
关于聚簇索引和非聚簇索引的概念很多同学找了很多教程但是仍然很迷糊。
这里给出一篇翻译,并给出我的配图,希望对大家理解有帮助。
英文原文:http://www.mysqltutorial.org/mysql-index/mysql-clustered-index/
一、聚簇索引的概念
一般来说索引就是如B-树这类可以来存储键值方便快速查找的数据结构。
聚簇索引是物理索引,数据表就是按顺序存储的,物理上是连续的。
一旦创建了聚簇索引,表中的所有列都根据聚簇索引的key来存储。
因为聚簇索引是按该列的排序存储的,因此一个表只能有一个聚簇索引。
二、MySQL中InnoDB表的聚簇索引
每个InnoDB表都需要一个聚簇索引。该聚簇索引可以帮助表优化增删改查操作。
如果你为表定义了一个主键,MySQL将使用主键作为聚簇索引。
如果你不为表指定一个主键,MySQL讲索第一个组成列都not null的唯一索引作为聚簇索引。
如果InnoBD表没有主键且没有适合的唯一索引(没有构成该唯一索引的所有列都NOT NULL),MySQL将自动创建一个隐藏的名字为“GEN_CLUST_INDEX ”的聚簇索引。
因此每个InnoDB表都有且仅有一个聚簇索引。
所有不是聚簇索引的索引都叫非聚簇索引或者辅助索引。
在InnDB存储引擎中,每个辅助索引的每条记录都包含主键,也包含非聚簇索引指定的列。
MySQL使用这个主键值来检索局促索引。
因此应该尽可能将主键缩短,否则辅助索引占用空间会更大。
一般来说用自增的整数型列作为主键列。
-----------------------华丽分隔符-------------------
简单解释
注意:这里的主键是非自增的。普通索引K表示普通的索引非唯一索引。
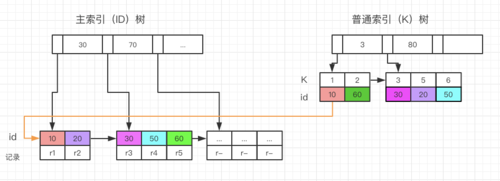
主键是采用B+Tree的数据结构(请看左图),根据上文可以知主键为聚簇索引,物理存储是根据ID的增加排序递增连续存储的。
普通索引K也是B+Tree的数据结构(请看右图),但是它不是聚簇索引,因此为非聚簇索引或者辅助索引(聚簇索引只可能是主键,或者所有组成唯一键的所有列都为NOT NULL的第一个唯一索引,或者隐式创建的聚簇索引这三种情况)。
他的叶子节点存储的是索引列的值,它的数据域是聚簇索引即ID。
假如普通索引k为非唯一索引,要查询k=3的数据。
需要在k索引查找k=3得到id=30。
然后在左侧的ID索引树查找ID=30对应的记录R3。
然后K索引树继续向右查找,发现下一个是k=5不满足(非唯一索引后面有可能有相等的值,因此向右查找到第一个不等于3的地方),停止。
整个过程从K索引树到主键索引树的过程叫做“回表”。
--------------------------------
想学习更多Java方面的技术,欢迎关注本人的慕课专栏:








