
泰坦尼克号幸存者项目是kaggle的入门项目,我先用python的matplotlib库对数据进行了可视化,初步探索后对数据进行了清洗,然后建立了逻辑回归模型对测试集进行了预测,kaggle得分是0.76076。
对数据进行统计并可视化
import pandas as pd
import numpy as np
data_train=pd.read_csv("D:/Titanic/data/train.csv")
print(data_train.info())#查看数据缺失情况
print(data_train.describe())#查看数据基本统计信息输出为:
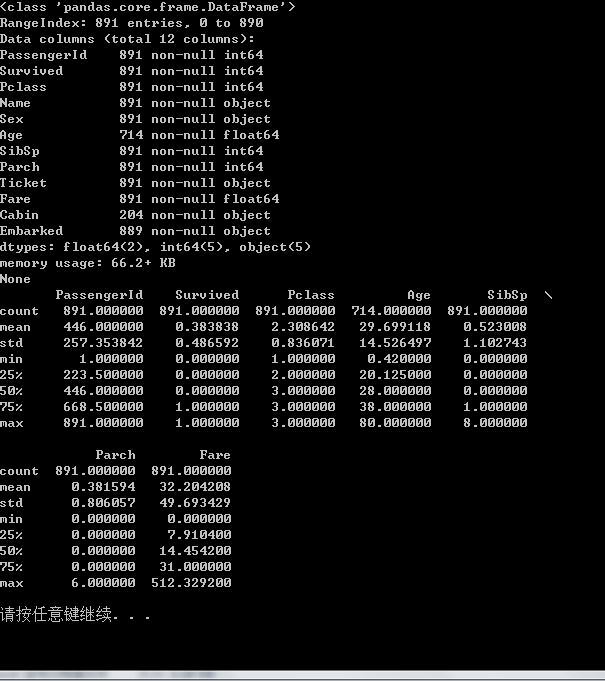
用info函数来查看数据缺失信息。这艘船共有891个乘客,每个乘客都有12个属性。其中Age只有714个人有信息,缺失177个数据,而Cabin(客舱)则只有204个数据。
用describe函数来查看基本的统计信息。发现幸存者占乘客的2/5,乘客平均年龄是29岁。为了进一步的来分析数据,我用matplotlib函数对这些数据进行了可视化。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pylab import *
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
data_train=pd.read_csv("D:/Titanic/data/train.csv")
#查看各乘客等级的获救情况
survived_0=data_train.Pclass[data_train.Survived==0].value_counts()
survived_1=data_train.Pclass[data_train.Survived==1].value_counts()
df=pd.DataFrame({'获救':survived_1,'未获救':survived_0})
df.plot(kind='bar',stacked=True)
plt.title('各船舱乘客获救情况')
plt.xlabel('船舱等级')
plt.ylabel('人数')
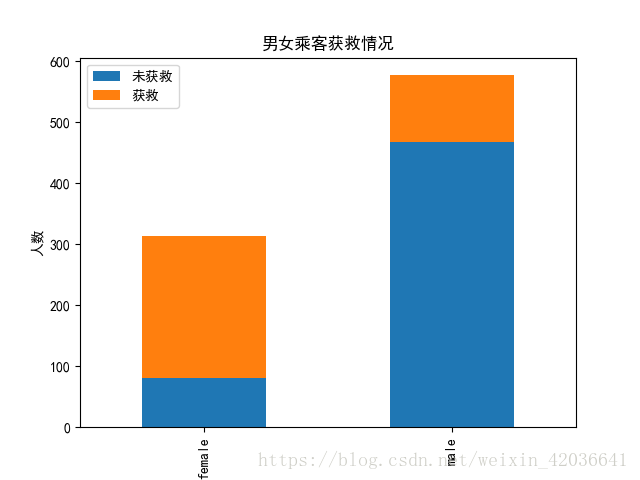
#查看性别的获救情况
survived_0=data_train.Sex[data_train.Survived==0].value_counts()
survived_1=data_train.Sex[data_train.Survived==1].value_counts()
df2=pd.DataFrame({'获救':survived_1,'未获救':survived_0})
df2.plot(kind='bar',stacked=True)
plt.title('男女乘客获救情况')
plt.xlabel('性别')
plt.ylabel('人数')
# #查看各船舱级别下的男女获救情况(方法一)
# fig=figure()
# fig.add_subplot(131)
# survived_0_one=data_train.Sex[data_train.Survived==0][data_train.Pclass==1].value_counts()
# survived_1_one=data_train.Sex[data_train.Survived==1][data_train.Pclass==1].value_counts()
# df2=pd.DataFrame({'获救':survived_1_one,'未获救':survived_0_one})
# df2.plot(kind='bar',stacked=True)
