
前段时间为“周杰伦打榜”话题迅速登上微博热搜榜
因为cxk的粉丝们质疑周杰伦微博没有数据
(周杰伦没有开通微博)
于是,无数隐匿江湖多年
看不下去的周杰伦老年粉开始被迫营业
于是一场周杰伦中老年粉VS蔡徐坤铁军
微博打榜大战拉响
为听了那么多年的周杰伦
粉丝们纷纷拉下老脸
和00后的微博饭圈小年轻们
从零学习如何做数据

一、需求背景
 今天我们就用他们说的数据,来实力打脸,让iKun们看看周杰伦的粉丝们到底是不是中老年粉!
今天我们就用他们说的数据,来实力打脸,让iKun们看看周杰伦的粉丝们到底是不是中老年粉!二、功能描述
#周杰伦超话#下的微博,然后再爬取他们的个人主页信息,获取年龄、地区、性别等信息,然后用数据分析,再可视化呈现!注意:文中说的微博个人主页信息均为微博公开信息,不包含任何隐私信息,同时全文中将不会出现任何人的个人信息,信息仅用于学习分析,任何人不得使用此教程用作商用,违者后果自负!
三、技术方案
- 爬取
#周杰伦超话#下的微博 - 根据每条微博爬取该用户基本信息
- 将信息保存到csv文件
- 使用数据分析用户年龄、性别分布
- 分析粉丝团的地区分布
- 使用词云分析打榜微博内容
requests库,保存csv文件我们可以使用内置库csv,而可视化数据分析这次给大家介绍一个超级好用的库pyecharts,技术选型好了之后我们就可以开始技术实现了!四、爬取超话微博
1.找到超话加载数据URL
#周杰伦超话#页面,然后调出调试窗口,改为手机模式,然后过滤请求,只查看异步请求,查看返回数据格式,找到微博内容所在!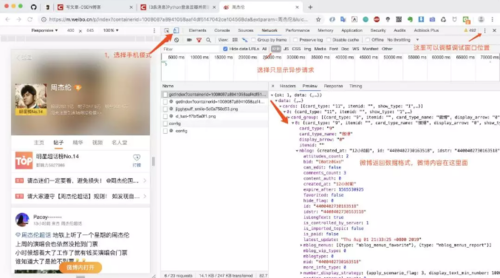 微博请求链接:https://m.weibo.cn/api/container/getIndex?jumpfrom=weibocom&containerid=1008087a8941058aaf4df5147042ce104568da_-_feed
微博请求链接:https://m.weibo.cn/api/container/getIndex?jumpfrom=weibocom&containerid=1008087a8941058aaf4df5147042ce104568da_-_feed2.代码模拟请求数据
requests库。简单几句便可以获取微博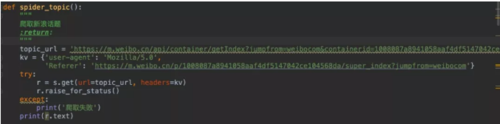
3.提取微博内容
