
小姐姐味道【ID:xjjdog】
作者:十年架构,日百亿流量经验,与你分享。

我们在《360度测试:KAFKA会丢数据么?其高可用是否满足需求?》这篇文章中,详细说明了KAFKA是否适合用在业务系统中。但有些朋友,还不知道KAFKA为何物,以及它为何存在。这在工作和面试中是比较吃亏的,因为不知道什么时候起,KAFKA似乎成了一种工程师的必备技能。
一些观念的修正
从 0.9 版本开始,Kafka 的标语已经从“一个高吞吐量,分布式的消息系统”改为”一个分布式流平台“。
Kafka不仅仅是一个队列,而且是一个存储,有超强的堆积能力。
Kafka不仅用在吞吐量高的大数据场景,也可以用在有事务要求的业务系统上,但性能较低。
Kafka不是Topic越多越好,由于其设计原理,在数量达到阈值后,其性能和Topic数量成反比。
引入了消息队列,就等于引入了异步,不管你是出于什么目的。这通常意味着业务流程的改变,甚至产品体验的变更。
消息系统是什么
典型场景
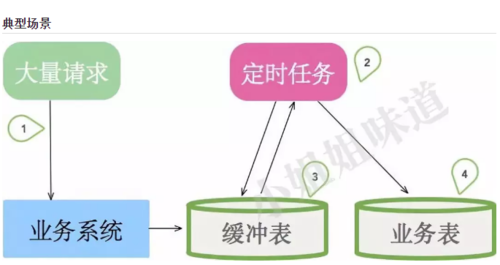
上图是一些小系统的典型架构。考虑订单的业务场景,有大量的请求指向我们的业务系统,如果直接经过复杂的业务逻辑进入业务表,将会有大量请求超时失败。所以我们加入了一张中间缓冲表(或者Redis),用来承接用户的请求。然后,有一个定时任务,不断的从缓冲表中获取数据,进行真正的业务逻辑处理。
这种设计有以下几个问题:
定时任务的轮询间隔不好控制。业务处理容易延迟。
无法横向扩容处理能力,且会引入分布式锁、顺序性保证等问题。
当其他业务也需要这些订单数据的时候,业务逻辑就必须要加入到定时任务里。
当访问量增加、业务逻辑复杂化的时候,消息队列就呼之欲出了。
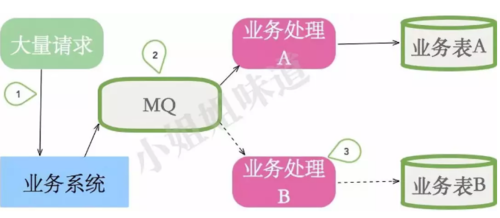
请求会暂存在消息队列,然后实时通过推(或者拉)的方式进行处理。
在此场景下,消息队列充当了削峰和冗余的组件。
消息系统的作用
削峰 用于承接超出业务系统处理能力的请求,使业务平稳运行。这能够大量节约成本,比如某些秒杀活动,并不是针对峰值设计容量。
缓冲 在服务层和缓慢的落地层作为缓冲层存在,作用与削峰类似,但主要用于服务内数据流转。比如批量短信发送。
解耦 项目尹始,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
冗余 消息数据能够采用一对多的方式,供多个毫无关联的业务使用。
健壮性 消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行。
消息系统要求
消息系统即然这么重要,那么除了能够保证高可用,对它本身的特性也有较高需求。大体有下面几点:
性能要高 包含消息投递和消息消费,都要快。一般通过增加分片数获取并行处理能力。
消息要可靠 在某些场景,不能丢消息。生产、消费、MQ端都不能丢消息。一般通过增加副本,强制刷盘来解决。
扩展性要好 能够陪你把项目做大,陪你到天荒地老。增加节点集群增大后,不能降低性能。
生态成熟 监控、运维、多语言支持、社区的活跃。
KAFKA名词解释
基本功能
Kafka是一个分布式消息(存储)系统。分布式系统通过分片增加并行度;通过副本增加可靠性,kafka也不例外。我们来看一下它的结构,顺便解释一下其中的术语。
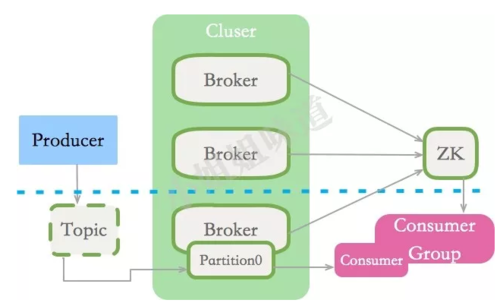
你在一台机器上安装了Kafka,那么这台机器就叫Broker,KAFKA集群包含了一个或者多个这样的实例。
负责往KAFKA写入数据的组件就叫做Producer,消息的生产者一般写在业务系统里。
发送到KAFKA的消息可能有多种,如何区别其分类?就是Topic的概念。一个主题分布式化后,可能会存在多个Broker上。
将Topic拆成多个段,增加并行度后,拆成的每个部分叫做Partition,分区一般平均分布在所有机器上。
那些消费Kafka中数据的应用程序,就叫做Consumer,我们给某个主题的某个消费业务起一个名字,这么名字就叫做Consumer Group
扩展功能
Connector 连接器Task,包含Source和Sink两种接口,给用户提供了自定义数据流转的可能。比如从JDBC导入到Kafka,或者将Kafka数据直接落地到DB。