# plt.title('头等舱')
# plt.xlabel('性别')
# plt.ylabel('人数')
# fig.add_subplot(132)
# survived_0_two=data_train.Sex[data_train.Survived==0][data_train.Pclass==2].value_counts()
# survived_1_two=data_train.Sex[data_train.Survived==1][data_train.Pclass==2].value_counts()
# df4=pd.DataFrame({'获救':survived_1_two,'未获救':survived_0_two})
# df4.plot(kind='bar',stacked=True)
# plt.title('二等舱')
# plt.xlabel('性别')
# plt.ylabel('人数')
# fig.add_subplot(133)
# survived_0_three=data_train.Sex[data_train.Survived==0][data_train.Pclass==3].value_counts()
# survived_1_three=data_train.Sex[data_train.Survived==1][data_train.Pclass==3].value_counts()
# df5=pd.DataFrame({'获救':survived_1_three,'未获救':survived_0_three})
# df5.plot(kind='bar',stacked=True)
# plt.title('三等舱')
# plt.xlabel('性别')
# plt.ylabel('人数')
#查看各船舱级别下的男女获救情况(方法二)
fig=figure()
plt.subplot(141)
data_train.Survived[data_train.Sex=='female'][data_train.Pclass==3].value_counts().sort_index().plot(kind='bar',color='pink')
plt.xticks(arange(2),['未获救','获救'])
plt.yticks(arange(0,301,50))
plt.legend(['低等舱/女生'],loc='best')
plt.subplot(142)
data_train.Survived[data_train.Sex=='female'][data_train.Pclass!=3].value_counts().sort_index().plot(kind='bar',color='hotpink')
plt.xticks(arange(2),['未获救','获救'])
plt.yticks(arange(0,301,50))
plt.legend(['高等舱/女生'],loc='best')
plt.subplot(143)
data_train.Survived[data_train.Sex=='male'][data_train.Pclass==3].value_counts().sort_index().plot(kind='bar',color='lightsteelblue')
plt.xticks(arange(2),['未获救','获救'])
plt.yticks(arange(0,301,50))
plt.legend(['低等舱/男生'],loc='best')
plt.subplot(144)
