
一、前言
一直以来,博主对最左侧原则的理解都是,比如给a,b,c加上索引,那么a,b可以用到索引,a,c也可以用到索引,但b,c是用不到的。包括这个a必须要在用到的第一个索引处。但是如果一个表中只有a,b,c三个字段,给他们加上联合索引(a,b,c),此时
SELECT * FROM test WHERE c=2;
可以用到索引吗? 在博主原来的理解中,可能毫不犹豫的就说用不到,为什么,因为没有根据联合索引的最左侧原则。但是事实上呢?一起来看下。
二、关于上面那个sql能不能用到索引
举个例子:
对于联合索引(col1,col2,col3),查询语句SELECT * FROM test WHERE col2=2;是否能够触发索引?
大多数人都会说NO,实际上却是YES。
原因:
EXPLAIN SELECT * FROM test WHERE col2=2;
EXPLAIN SELECT * FROM test WHERE col1=1;
观察上述两个explain结果中的type字段。查询中分别是:
type: index
type: ref
如果表中的字段除了(col1,col2,col3),还有别的字段。那么的 EXPLAIN 中结果将不会是 INDEX 而是 ALL。如果表中的字段只有(col1,col2,col3),那么的 EXPLAIN 中结果才会是 INDEX ,这种情况用到了mysql的覆盖索引。至于什么是覆盖索引,咱们下面再说。
根据上面的意思,我们可以知道,直接SELECT * FROM test WHERE c=2; 是可以用到索引的,但是为什么在执行计划中的展现不同?一个是index,一个ref呢?虽然用到了索引,但这个索引是联合索引吗?
三、知乎的一个解答
这是你的表结构,有三个字段,分别是id,name,cid
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8‘’
索引方面:id是主键,(name,cid)是一个多列索引。
下面是你有疑问的两个查询:
EXPLAIN SELECT * FROM student WHERE cid=1;
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
你的疑问是:sql查询用到索引的条件是必须要遵守最左前缀原则,为什么上面两个查询还能用到索引?
讲上面问题之前,我先补充一些知识,因为我觉得你对索引理解是狭隘的:
上述你的两个查询的explain结果中显示用到索引的情况类型是不一样的。可观察explain结果中的type字段。你的查询中分别是:
1、 type: index
解释:index: 这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。所以:对于你的第一条语句:EXPLAIN SELECT * FROM student WHERE cid=1;判断条件是cid=1,而cid是(name,cid)复合索引的一部分,没有问题,可以进行index类型的索引扫描方式。explain显示结果使用到了索引,是index类型的方式。
2、 ref:
解释: 这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一 一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
有些了解的人可能会问,索引不都是一个有序排列的数据结构么。
不过答案说的还不够完善,那只是针对单个索引,而复合索引的情况有些同学可能就不太了解了。下面就说下复合索引:以该表的(name,cid)复合索引为例,它内部结构简单说就是下面这样排列的:
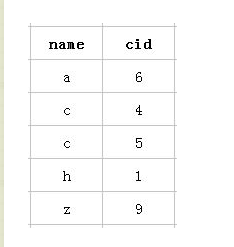
创建复合索引的规则是首先会对复合索引的最左边的,也就是第一个name字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的cid字段进行排序。其实就相当于实现了类似 order by name cid这样一种排序规则。
所以: 第一个name字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个cid字段进行条件判断是用不到索引的,当然,可能会出现上面的使用index类型的索引。这就是所谓的mysql为什么要强调最左前缀原则的原因。
那么什么时候才能用到呢?当然是cid字段的索引数据也是有序的情况下才能使用咯,什么时候才是有序的呢?观察可知,当然是在name字段是等值匹配的情况下,cid才是有序的。发现没有,观察两个name名字为 c 的cid字段是不是有序的呢。从上往下分别是4 5。这也就是mysql索引规则中要求复合索引要想使用第二个索引,必须先使用第一个索引的原因。(而且第一个索引必须是等值匹配)。
所以对于你的这条sql查询:
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
没有错,而且复合索引中的两个索引字段都能很好的利用到了!因为语句中最左面的name字段进行了等值匹配,所以cid是有序的,也可以利用到索引了。
你可能会问:我建的索引是(name,cid)。而我查询的语句是cid=1 AND name=‘小红’; 我是先查询cid,再查询name的,不是先从最左面查的呀?
好吧,我再解释一下这个问题:首先可以肯定的是把条件判断反过来变成这样 name=‘小红’ and cid=1; 最后所查询的结果是一样的。那么问题产生了?既然结果是一样的,到底以何种顺序的查询方式最好呢?所以,而此时那就是我们的mysql查询优化器该登场了,mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。
作者:沈杰
链接:https://www.zhihu.com/question/36996520/answer/93256153
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
4、总结
上面的例子是我见过最通俗易懂的答案,总结来说就是:
最左侧原则不是要求索引(a,b,c)必须按照where a=x and b=x and c=x 才可以。顺序是可以互换的,关键是要有这个a,而且这个a一定要是等值匹配。
四、上面提到了覆盖索引,那么覆盖索引是什么,怎么产生或者使用到?
答:
覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。索引的字段不只包含查询列,还包含查询条件、排序等。
链接:https://my.oschina.net/loujinhe/blog/1528233
覆盖索引的用法:https://www.cnblogs.com/happyflyingpig/p/7662881.html
由解释我们可以知道,如果一个数据表中的每个字段都建的有索引,那么此时不管用哪个字段作为搜索条件都是可以用到索引的,也就是覆盖索引了。但是要注意,真正让你的mysql性能飞起来的还是ref,所以尽量还是按照已有的那些索引规则写sql吧。
以前总是觉得自己懂了最左侧原则的概念,知道怎么用就好了。实际上呢,还是一堆疑问,始终是知其然不知其所以然。不过这次终于明白的更深了一层。你懂了吗?
end









热门评论
-

离场2019-06-28 0
查看全部评论图片挂了 很重要