Stream 类似于Spark Stream,能够进行流数据处理。但它本身没有集群,只是在KAFKA集群上的抽象。如果你想要实时的流处理,且不需要Hadoop生态的某些东西,那么这个比较适合你。
Topic
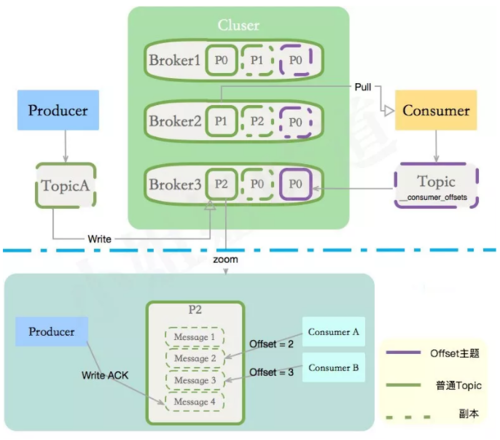
我们的消息就是写在主题里。有了多个Topic,就可以对消息进行归类与隔离。比如登录信息写在user_activity_topic,日志消息写在log_topic中。
每一个topic都可以调整其分区数量。假设我们的集群有三个Broker,那么当分区数量为1的时候,消息就仅写在其中一个节点上;当我们的分区为3,消息会根据hash写到三个节点上;当我们的分区为6,那每个节点将会有2个分区信息。增加分区可以增加并行度,但不是越多越好。一般,6-12最佳,最好能够被节点数整除,避免数据倾斜。
每个分区都由一系列有序的、不可变的消息组成,这些消息被顺序的追加。分区中的每个消息都有一个连续的序列号叫做offset。Kafka将保留配置时间内的所有消息,所以它也是一个临时存储。在这段时间内,所有的消息都可被消费,并且可以通过改变offset的值进行重复、多次消费。
Offset一般由消费者管理,当然也可以通过程序按需要设置。Offset只有commit以后,才会改变,否则,你将一直获取重复的数据。新的kafka已经将这些Offset的放到了一个专有的主题:__consumer_offsets,就是上图的紫色区域。
值得一提的是,消费者的个数,不要超过分区的个数。否则,多出来的消费者,将接收不到任何数据。
ISR
分布式系统保证数据可靠性的一个常用手段就是增加副本个数,ISR就是建立在这个手段上。
ISR全称”In-Sync Replicas”,是保证HA和一致性的重要机制。副本数对Kafka的吞吐率是有一定的影响,但极大的增强了可用性。一般2-3个为宜。
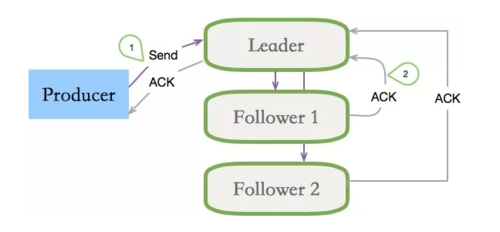
副本有两个要素,一个是数量要够多,一个是不要落在同一个实例上。ISR是针对与Partition的,每个分区都有一个同步列表。N个replicas中,其中一个replica为leader,其他都为follower, leader处理partition的所有读写请求,其他的都是备份。与此同时,follower会被动定期地去复制leader上的数据。
如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除。
当ISR中所有Replica都向Leader发送ACK时,leader才commit。
Kafka的ISR的管理最终都会反馈到Zookeeper节点上。具体位置为:/brokers/topics/[topic]/partitions/[partition]/state。当Leader节点失效,也会依赖Zk进行新的Leader选举。Offset转移到Kafka内部的Topic以后,KAFKA对ZK的依赖就越来越小了。
可靠性
消息投递语义
At least once
可能会丢消息,但不不会重复
At most once
不不丢消息,但可能重复,所以消费端要做幂等
Exactly once
消息不不会丢,且保证只投递⼀一次
整体的消息投递语义需要Producer端和Consumer端两者来保证。KAFKA默认是At most once,也可以通过配置事务达到Exactly once,但效率很低,不推荐。
ACK
当生产者向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别:
1(默认) 数据发送到Kafka后,经过leader成功接收消息的的确认,就算是发送成功了。在这种情况下,如果leader宕机了,则会丢失数据。
0 生产者将数据发送出去就不管了,不去等待任何返回。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
-1 producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。
