
写在前面:开始数据挖掘的学习已有一段时间,由于研究生阶段一直使用C++,代码的熟练度还远远不够,对算法的理解也不够深刻。因此,想要写点东西记录自己学习的过程,希望可以在积累中不断提升自己。
今天写一写最近几天爬取分析拉勾网岗位数据的过程,用到了python数据整理常用的pandas库、可视化操作的matplotlib和seaborn库、爬虫算法常用框架scrapy。
建立爬虫框架
学习scrapy时主要参考了这篇博文:【图文详解】scrapy爬虫与Ajax动态页面——爬取拉勾网职位信息(1)
观察拉勾网网页及源代码发现,结构为主页——职位分类——职位列表——具体职位信息,我们尝试爬取“数据挖掘”分类下的所有职位信息,首先建立爬虫框架:
spiders文件
观察网页地址发现,数据挖掘分类下第一页职位列表的地址为http://www.lagou.com/zhaopin/shujuwajue/1/?labelWords=label,后面的网页只修改了地址中的数字(即页码),其他不变。
class LgjobsSpider(scrapy.Spider):
name = "lgjobs"
start_urls = ( 'http://www.lagou.com/zhaopin/shujuwajue/1/?labelWords=label',# 'http://www.lagou.com/',
)
totalpageCount=1
def start_requests(self):
return [scrapy.http.FormRequest('http://www.lagou.com/zhaopin/shujuwajue/1/?labelWords=label', callback=self.parse)]观察职位列表页的源代码和职位详情页的源代码发现,二级网页的源代码更容易提取,包含的信息也更全面,因此选择首先在网页内爬取二级网页的地址,再由二级网页爬取所需的职位信息。 

def parse(self, response):
selector = scrapy.Selector(response)
next_urls = selector.xpath('//a[@class="position_link"]').extract() for each in next_urls:
