
【一凡sir,原创文章,禁止转载】
背景
我们在程序设计时,有一个极其重要的非功能性指标:性能,总是无时无刻不缠绕在程序员的脑海,尤其是我们开发的面向大众的Web服务,网络接口等程序。
高性能的程序可以使用更少的服务器资源提供同样规模的用户请求(成本低),也可以更快的响应用户请求(体验好)。
当然,高性能的程序设计也会更加复杂,开发也有更大难度。
这次的内容,我们面向高性能程序设计方向,来讲一讲其中最核心最重要的缓存。
希望能够帮助大家更好的理解缓存为王的含义,也能更好的利用缓存,设计出高性能的程序。
大纲:
- 1 高性能程序与时间、空间的关系
- 2 无处不在的缓存,硬件与软件
- 3 系统中的缓存设计
- 4 总结,缓存为王
0 找找看,人体中的缓存、缓冲区
头
- 大脑的短时记忆和长期记忆,外部持久存储的书籍
- 短期、长期记忆,比临时查阅书籍更快、更灵活
- 计算机有非常强大的存储、检索和运算能力,可以作为大脑非常好的补充
颈椎 - 上接头部,下衔接胸椎,承上启下,多节
- 头部与胸部的衔接,保证灵活性
- 颈椎病、腰间盘突出,问题是类似的,长期保持同一个姿势造成无法修复的劳损
- 建议多做以下动作:上九天揽月,下五洋捉鳖,简化后就是“抬头,转体”
胸腹 - 大量的冗余空间,孕妇和胖子的潜力
- 更大的冗余区,更好地支持生育和度过饥荒
- 可惜,时代变了,审美变了,这倒是成了缺点
关节 - 软骨、关节腔,避免骨头硬碰硬和磨损
- 提供了足够的灵活性,减少冲击和磨损
- 既要硬,又要灵活,还要做杠杆运动,真是难为了关节
脚 - 减震
- 扁平足,失去了减震和缓冲
- NBA球星麦迪就是扁平足,而且他的技术动作不合理,所以一直受伤病困扰
1 高性能程序与时间、空间的关系

哪种地铁闸机,占用空间小、过关快、体验好、可靠性好、安全性好?还有更多类型的闸机可以比较的。
1.1 性能,速度与时间
- 吞吐率:单位时间内处理的请求数
- 吞吐量:对网络、设备、端口、虚电路或其他设施,单位时间内成功地传送数据的数量
- TPS:每秒钟系统能够处理事务或交易的数量
- 性能=速度=数量/时间,单位时间内处理的数量越多,性能越好
关注程序性能,首先要关注单次请求的执行时间,10ms的等待时长肯定是要比100ms的执行时间要更好。然后就是在压力测试下(并发&集群),我们会关注上面的吞吐率、吞吐量、TPS这些关键指标。
1.2 系统性能预估
CPU密集型,如:数据排序
假设:单次请求耗时 Tms,服务器CPU数量 C核,集群的服务器数量S台
QPS=1000/TCS (公式是理想状态,单机、分布式并发中无共享无状态)
IO密集型,如:依赖大量网络API/数据库/文件(IO耗时)
假设:单次请求耗时 Tms,服务器CPU数量 C核,集群的服务器数量S台,IO耗时1/2Tms
QPS=1000/(T-1/2T)CS(理想状态下,API不是瓶颈)
服务线程数量预估
CPU密集型,线程数量与CPU数量一致(redis)
IO密集型,要考虑IO的开销,适当放大线程数量,如:1/2时间在IO中,那么线程数量可以是CPU的2倍(Java Web的线程数,PHP-fpm的进程数)
增加CPU数量,涉及到并发编程。
增加服务器数量,涉及到分布式系统设计。
所以,提高系统性能,还需要提高并发编程的能力,提高分布式系统设计的能力。