KAFKA为什么快
Cache Filesystem Cache PageCache缓存
顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
Zero-copy 零拷⻉,少了一次内存交换。
Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。
Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符。
使用场景
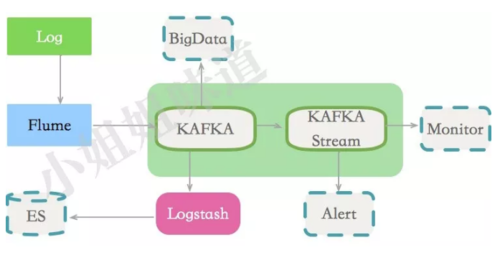
传递业务消息
用户活动日志 • 监控项等
日志
流处理,比如某些聚合
Commit Log,作为某些重要业务的冗余
下面是一个日志方面的典型使用场景。
压测
KAFKA自带压测工具,如下。
./kafka-producer-perf-test.sh --topic test001 --num- records 1000000 --record-size 1024 --throughput -1 --producer.config ../config/producer.properties
配置管理
关注点
应⽤用场景 不同的应用场景有不一样的配置策略和不一样的SLA服务水准。需要搞清楚自己的消息是否允许丢失或者重复,然后设定相应的副本数量和ACK模式。
Lag 要时刻注意消息的积压。Lag太高意味着处理能力有问题。如果在低峰时候你的消息有积压,那么当大流量到来,必然会出问题。
扩容 扩容后会涉及到partition的重新分布,你的网络带宽可能会是瓶颈。
磁盘满了 建议设置过期天数,或者设置磁盘最大使用量。
log.retention.bytes
过期删除 磁盘空间是有限的,建议保留最近的记录,其余自动删除。
log.retention.hours log.retention.minutes log.retention.ms
监控管理工具
KafkaManager 雅虎出品,可管理多个Kafka集群,是目前功能最全的管理工具。但是注意,当你的Topic太多,监控数据会占用你大量的带宽,造成你的机器负载增高。其监控功能偏弱,不满足需求。
KafkaOffsetMonitor 程序一个jar包的形式运行,部署较为方便。只有监控功能,使用起来也较为安全。
Kafka Web Console 监控功能较为全面,可以预览消息,监控Offset、Lag等信息,不建议在生产环境中使用。
Burrow 是LinkedIn开源的一款专门监控consumer lag的框架。支持报警,只提供HTTP接口,没有webui。
Availability Monitor for Kafka 微软开源的Kafka可用性、延迟性的监控框架,提供JMX接口,用的很少。
Rebalance
消费端Rebalance
消费端的上线下线会造成分区与消费者的关系重新分配,造成Rebalance。业务会发生超时、抖动等。
服务端reassign
服务器扩容、缩容,节点启动、关闭,会造成数据的倾斜,需要对partition进行reassign。在kafka manager后台可以手动触发这个过程,使得分区的分布更加平均。
这个过程会造成集群间大量的数据拷贝,当你的集群数据量大,这个过程会持续数个小时或者几天,谨慎操作。
linkedin开源了其自动化管理工具cruise-control,有自动化运维需求的不妨一看。
结尾
本文是KAFKA相关的最基础的知识,基本涵盖了大部分简单的面试题。
为了达到Exactly once这个语义,KAFKA做了很多努力,努力的结果就是几乎不可用,吞吐量实在是太低了。如果你真要将“高可靠”挂在嘴上,不如做好“补偿策略”。性能不成,最终的结果可能是整体不可用;而数据丢失,仅是极端情况下的一部分小数据而已。你会如何权衡呢?
大流量下的KAFKA是非常吓人的,数据经常将网卡打满。而一旦Broker当机,如果单节点有上T的数据,光启动就需要半个小时,它还要作为Follower去追赶其他Master分区的数据。所以,不要让你的KAFKA集群太大,故障恢复会是一场灾难。启动以后,如果执行reassign,又会是另一番折腾了。