urls = re.findall(r'href="//(.*?)"', each, re.S) yield scrapy.Request('http://' + urls[0], self.parse_item)
self.totalpageCount += 1
next_page='http://www.lagou.com/zhaopin/shujuwajue/'+str(self.totalpageCount)+'/?labelWords=label'
if self.totalpageCount<31: yield scrapy.Request(next_page, callback=self.parse) def parse_item(self, response):
selector = scrapy.Selector(response)
skill = selector.xpath('//dd[@class="job_bt"]/p').extract()
tf = open('./' + 'datamining.txt', 'w+') for each in skill:
res = re.sub('<.*?>', '', each)
tf.write(res)
tf.close()修改items.py
我们需要存储的特征信息有:公司名称、薪酬、工作经验、学历、工作城市等,添加函数:
class LagoujobsItem(scrapy.Item): salary=scrapy.Field() city=scrapy.Field() companyFullName=scrapy.Field() jobNature=scrapy.Field() education=scrapy.Field() financeStage=scrapy.Field() positionName=scrapy.Field() createTime=scrapy.Field() positionName=scrapy.Field() pass
修改settings.py
为了防止爬取数据时访问过于频繁导致IP被封禁,在settings.py中添加代码:
DOWNLOAD_DELAY=1
但是这种方法会严重影响爬虫的速度,并不是很好。
另外,添加数据存入的文件位置:
FEED_URI = u'file:///D://lagouzhaoping.csv'FEED_FORMAT = 'CSV'
数据清洗
