
Redis Cluster
呼唤集群
- redis最高可以达到10万/s,如果业务需要100万/s呢?
- 单机器内存太小,无法满足需求
数据分布


- 顺序分区的数据量不可确定性导致倾斜,不支持批量操作

哈希分布
节点取余分区 hash(key)%nodes
- 如果要增加分区,数据迁移量在80%左右
- 数据迁移第一次是无法从数据中取到的,数据库需要进行回写到新节点
- 客户端分片:哈希+取余
- 节点伸缩:数据节点关系变化,导致数据迁移
- 迁移数量和添加节点数量有关:建议翻倍扩容


一致性哈希分区
比较适合节点多的情况

- 客户端分片:哈希+顺时针(优化取余)
- 节点伸缩:只影响邻近节点,但是还是有数据迁移
- 翻倍伸缩:保证最小迁移数据和负载均衡
虚拟槽分区
共享消息模式
- 预设虚拟槽:每个槽映射一个数据子集,一般比节点数大
- 良好的哈希函数:例如CRC16
- 服务端管理节点、槽、数据:例如Redis Cluster

搭建集群
- 复制,高可用,切片
- 节点之间通过meet来相互通信
- 给节点指派槽,这样节点可以正常的读写
- 每个主节点有复制一个从节点



安装
- 原生命令安装
- 配置开启节点
- meet
- 指派槽
- 主从
- cluster replicate node-id
- 官方工具安装
port $(port}
daemonize yes
dir "/opt/redis/redis/data/"
dbfilename "dump-${port}.rdb"
logfile "$(port}.log"
cluster-enabled yes
cluster-config-file nodes-${port}.conf
redis-server redis-7000.conf
redis-server redis-7001.conf
redisaserver redis-7002.conf
redis-server redis-7003.conf
redis-server redis-7004.conf
redis-server redis-7005.conf
cluster meet ip port
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.17001
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7002
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.17003
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.17004
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.17005
cluster-enabled yes
cluster-node-timeout 15000 #故降转移,超时,ping不能容忍的一半时间
cluster-config-file "nodes.conf"
cluster-require-full-coverage yes 是否需要集群所有节点提供服务,一般配置No
cluster addslots slot [slot..…]
redis-cli -h 127.0.0.1 -p 7000 cluster addslots {0..5461}
redis-cli -h 127.0.0.1 -p 7001 cluster addslots {5462...10922}
redis-cli -h 127.0.0.1 -p 7002 cluster addslots {10923...16383}
redis-cli-h 127.0.0.1 -p 7003 cluster replicate $(node-id-7000}
redis-cli-h 127.0.0.1 -p 7004 cluster replicate $(node-id-7001}
redis-cli-h 127.0.0.1 -p 7005 cluster replicate $(node-id-7002}


Ruby环境
- 下载,编译,安装Ruby
- 安装rubygem redis
- 安装redis-trib.rb
wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz
tar-xvf ruby-2.3.1.tar.gz
./configure-prefix=/usr/local/ruby
make
make install
cd /usr/local/ruby
cp bin/ruby /usr/local/bin
安装rubygem redis
wget http://rubygems.org/downloads/redis-3.3.0.gem
gem install-I redis-3.3.0.gem
gem list--check redis gem
安装redis-trib.rb
cp ${REDIS_HOME}/src/redis-trib.rb/usr/local/bin
- 原生命令安装
- 理解Redis Cluster架构。
- 生产环境不使用。
- 官方工具安装
- 高效、准确。
- 生产环境可以使用。
- 其他
- 可视化部署
集群伸缩
伸缩原理

