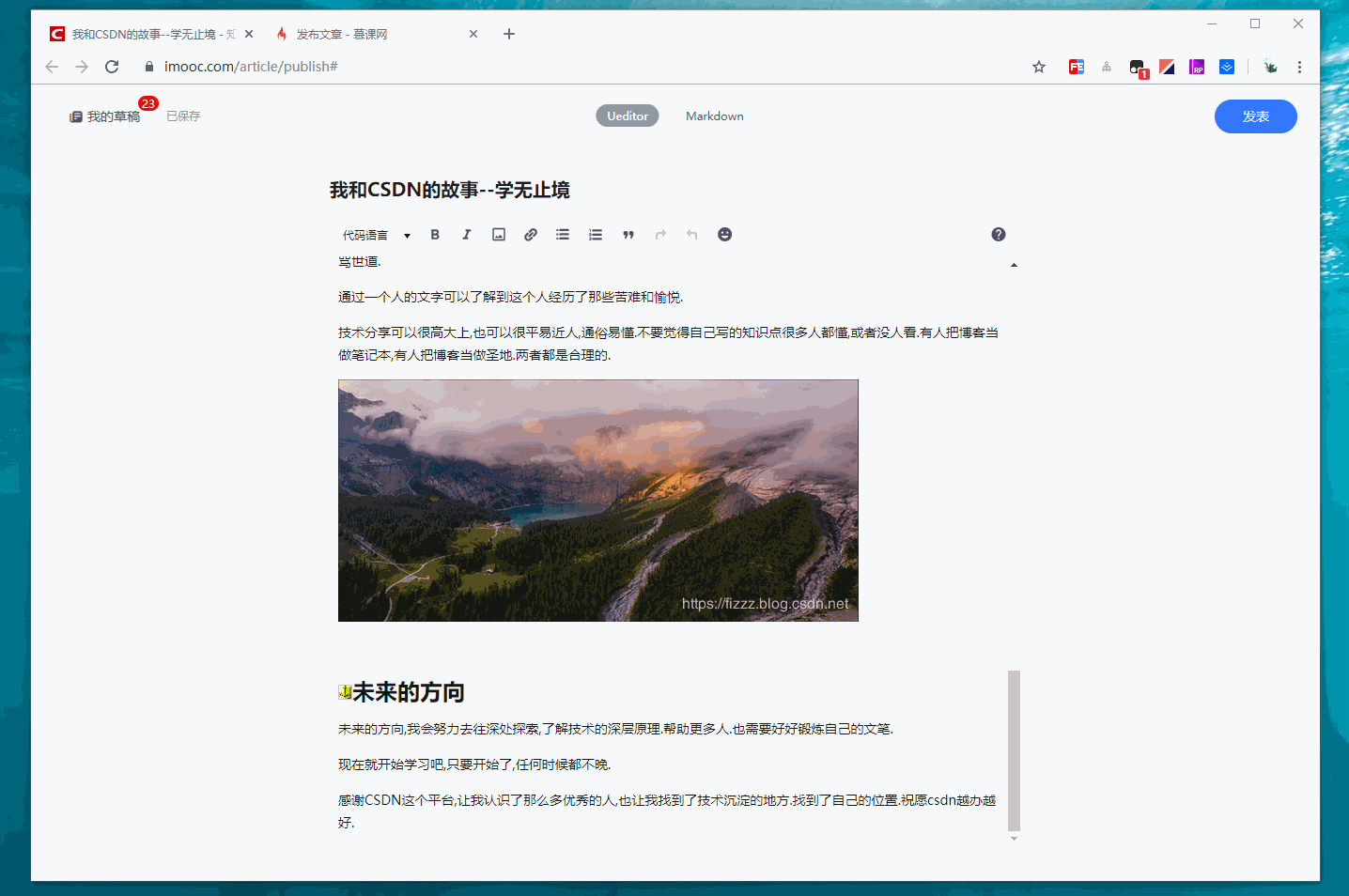
写到这里已经接近尾声了,现在是2019年10月26日01:55:49 今天项目上线,我留守公司,保证项目顺利上线,不知道正在读文章的你在干嘛?总是那么长的文章,不可能一次性读完吧. 能读到这里的人我们加个好友吧,英雄惜英雄.
祝君,所向披靡,斩尽人间bug.