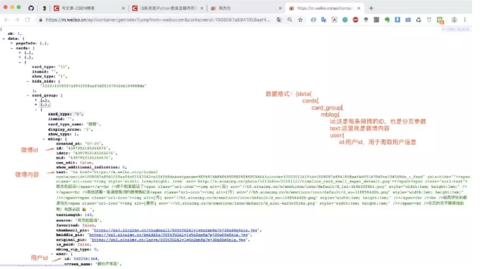 了解微博返回的数据结构之后我们就可以将微博内容和id提取出来啦
了解微博返回的数据结构之后我们就可以将微博内容和id提取出来啦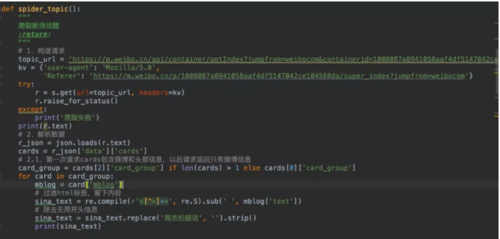
4.批量爬取微博
查找分页参数技巧:比较第一次和第二次请求url,看看有何不同,找出不同的参数!给大家推荐一款文本比较工具:Beyond Compare
since_id参数,而这个since_id参数就是每条微博的id!微博分页机制:根据时间分页,每一条微博都有一个since_id,时间越大的since_id越大所以在请求时将since_id传入,则会加载对应话题下比此since_id小的微博,然后又重新获取最小since_id将最小since_id传入,依次请求,这样便实现分页
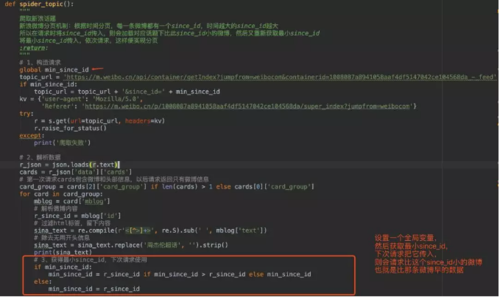 然后写一个for循环调用上面那个方法就可以啦
然后写一个for循环调用上面那个方法就可以啦# 批量爬取
for i in range(1000):
print('第%d页' % (i + 1))
spider_topic()
四、爬取用户信息
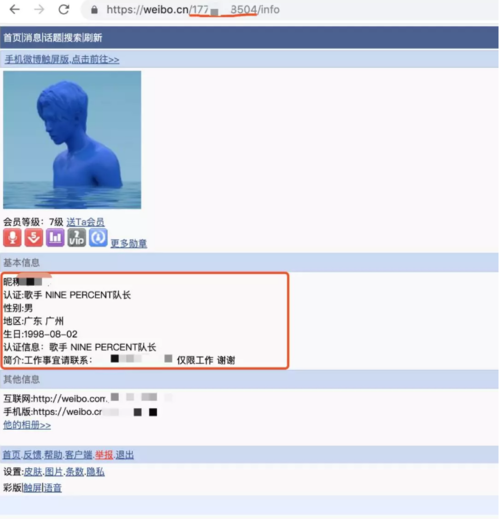 所以我们只要获取到用户的id就可以拿到他的公开基本信息!
所以我们只要获取到用户的id就可以拿到他的公开基本信息!1.获取用户id
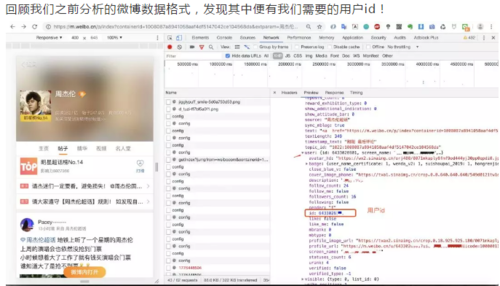 所以我们在提取微博内容的时候可以顺便将用户id提取出来!
所以我们在提取微博内容的时候可以顺便将用户id提取出来!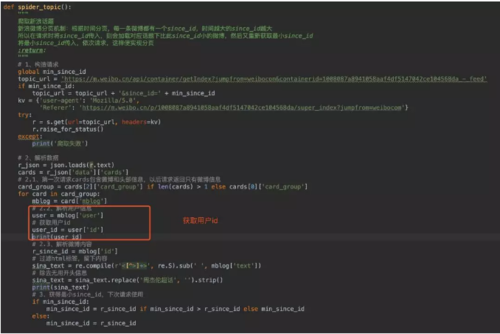
2.模拟登录
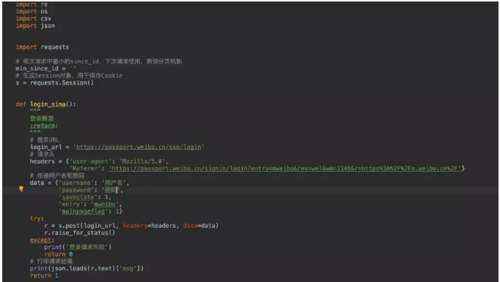 登录我们使用的是requests.Session()对象,这个对象会自动保存cookies,下次请求自动带上cookies!
登录我们使用的是requests.Session()对象,这个对象会自动保存cookies,下次请求自动带上cookies!3.爬取用户公开信息
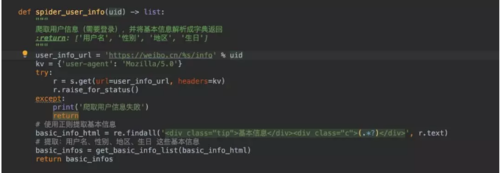 这里公开信息我们只要:用户名、性别、地区、生日这些数据!所以我们需要将这几个数据提取出来!