扩容集群
- 准备新节点
- 加入集群
- 作用
- 为其迁移槽和数据实现扩容
- 作为从节点负责故障转移
- 作用
- 迁移槽和数据

客户端实现




第二种方式
优点:会做一个孤立节点的检测


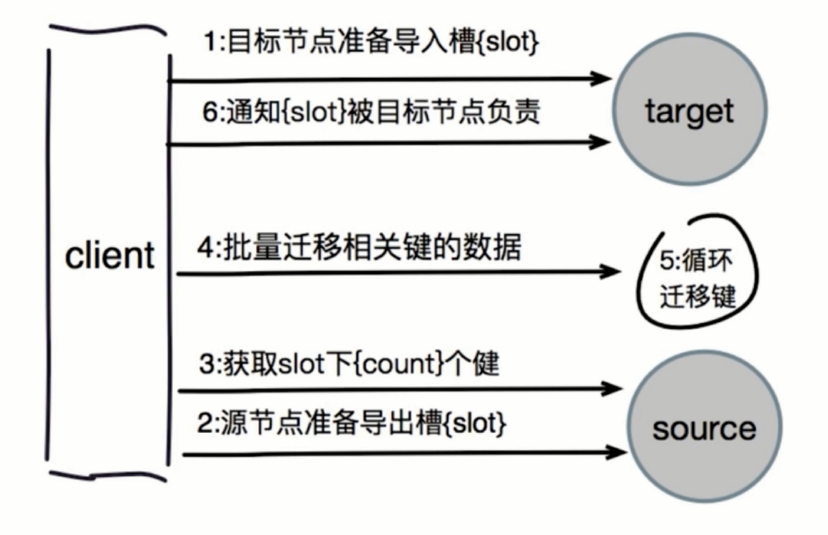
- 对目标节点发送:cluster setslot{slot)importing {sourceNodeld)命令,让目标节点准备导入槽的数据。
- 对源节点发送:cluster setslot {slot) migrating {targetNodeld)命令,让源节点准备迁出槽的数据。
- 源节点循环执行cluster getkeysinslot {slot) {count)命令,每次获取count个属于槽的健。
- 在源节点上执行migrate (targetlp} {targetPort} key 0 {timeout!命令把指定key迁移。
- 重复执行步骤3~4直到槽下所有的键数据迁移到目标节点。
- 向集群内所有主节点发送cluster setslot {slot)node {targetNodeld)命令,通知槽分配给目标节点。
集群扩容