data_train.Survived[data_train.Sex=='male'][data_train.Pclass!=3].value_counts().sort_index().plot(kind='bar',color='cornflowerblue')
plt.xticks(arange(2),['未获救','获救'])
plt.yticks(arange(0,301,50))
plt.legend(['高等舱/男生'],loc='best')
fig.tight_layout()
plt.show()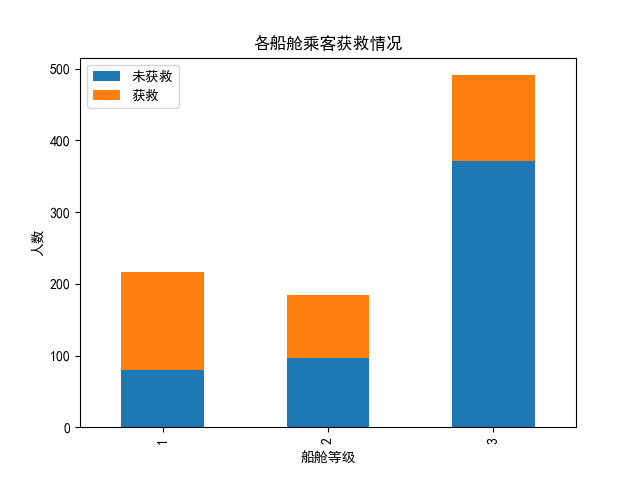
从这张图中可以看出高等舱获救的人最多,获救机会跟个人财力是有关系的。
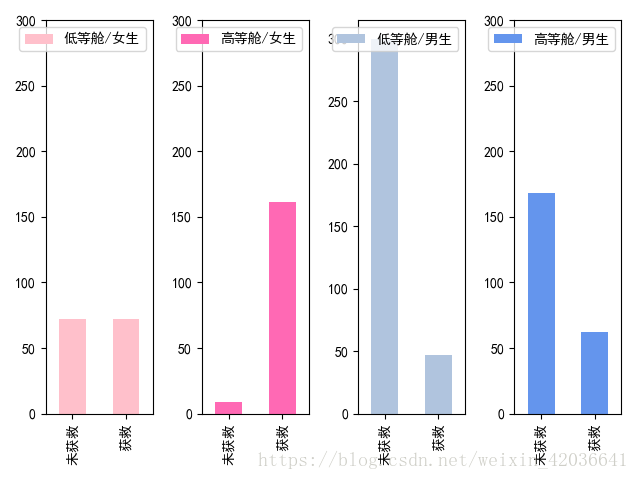
从总体来看,女性获救的机会比男生大。我猜想救援时也遵循了女士优先的原则。正常情况下是女士和小孩优先,所以年龄对获救机会也有影响,为了验证,接下来继续分析。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pylab import *
fig=figure()
fig.set(alpha=0.2)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
data_train=pd.read_csv("D:/Titanic/data/train.csv")
plt.subplot(341)
data_train.Survived.value_counts().plot(kind='bar')
plt.title("获救情况(1为获救)")
plt.ylabel("人数")
plt.subplot(342)
data_train.Pclass.value_counts().plot(kind='bar')
plt.title("乘客等级分布")
plt.ylabel("人数")
plt.subplot(344)
y=data_train.Age
x=data_train.Survived
plt.scatter(x,y)
plt.title("按年龄看获救分布(1)为获救")
plt.ylabel("年龄")
plt.subplot(312)
y=data_train.Age.value_counts()
y.sort_index().plot(kind='bar')
plt.xlabel("年龄")
plt.ylabel("人数")
plt.title("各年龄的乘客人数")
plt.subplot(313)
data_train.Age[data_train.Pclass==1].plot(kind='kde')#密度图
data_train.Age[data_train.Pclass==2].plot(kind='kde')
data_train.Age[data_train.Pclass==3].plot(kind='kde')
plt.xlabel("年龄")
plt.ylabel("密度")
plt.title("各等级的乘客年龄分布")
plt.legend(('头等舱','二等舱','三等舱'),loc='best')
plt.subplot(343)
data_train.Embarked.value_counts().plot(kind='bar')
plt.title("各登船口岸上船人数")
plt.ylabel("人数")
#subplots_adjust(wspace=0.5,hspace=1)#也可以调节各图形之间的间距
fig.tight_layout()#自动调整各图形之间的间距
plt.show()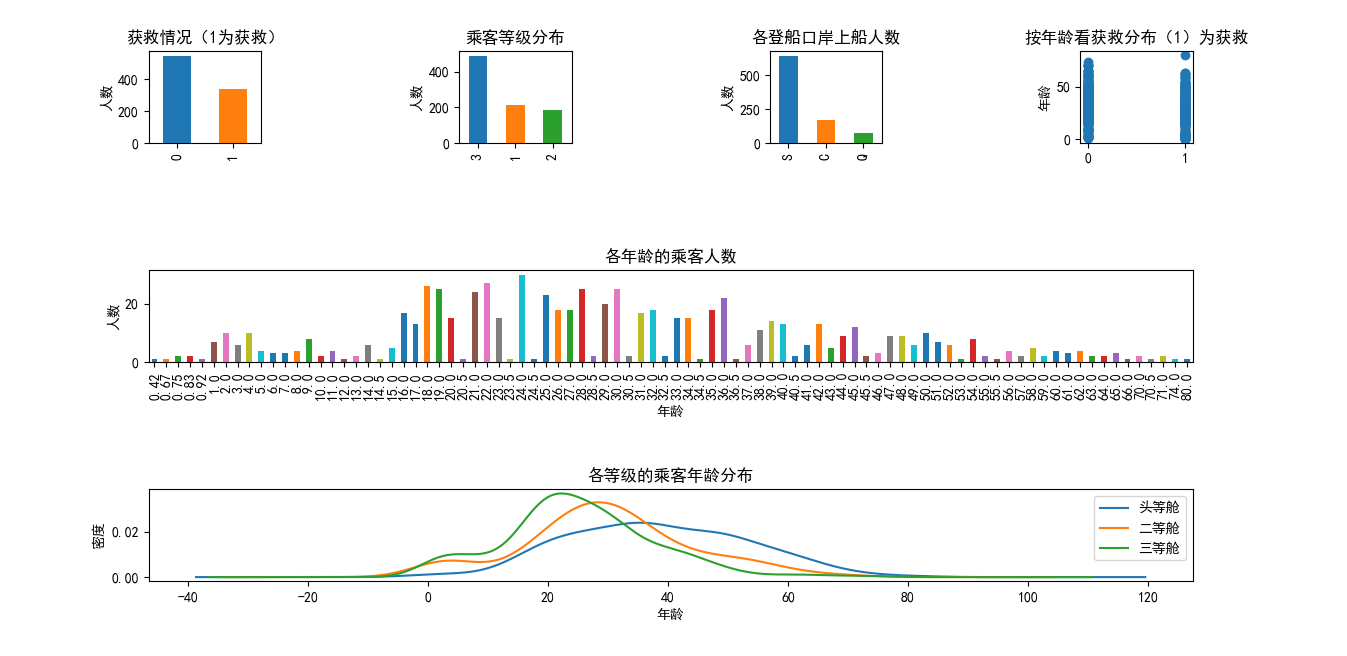