1.3 降低单次请求执行时间
减少CPU运算量
简化运算逻辑,优化算法(少循环,少编解码等)
简化数据结构,降低时间复杂度,减少内存复制
减少IO耗时
减少API/数据库/文件的依赖
优化API/数据库/文件的性能
利用缓存
缓存复杂运算后的结果
缓存IO的返回值
最好的优化手段就是砍需求,没有代码就有最好的性能。
1.4 缓存,空间换时间
增加的缓存空间
缓存IO返回值
缓存运算结果
缓存IO返回值以及运算结果
增加的处理逻辑
缓存数据的读取和验证
数据更新到缓存
减少的处理时间
减少IO耗时
减少大量的CPU运算
离CPU越近的数据,处理越快;减少的处理逻辑就是优化的时间。缓存就是这个法宝。
1.5 缓存,是否多多益善
下面三种情况建议尽量使用缓存来做优化。
减少的处理时间显著(性能差异明显)
原来的逻辑太复杂,性能很低下,如:超过50ms
原来的IO耗时太长,如:网络延时超过50ms,或者IO处理耗时超过50ms
增加空间有限(成本提高)
缓存的数据空间尽量小,如果实在很大,可以考虑把数据压缩后缓存,如:博文正文页(计算换空间)
缓存数据的位置,可以在进程内,外部服务进程,甚至文件、数据库中(缓存后速度比缓存前的性能提高明显才有益)
单个实例进程的容量尽量别太大(超过16G,32G),以减小迁移、重启、故障造成的影响(运维的负担也不能忽视)
增加的处理有限(开发难度,运算次数)
避免缓存频繁失效(命中率太低)
避免缓存频繁更新(数据一致性复杂)
1.6 总结,高性能程序与时间、空间的关系
高性能程序设计,重点关注
方法一,减少单个请求的处理时间(程序优化)
方法二,增加CPU,线性提高系统的吞吐率(并发编程)
方法三,增加集群的服务器,线性提高系统的吞吐率(分布式系统设计)
空间换时间,缓存的优势
场景一,缓存前的处理速度太慢,IO耗时太长(超过50ms)
场景二,缓存数据具有极高的命中率(超过90%,理想是100%)
避免缓存的陷阱
场景一,程序没有高性能需求,程序原本性能已经非常高(不要为缓存而优化)
场景二,缓存容量爆炸性增长(成本太高)
场景三,缓存数据更新太频繁(命中率低,数据一致性差)
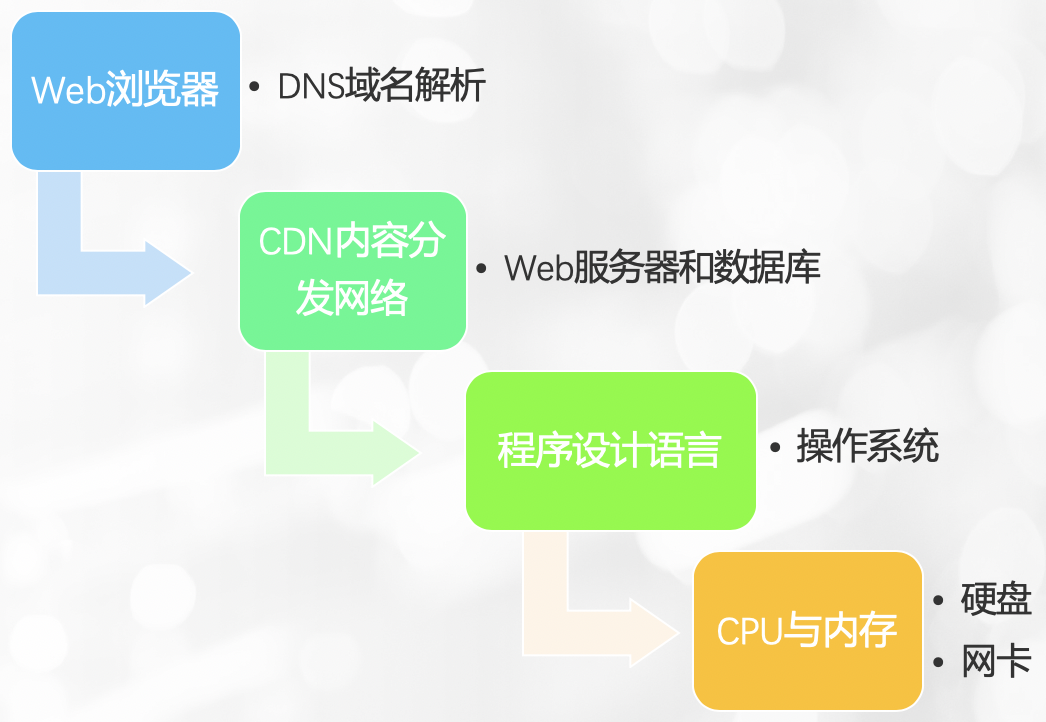
2 无处不在的缓存,硬件与软件
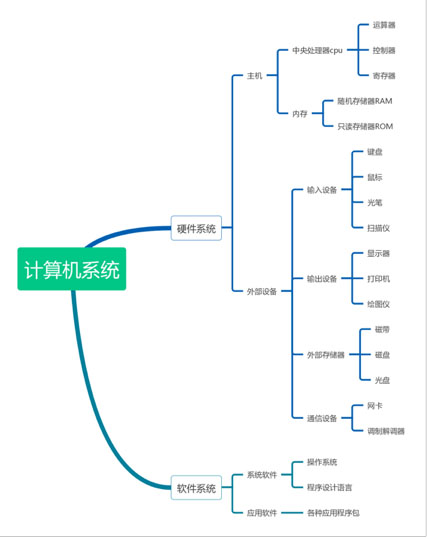
- CPU与内存
- 硬盘
- 网卡
- 操作系统
- 程序设计语言
- Web服务器和数据库
- CDN内容分发网络
- DNS域名解析
- Web浏览器
2.1 CPU与内存
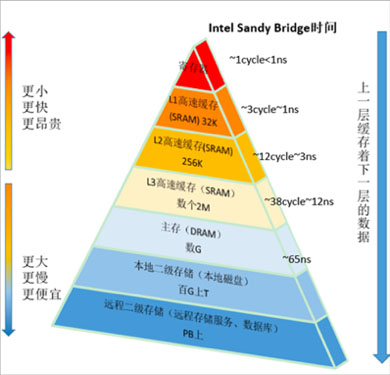
CPU内的寄存器/L1/L2/L3
- 速度不一样
- 容量不一样
- 成本不一样
计算机内存 - 容量更大
- 成本更低
- 速度稍慢(比硬盘、网络快很多)
更多参考: 并发编程与锁的底层原理
2.2 硬盘内的缓存


SATA传来的数据和盘片的实际操作间加一个缓冲
- HDD的延迟是ms级别,缓存是ns级,相差数万倍
- 缓存容量增加,提高命中率
- 突然掉电导致数据丢失的风险增大
- 固态混合硬盘,内置8G/16G固态硬盘,缓存容量更大
- 固态硬盘,随机读写速度更快
为什么机械硬盘的缓存不是越大越好?