pipeline

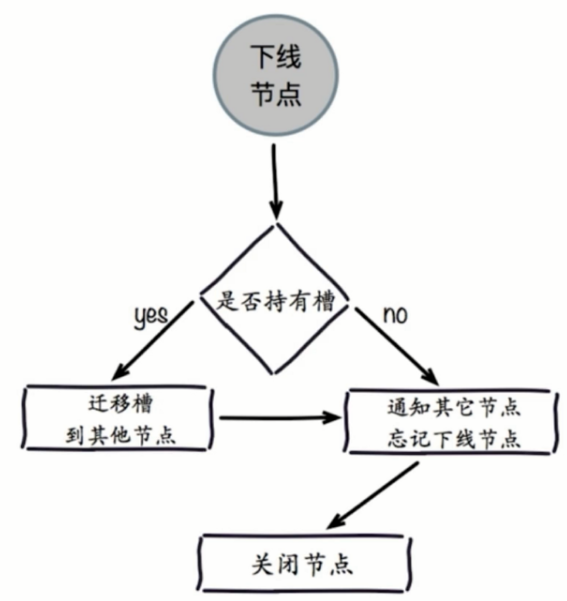
收缩集群
- 下线迁移槽
- 忘记节点
- 关闭节点



客户端路由

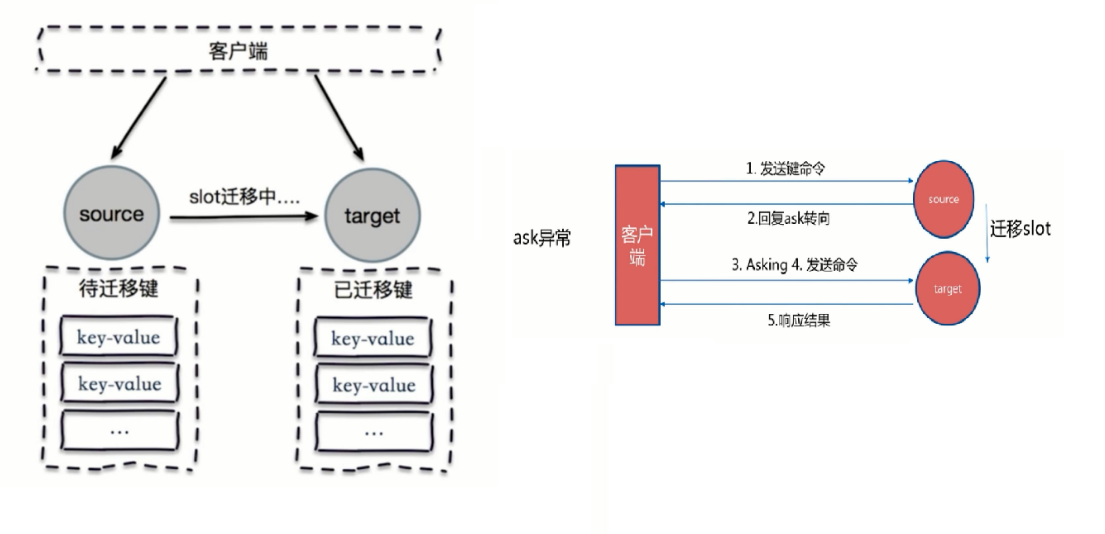
moved重定向


- 客户端不会自己找到异常节点,需要自己写逻辑

ask重定向
- moved和ask
- 两者都是客户单重定向
- moved:槽已经确定迁移
- ask:槽还在迁移中

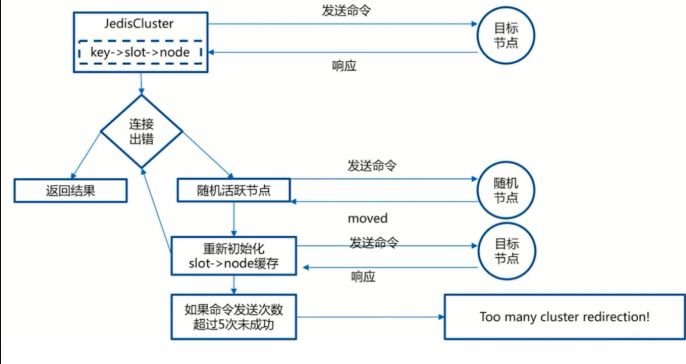
smart客户端工作原理
- 1.从集群中选一个可运行节点,使用cluster slots初始化槽和节点映射。
- 2.将cluster slots的结果映射到本地,为每个节点创建JedisPool。
- 3.准备执行命令。

JedisCluster基本使用

- 1.单例:内置了所有节点的连接池
- 2.无需手动借还连接池
- 3.合理设置commons-pool
整合spring

多节点命令实现

四种批量操作实现(mget,mset必须在一个槽)


故障转移
故障发现

故障恢复

常见问题
- Redis cluster数据分区规则采用虚拟槽方式(16384个槽),每个节点负责一部分槽和相关数据,实现数据和请求的负载均衡。
- 搭建集群划分四个步骤:准备节点、节点握手、分配槽、复制。
- redis-trib.rb工具用于快速搭建集群。
- 集群伸缩通过在节点之间移动槽和相关数据实现。
- 扩容时根据槽迁移计划把槽从源节点迁移到新节点。
- 收缩时如果下线的节点有负责的槽需要迁移到其它节点,再通过cluster forget命令让集群内所有节点忘记被下线节点。
- 使用smart客户端操作集群达到通信效率最大化,客户端内部负责计算维护键->槽->节点的映射,用于快速定位到目标节点。
- 集群自动故障转移过程分为故障发现和节点恢复。节点下线分为主观下线和客观下线,当超过半数主节点认为故障节点为主观下线时标记它为客观下线状态。从节点负责对客观下线的主节点触发故障恢复流程,保证集群的可用性。
- 开发运维常见问题包括:超大规模集群带宽消耗,pub/sub广播问题,集群倾斜问题,单机和集群对比等
集群完整性
- cluster-require-full-coverage默认为yes
- 集群中16384个槽全部可用:保证集群完整性
- 节点故障或者正在故障转移:
- (error)CLUSTERDOWN The cluster is down
- 大多数业务无法容忍,cluster-require-full-coverage建议设置为no
带宽消耗

- 优化
- 避免“大”集群:避免多业务使用一个集群,大业务可以多集群。
- cluster-node-timeout:带宽和故障转移速度的均衡。
- 尽量均匀分配到多机器上:保证高可用和带宽
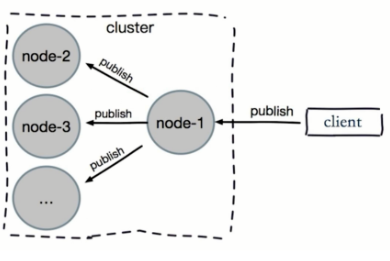
Pub/Sub广播(发布一条消息,每个节点都会接收到,加重带宽消耗)
- 问题:publish在集群每个节点广播:加重带宽
- 解决:单独“走”一套Redis Sentinel