主要利用pandas库的函数进行数据的导入、清洗、转换,下一篇博客将尝试使用MySQL处理数据。
filepath="lagouzhaoping.csv"df_DM=pd.read_csv(filepath, index_col=None) df_DM.info()
首先读取csv文件,查看DataFrame的基本信息,结果如下: 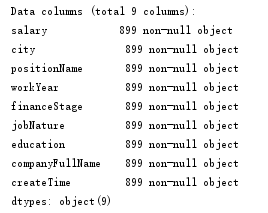
education=df_DM['education']
education=pd.DataFrame(education.unique())# 不限 大专 本科 硕士 博士df_DM['education'] = df_DM['education'].replace('不限','unlimited')
df_DM['education'] = df_DM['education'].replace('大专','junior')
df_DM['education'] = df_DM['education'].replace('本科','regular')
df_DM['education'] = df_DM['education'].replace('硕士','master')
df_DM['education'] = df_DM['education'].replace('博士','doctor')由于表格中工作城市、学历要求、经验要求等数据均为中文,后续用seaborn库绘制的时候会发生错误,只能先将中文数据替换成英文,显然过于繁琐,希望可以找到更合适的解决方法。
df_DM['minSalary'] = df_DM['salary'].str.replace('(.{1,})k-(.{1,})k','\\1')
df_DM['maxSalary'] = df_DM['salary'].str.replace('(.{1,})k-(.{1,})k','\\2')
df_DM['minSalary']= df_DM['minSalary'].str.replace('(.{1,})k以上','\\1')
df_DM['maxSalary']= df_DM['maxSalary'].str.replace('(.{1,})k以上','\\1')
df_DM['minSalary']= df_DM['minSalary'].astype(int)
