打算从底层原理好好认识Web结合Java认识网页,于是我买了本《深入分析 Java Web 技术内幕》许令波 著,看到别人推荐这本书,上面还印有阿里巴巴集团,感觉应该物有所值。最近除了自己买的书之外,获奖得了两本,书都摞成一摞了,要开始啃书。除此之外,我还买了5个网课……完全是开启了“买买买”的模式。得抓紧学了,不然又懒了。
1、Web请求过程
如果我照着书上的码出来,肯定毫无意义,我先说说我的总结:
(1)简单的访问模式,一台具备公网IP的服务器,运行Tomcat(其他的当然也可以),然后在浏览器里输入公网IP即可。
(2)复杂一点的访问模式,根据请求的IP地址,通过负载均衡判断访问多台服务器中的一台
以上两个有什么区别?
前者通常是我们自己开发或者学习时用的环境,逻辑一点都不复杂,访问地址,加载文件,显示到Browser即可。后者则是为了解决大型网络遇到的各种问题,当全国人民都想用你的网站,只有一台主机肯定不够用,于是从物理上就要增多,同时大部分静态资源很可能长时间不会发生变化,于是又有了CDN,通过负载均衡到了服务端,为了加快响应速度,减少访问数据库的次数,于是有了缓存等等。
2、不知道有没有人想过这两个问题,浏览器是什么?我们如何访问一个网站?
浏览器就是检索并展示万维网的应用程序。
我们访问一个网站其实就是访问一个地址,而且通常是80端口,其本质和Socket连接区别不大,Socket这里不做解释。就是访问一个地址后,需要二进制字节数据格式符合HTTP协议。
Hypertext Transfer Protocol
超文本传输协议
HTTP是一种通用的无状态协议,可以用于其他目的,也可以使用其请求方法,错误代码和标头的扩展。基本上,HTTP是基于TCP / IP的通信协议,用于在万维网上传递数据(HTML文件,图像文件,查询结果等)。
这个协议谁制定的?
HTTP的標準制定由万维网协会(World Wide Web Consortium,W3C)和互联网工程任务组(Internet Engineering Task Force,IETF)
想查看协议的具体内容和发展历史,可以访问www.ietf.org
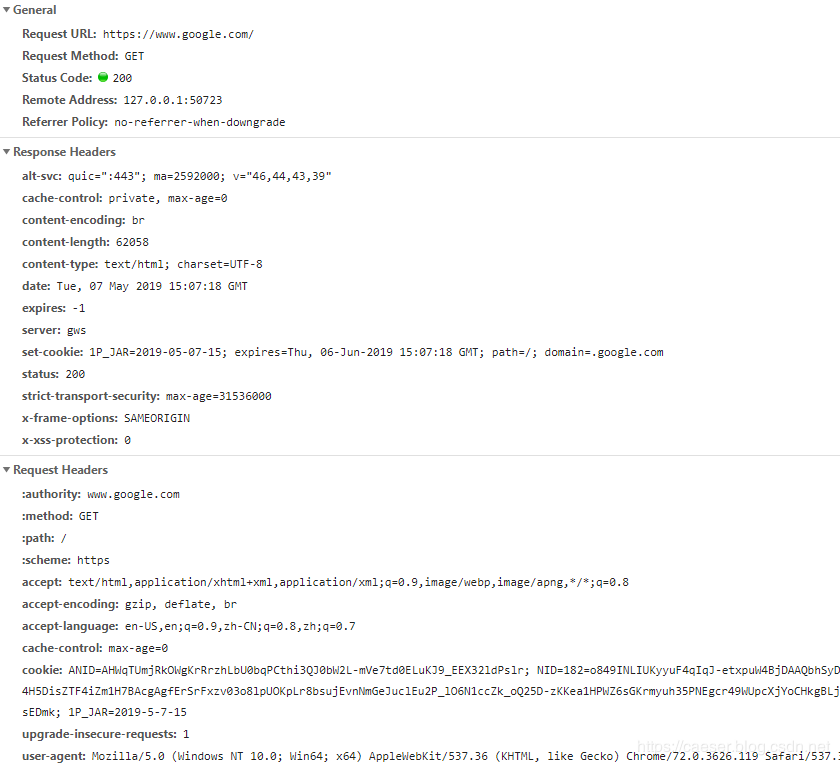
要理解HTTP,最重要的是熟悉HTTP中的HTTP Header,常见的请求头和响应头以及状态码如下:
| 请求头 | 说明 |
|---|---|
| Accept-Charset | 用于指定客户端接受的字符集 |
| Accept-Encoding | 用于指定可接受的内容编码,如Accept-Encoding:gzip,deflate |
| Accept-Language | 用于指定一种自然语言,如Accept-Language:zh-cn |
| Host | 用于指定被请求资源的Internet主机和端口号,如 Host:www.caeser.cn |
| User-Agent | 客户端将它的操作系统、浏览器和其他属性告诉服务器 |
| Connection | 当前连接是否保持,如Connection:Keep-Alive |
| 响应头 | 说明 |
|---|---|
| Server | 使用的服务器名称,如Server:Apache/1.3.6(Unix) |
| Content-Type | 用来指明发送给接收者的实体正文的媒体类型,如Content-Type:text/html;charset=GBK |
| Content-Encoding | 与请求报头Accept-Encoding对应,告诉浏览器服务端采用的是什么压缩编码 |
| Content-Language | 描述了资源所用的自然语言,与Accept-Language对应 |
| Content-Length | 指明实体正文的长度,用以字节方式存储的十进制数字来表示 |
| Keep-Alive | 保持连接的时间,如Keep-Alive: timeout=5,max=120 |
| 状态码 | 说明 |
|---|---|
| 200 | 客户端请求成功 |
| 302 | 临时跳转,跳转的地址通过Location指定 |
| 400 | 客户端请求有语法错误,不能被服务器识别 |
| 403 | 服务器收到请求,但是拒绝提供服务 |
| 404 | 请求的资源不存在 |
| 500 | 服务器发送不可预期的错误 |
上面介绍的这些东西用在了哪里呢?
Chrome浏览器访问网址之后,进入调试模式,例如我输入www.google.com