数据倾斜
分两种,数据倾斜和请求倾斜

读写分离
- 只读连接:集群模式的从节点不接受任何读写请求。
- 重定向到负责槽的主节点
- readonly命令可以读:连接级别命令
- 读写分离:更加复杂
- 同样的问题:复制延迟、读取过期数据、从节点故障
- 修改客户端:cluster slaves {nodeld)
数据迁移
- 官方迁移工具:redis-trib.rb import
- 只能从单机迁移到集群
- 不支持在线迁移:source需要停写
- 不支持断点续传
- 单线程迁移:影响速度
- 在线迁移:
- 唯品会redis-migrate-tool
- 豌豆荚:redis-port
./redis-trib.rb import --from 127.0.0.1:6388 --copy 127.0.0.1:7000
集群VS单机
- key批量操作支持有限:例如mget、mset必须在一个slot
- Key事务和Lua支持有限:操作的key必须在一个节点
- key是数据分区的最小粒度:不支持bigkey分区
- 不支持多个数据库:集群模式下只有一个db0
- 复制只支持一层:不支持树形复制结构
- Redis Cluster:满足容量和性能的扩展性,很多业务”不需要”。
- 大多数时客户端性能会”降低”。
- 命令无法跨节点使用:mget、keys、scan、flush、sinter等。
- Lua和事务无法跨节点使用。
- 客户端维护更复杂:SDK和应用本身消耗(例如更多的连接池)。
缓存设计与优化(知识点)
- 缓存收益:加速读写、降低后端存储负载。
- 缓存成本:缓存和存储数据不一致性、代码维护成本、运维成本。
- 推荐结合剔除、超时、主动更新三种方案共同完成。
- 穿透问题:使用缓存空对象和布隆过滤器来解决,注意它们各自的使用场景和局限性。、
- 无底洞问题:分布式缓存中,有更多的机器不保证有更高的性能。有四种批量操作方式:串行命令、串行IO、并行IO、hash_tag。
- 雪崩问题:缓存层高可用、客户端降级、提前演练是解决雪崩问题的重要方法。
- 热点key问题:**互斥锁、“永远不过期”**能够在一定程度上解决热点key问题,开发人员在使用时要了解它们各自的使用成本。
缓存收益与成本
收益
- 1.加速读写
- 通过缓存加速读写速度:CPUL1/L2/L3 Cache、Linux page Cache加速硬盘读写、浏览器缓存、Ehcache缓存数据库结果。
- 2.降低后端负载
- 后端服务器通过前端缓存降低负载:业务端使用Redis降低后端MySQL负载等
成本
- 数据不一致:缓存层和数据层有时间窗口不一致,和更新策略有关。
- 代码维护成本:多了一层缓存逻辑。
- 运维成本:例如Redis Cluster
使用场景
- 降低后端负载:
- 对高消耗的SQL:join结果集/分组统计结果缓存。
- 加速请求响应:
- 利用Redis/Memcache优化IO响应时间
- 大量写合并为批量写:
- 如计数器先Redis累加再批量写DB
缓存更新策略
- LRU/LFU/FIFO算法剔除:例如maxmemory-policy。
- 超时剔除:例如expire。
- 主动更新:开发控制生命周期
- 低一致性:最大内存和淘汰策略
- 高一致性:超时剔除和主动更新结合,最大内存和淘汰策略兜底。

缓存粒度控制
- 通用性:全量属性更好。
- 占用空间:部分属性更好。
- 代码维护:表面上全量属性更好。


缓存穿透优化(大量请求不命中)

无底洞问题

热地key重建优化

Redis云平台cachecloud
Redis规模化运维
- 发布构建繁琐,私搭乱建
- 节点&机器运维成本
- 监控报警初级
快速构建(CacheCloud)
- 1.一键开启Redis。(Standalone、Sentinel、Cluster)
- 2.机器、应用、实例监控和报警。
- 3.客户端:透明使用、性能上报。
- 4.可视化运维:配置、扩容、Failover、机器/应用/实例上下线。
- 5.已存在Redis直接接入和数据迁移。
- 6.
https://github.com/sohutv/cachecloud