综上所述,对于乘客的获救情况,我们大致可以得出以下结论:
1.高等仓获救的机会大于低等舱
2.女性获救的机会大于男性
3.获救的几率与年龄有关
4.高等仓的平均年龄大于低等舱
2.数据预处理
通过第一步的info函数查看数据的缺失情况,发现Age(年龄)缺失的数据较少,所以采用插值法来处理。用到的插值方法是随机森林。而Cabin(船舱号)则缺失了约3/4,而船舱号码暂时看不出来对获救有什么影响,所以我选择了对其进行数值化,有船舱号的值记为为1,没有船舱号的记为0。同样,为了方便后面的建模,我需要对非数值的属性Sex(性别),Embarked(登舱口),Name(名字),Ticket(票号)进行同样的数值化处理。这里用到了pandas库中的dummies函数。
from sklearn.ensemble import RandomForestRegressor
import numpy as np
import pandas as pd
from sklearn import preprocessing
data_train=pd.read_csv("D:/Titanic/data/train.csv")
# 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
age_df=df[['Age','Fare','Parch','SibSp','Pclass']]
known_age=age_df[age_df.Age.notnull()].as_matrix()
unknown_age=age_df[age_df.Age.isnull()].as_matrix()
y=known_age[:,0]#第一列所有元素
x=known_age[:,1:]#分割出矩阵第二列以后的所有元素
rfr=RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1)
rfr.fit(x,y)
predictedAges=rfr.predict(unknown_age[:,1:])
df.loc[(df.Age.isnull()),'Age']=predictedAges#loc通过行标签来索引数据
return df
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
return df
data_train = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
data_train.to_csv('processed_data1.csv')#新文件夹没有空值
dummies_Cabin=pd.get_dummies(data_train['Cabin'],prefix='Cabin')
dummies_Embarked=pd.get_dummies(data_train['Embarked'],prefix='Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)#增加列属性,concat默认是增加行,axis=1为增加列
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)#drop为删除原来的列,axis=1为删除列
df.to_csv('processed_data2.csv')#新文件夹的数据都为数值型,对原数据进行了特征因子化处理后的数据如下:
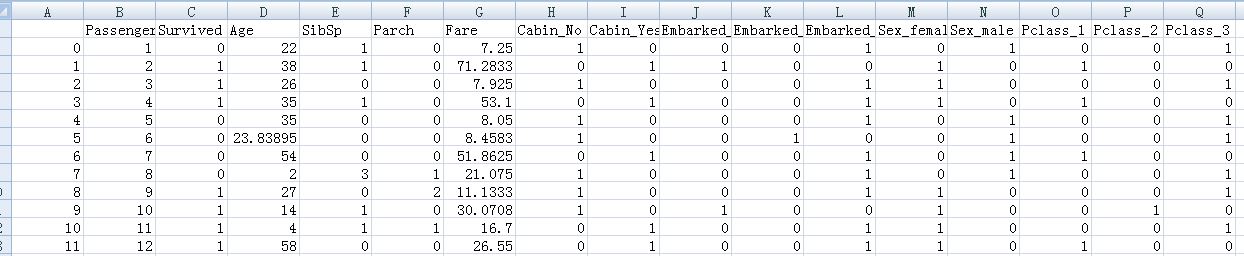
此时数据都为数值型,但一些值的变化范围太大,如Fare,Age等,需要对其进行规范化处理,我采用的是零—均值规范化。
#将Age和Fare两个属性进行零——均值标准化。