缓存容量增加,带来的成本提高,突然掉电导致数据丢失的风险增大
2.3 网卡的发送/接收缓存
发送缓存
- 网卡有包就发,包太多了就放入缓存队列,缓存满了就丢包并且告诉系统丢包了
- TCP协议具有流控和拥塞检测功能,防止发包太快造成丢包(UDP不可靠传输)
接收缓存 - 网卡接收数据,放入接收缓存,一次数据接收完成后,网卡驱动程序,向CPU发送信号,提示网卡有新数据到来。
- 操作系统从网卡的接收缓冲队列中读取数据,交给应用程序处理。
2.4 操作系统的缓存
缓冲文件系统
- 在内存开辟一个“缓冲区”,为程序中的每一个文件使用(读写文件先操作缓冲区)
- fopen, fclose, fread, fwrite, fgetc, fgets, fputc, fputs, freopen, fseek, ftell, rewind等
网络相关缓存设置 - /proc/sys/net/core/wmem_max 最大socket写buffer
- /proc/sys/net/core/rmem_max 最大socket读buffer
- /proc/sys/net/ipv4/tcp_wmem TCP写buffer
- /proc/sys/net/ipv4/tcp_rmem TCP读buffer
- /proc/sys/net/core/netdev_max_backlog 进入包的最大设备队列
- /proc/sys/net/core/somaxconn listen()的默认参数,挂起请求的最大数量
- /proc/sys/net/ipv4/tcp_max_syn_backlog 进入SYN包的最大请求队列
操作系统磁盘缓存,可以减少磁盘机械操作。
更多参考: - 不带缓冲区open和带缓冲区的fopen的区别
- linux 内核参数优化
2.5 程序设计语言的缓存

PHP的缓存
- opcache,省去了PHP源码到opcode的转换过程,并且保证脚本对应的opcode都保存在内存中
- apcu,共享内存,缓存PHP程序中的用户数据
Java的缓存 - JIT,运行时生成机器码,比Java编译器优化后的bytecode性能更好
- ehcache,缓存数据有两级:内存和磁盘
编程语言的版本升级,我们最关注的除了语言特性的变化,还有就是关于性能的提升。其中有优化数据结构的,也有优化GC的,当然也有引入缓存/JIT这些技术。
2.6 Web服务器和数据库
nginx中的缓存
- 减少应用服务器请求
- proxy_cache,内容缓存在本地文件中
mysql中的缓存 - 减少文件系统I/O
- SqlSession,直接返回结果(四种失效情况:Sql不同,条件不同,增删改操作,清空了缓存)
- sort_buffer_size 排序缓冲区大小,超过的时候就用到磁盘中排序
- join_buffer_size 每个联合查询分配的缓冲区
- read_buffer_size 对MyISAM表进行全表扫描时分配的读缓存池的大小
- read_rnd_buffer_size 索引缓冲区的大小