这里公开信息我们只要:用户名、性别、地区、生日这些数据!所以我们需要将这几个数据提取出来!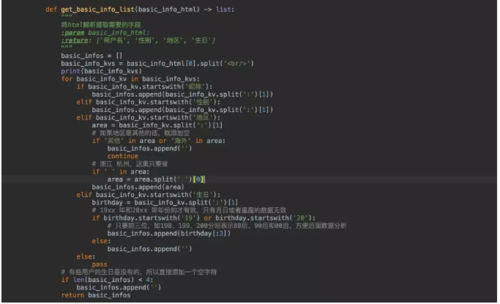 爬取用户信息不能过于频繁,否则会出现请求失败(响应状态码=418),但是不会封你的ip,其实很多大厂 不太会轻易的封ip,太容易误伤了,也许一封就是一个小区甚至更大!
爬取用户信息不能过于频繁,否则会出现请求失败(响应状态码=418),但是不会封你的ip,其实很多大厂 不太会轻易的封ip,太容易误伤了,也许一封就是一个小区甚至更大!五、保存csv文件
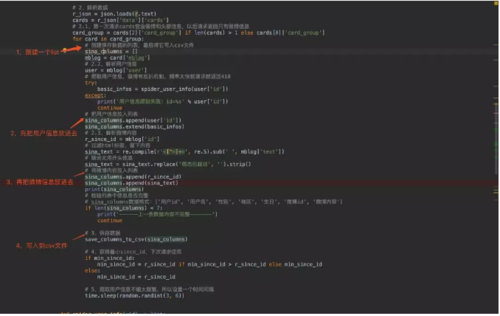 我们生成一个列表,然后将数据按顺序放入,再写入csv文件!
我们生成一个列表,然后将数据按顺序放入,再写入csv文件!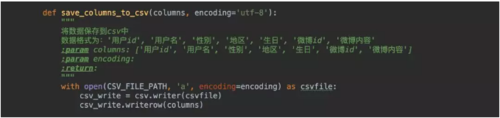 看看生成的csv文件,注意csv如果用wps或excel打开可能会乱码,因为我们写入文件用utf-8编码,而wps或excel只能打开gbk编码的文件,你可以用一般的文本编辑器即可,pycharm也可以!
看看生成的csv文件,注意csv如果用wps或excel打开可能会乱码,因为我们写入文件用utf-8编码,而wps或excel只能打开gbk编码的文件,你可以用一般的文本编辑器即可,pycharm也可以!
六、数据分析
- 我们可以将性别数据做生成饼图,简单直观
- 将年龄数据作出柱状图,方便对比,看看到底是不是夕阳红老年团
- 将地区做成中国热力图,看看哪个地区粉丝最活跃
- 最后将微博内容做成词云图,直观了解大家在说啥
1.读取csv文件列
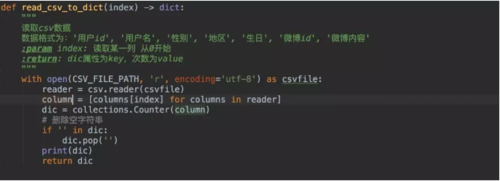 这里猪哥还使用了
这里猪哥还使用了Counter类来统计词频,方便后面数据分析,他返回的格式为:{‘女’: 1062, ‘男’: 637}。2.可视化库pyecharts
matplotlib库做词云,matplotlib做一些简单的绘图非常方便。但是今天我们需要做一个全国分布图,所以经过猪哥对比筛选,选择了国人开发的pyecharts库。选择这个库的理由是:开源免费、文档详细、图形丰富、代码简介,用着就是一个字:爽!官网:https://pyecharts.org/#/
源码:https://github.com/pyecharts/pyecharts
安装:pip install pyecharts
po一张他们的官方文档图片
 这里有非常详细的例子,直接复制过来就可以运行得到图片!
这里有非常详细的例子,直接复制过来就可以运行得到图片!