df_DM['maxSalary']= df_DM['maxSalary'].astype(int)
df_DM.drop(['salary'], axis=1,inplace=True)计算平均薪酬
职位信息的可视化分析
这里使用的是强大的seaborn库,用简单的函数就可以绘制出炫酷的图片,关于seaborn库的更多使用信息可以参考:Seaborn: statistical data visualization
学历 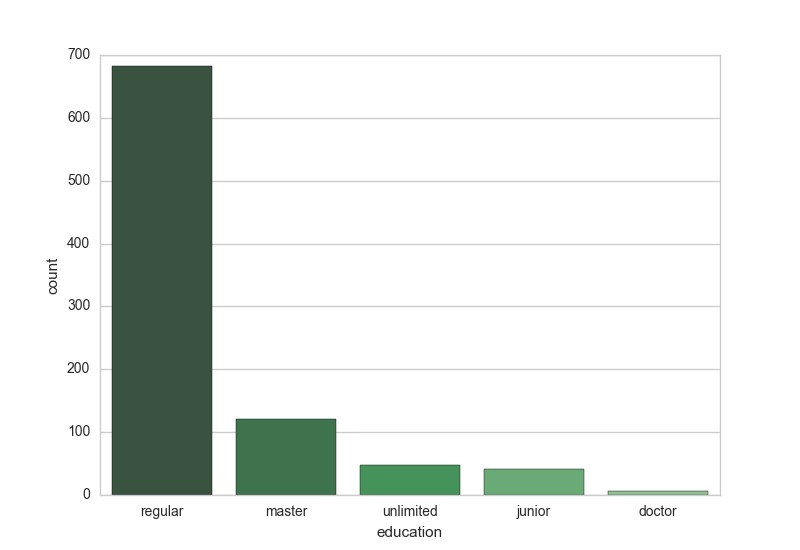
import seaborn as snssns.set_style('whitegrid')sns.countplot(x="education", data=df_DM,palette="Greens_d")工作经验 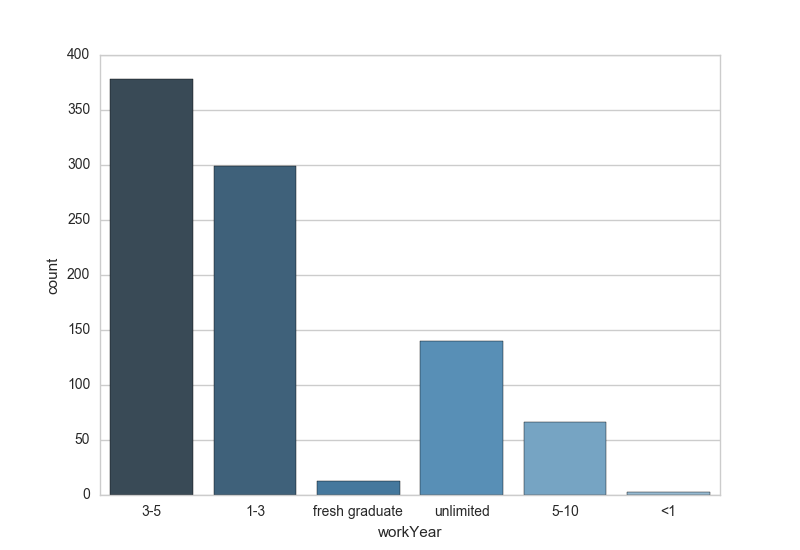
sns.countplot(x="workYear", data=df_DM,palette="Blues_d")
数据类工作的学历门槛并不高,多数岗位只要求本科以上的学历,但工作经验就非常重要了,社招岗位对应届毕业生非常不友好,要求3-5年或1-3年工作经验的岗位居多。
工作城市 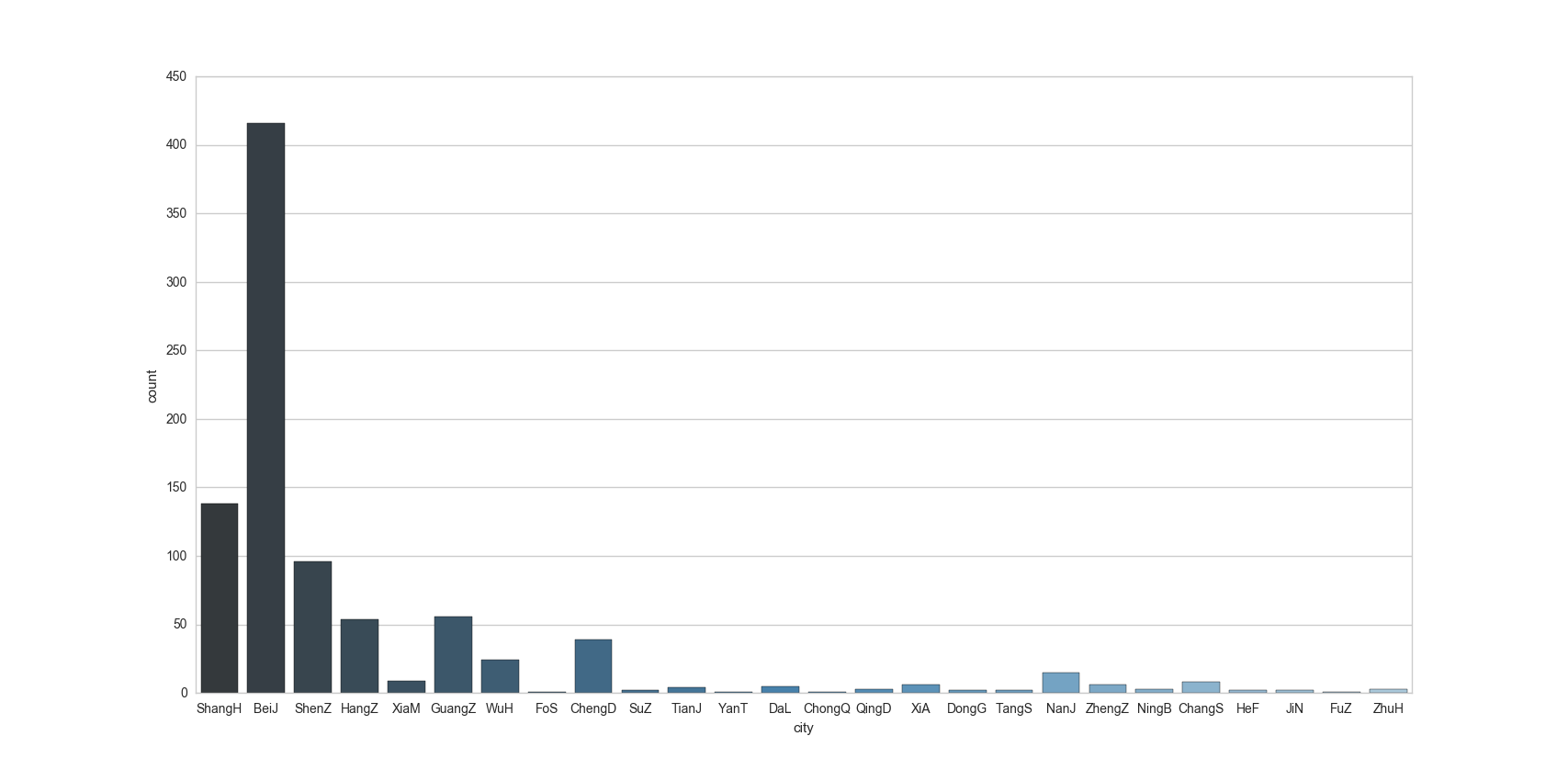
代码为
sns.countplot(x="city", data=df_DM,palette="Blues_d")
比较不同城市的薪酬待遇 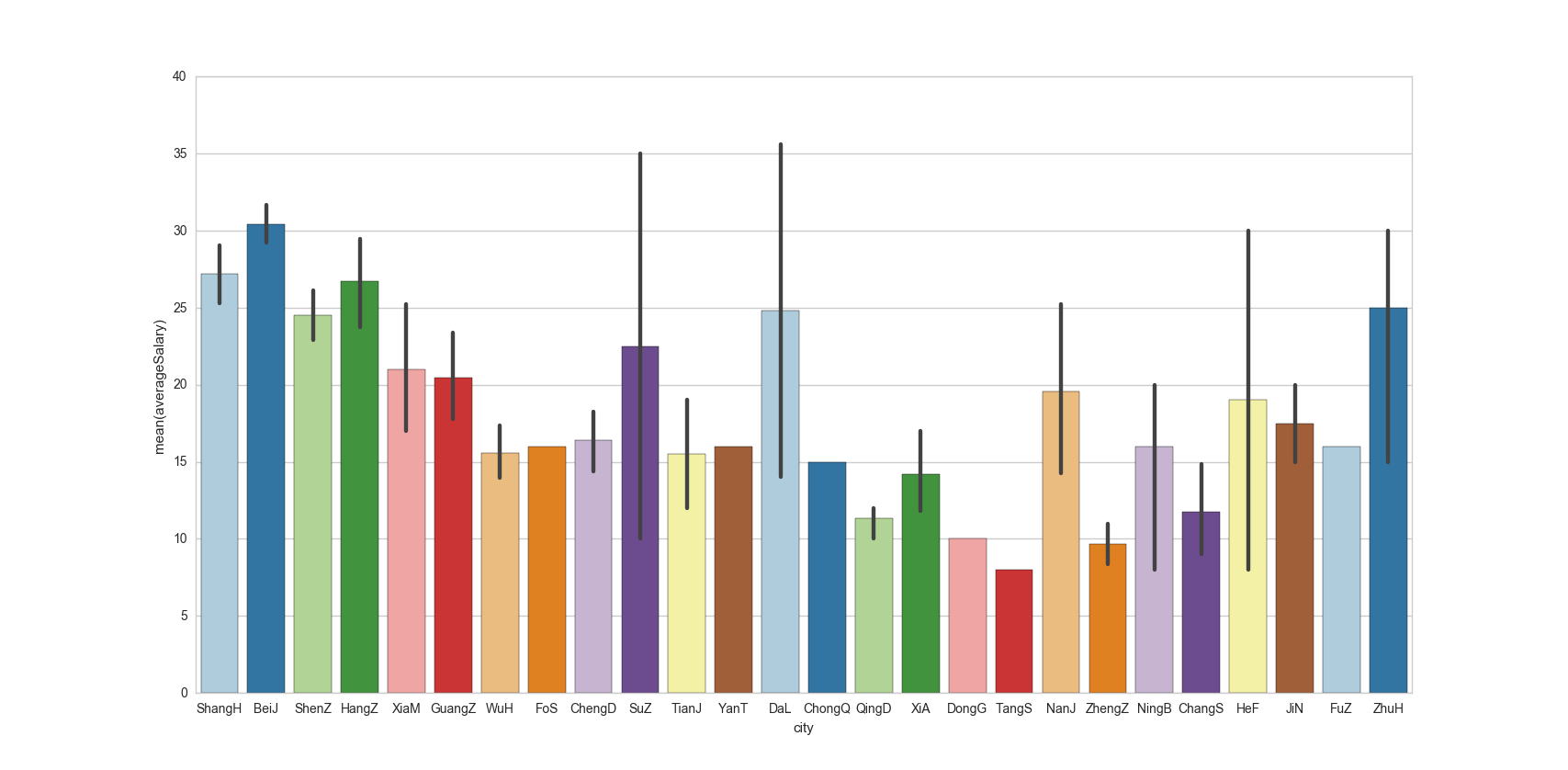
代码为
sns.barplot(x="city",y="averageSalary",data=df_DM,palette="Paired")
观察图片发现,在岗位需求量上北京遥遥领先,比上海、杭州、深圳加起来还要多。薪资待遇方面北上深杭当仁不让,这里有一个小问题,由于珠海、福州等城市岗位需求数实际上很小,其薪资不具有代表性,在统计分析时应当指定一个阈值,将岗位数小于该阈值的城市划分为一类。
总结
通过这次简单的分析,不仅练习了爬虫与数据处理的基本功能,同时得出的结论对我这样的小白应届生也是一个很好的参考,了解了岗位需求,才能够更有方向地提升自己。希望在写下一篇博客时,能够完善这次代码中一些不合理的地方。
转自:https://blog.csdn.net/cherrie3/article/details/52644256