scale_age=(df['Age']-df['Age'].mean())/df['Age'].std()
scale_fare=(df['Fare']-df['Fare'].mean())/df['Fare'].std()
df.copy()
df['Age']=scale_age
df['Fare']=scale_fare
df.to_csv('processed_data3.csv')输出的文件部分如下图所示:

3.构建逻辑回归模型并进行预测
由于测试集的数据也是有缺失的,所以我先对测试集进行了和训练集同样的数据清洗工作,然后才开始了建模。
from sklearn import linear_model
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
from sklearn import preprocessing
from datapreprocessing import set_Cabin_type
df=pd.read_csv("D:/Titanic/processed_data3.csv")
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到LogisticRegression之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
####对测试数据同样进行数据预处理
data_test = pd.read_csv("D:/Titanic/data/test.csv")
data_train=pd.read_csv("D:/Titanic/data/train.csv")
#构建同一个随机森林
age_df=data_train[['Age','Fare','Parch','SibSp','Pclass']]
known_age=age_df[age_df.Age.notnull()].as_matrix()
unknown_age=age_df[age_df.Age.isnull()].as_matrix()
y=known_age[:,0]#第一列所有元素
x=known_age[:,1:]#分割出矩阵第二列以后的所有元素
rfr=RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1)
rfr.fit(x,y)
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
data_test.to_csv('processed_test_data1.csv')#新文件夹没有空值
#将Age和Fare两个属性进行零——均值标准化。
scale_age=(df['Age']-df['Age'].mean())/df['Age'].std()
scale_fare=(df['Fare']-df['Fare'].mean())/df['Fare'].std()
df.copy()
df['Age']=scale_age
df['Fare']=scale_fare
df.to_csv('processed_test_data2.csv')
#用逻辑回归模型做预测
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_predictions.csv", index=False)预测的结果部分如下:
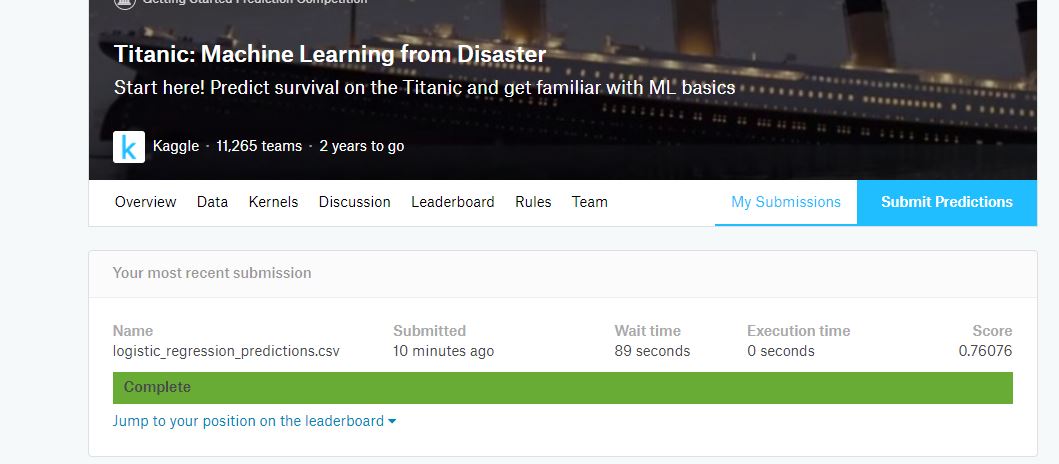
最后就是在kaggle上提交自己的结果,我的评分为0.76076。
做预测时我只是简单的构建了一个逻辑回归模型,没有对其进行优化。随着进一步的学习,有能力的话会对其进行检验并优化。