3.分析性别
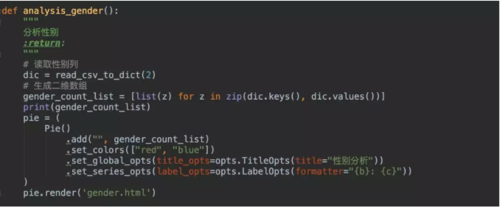 这里说下为什么生成的是html?因为这是动态图,就是可以点击选择显示的,非常人性化!执行之后会生成一个gender.html文件,在浏览器打开就可以!
这里说下为什么生成的是html?因为这是动态图,就是可以点击选择显示的,非常人性化!执行之后会生成一个gender.html文件,在浏览器打开就可以!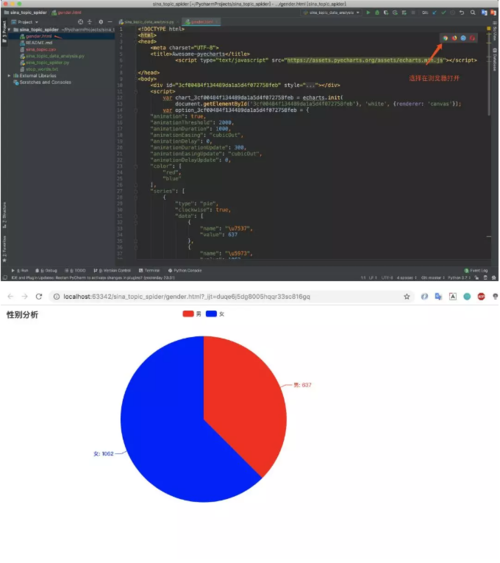 效果图中可以看到,在打榜的粉丝中女性多于男性,女性占比大概为62%!
效果图中可以看到,在打榜的粉丝中女性多于男性,女性占比大概为62%!4.分析年龄
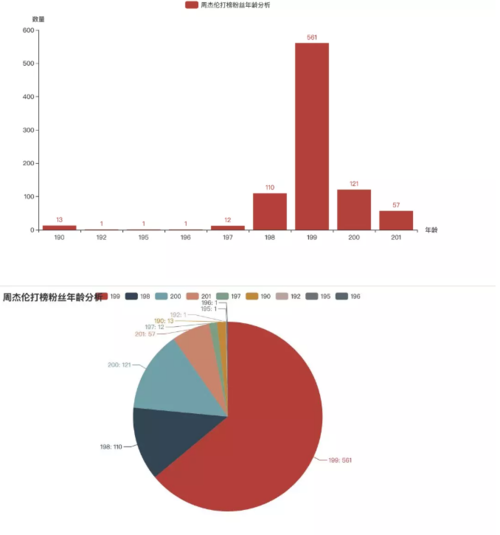 上图中我们发现为周杰伦打榜的主力军为:90后!
上图中我们发现为周杰伦打榜的主力军为:90后!5.地区分析
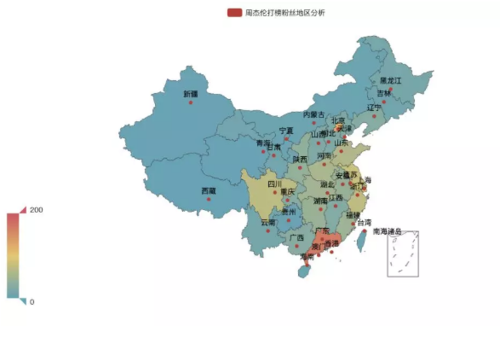 上图中我们可以看到打榜最多的三个省(直辖市)依次为:广州、北京、上海!
上图中我们可以看到打榜最多的三个省(直辖市)依次为:广州、北京、上海!6.打榜内容分析
 上图分析出现一些有趣的词:营业、老年人、奶茶!看来打榜粉丝们都自认为自己是老年人,哈哈哈!
上图分析出现一些有趣的词:营业、老年人、奶茶!看来打榜粉丝们都自认为自己是老年人,哈哈哈!
七、总结
【完】
裸睡的猪(ID:IT--Pig)
作者:猪哥-Pythoner,禁止未授权转载,授权请私聊