数据库缓存,减少文件系统I/O。
更多参考:mysql缓冲和缓存设置详解
2.7 CDN内容分发网络的缓存
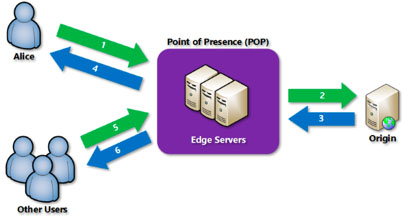
分布式网络
- 全国/全球多地部署很多Web服务器缓存节点
- DNS动态解析,让客户端请求就近访问到Web服务器缓存节点
Web内容缓存 - 缓存源服务器的内容,有缓存时就不需要回源
- 可以支持目录规则、文件扩展名等设置缓存策略
- 可以手动刷新指定目录、文件的缓存数据
CDN,加速终端连接和请求速度,减少源站点压力
2.8 DNS域名解析
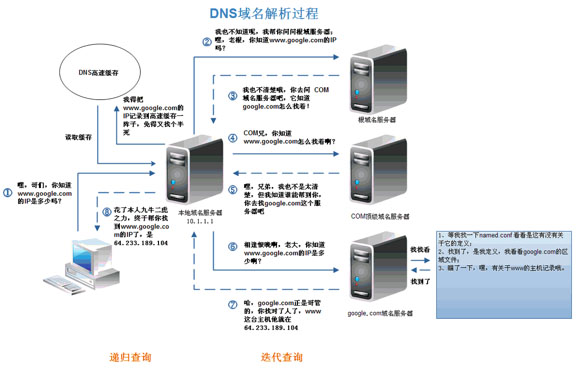
- 浏览器的DNS缓存,60s, chrome://net-internals/#dns
- 操作系统的DNS缓存, ipconfig /displaydns
- 本地HOSTS文件
- C:WindowsSystem32driversetchosts
- /etc/hosts
- 远程多级DNS服务器
- 路由器,运营商
- 根服务,顶级域名服务
- 二级域名服务,三级域名服务等
DNS服务是典型的分布式分层缓存系统,高效可靠,当然也是非常核心的系统,大面积断网的事件就跟DNS故障有关。
更多参考:浏览器的DNS缓存
2.9 Web浏览器
客户端浏览器缓存,减少对网站的访问。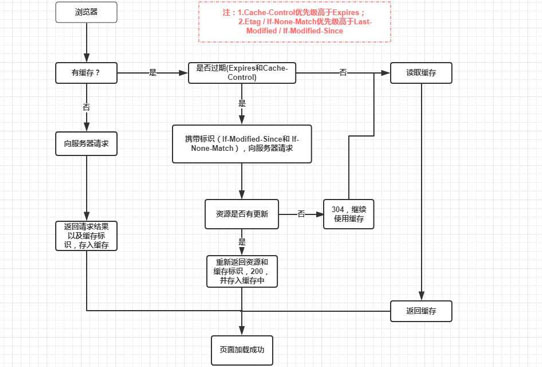
Web内容缓存
- 客户端直接读取缓存,减少对Web服务器的请求
- 强制缓存 cache-control, expires (from memory cache, from disk cache)
- 协商缓存 etag, If-None-Match, last-modified, If-Modified-Since (304 not modify)

Cookie/LocalStorage/SessionStorage - 数据存储在客户端,减少对服务端的依赖
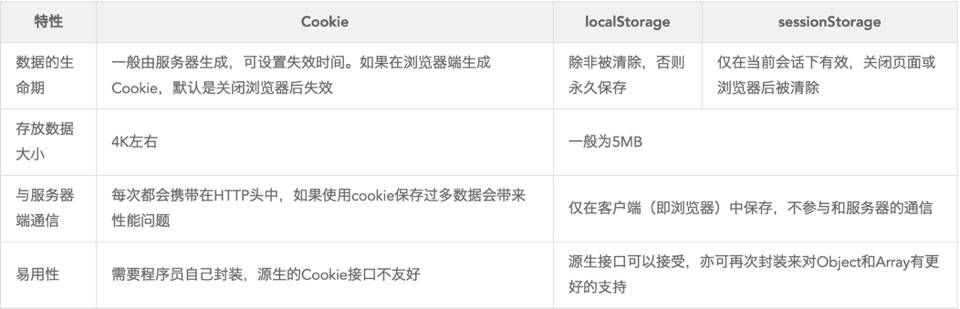
更多参考: - 彻底理解浏览器的缓存机制
- 详说 Cookie, LocalStorage 与 SessionStorage
2.10 总结,无处不在的缓存,硬件和软件
缓冲区buffer
- 避免频繁读写
- 一次性分配稍大的空间
- 一次性读写多一点内容
缓冲队列 - 通过队列,削峰填谷
- 不同设备、应用的读写速度不一样
多级缓存,分布式缓存 - 本地更快,减少远程数据依赖
- 缓存数据使用更快,减少数据读取和运算
问:在浏览器中输入一个网址 http://www.imooc.com/ ,接下来会发生什么?
3 系统中的缓存设计
先来看看2个典型的常见的软件系统。
3.1 社区bbs的缓存设计
数据模型
- 用户,板块,主题,帖子,回复
页面 - 首页,板块帖子列表页,帖子详情页,用户资料页
操作 - 浏览,发帖,回帖,置顶
缓存数据 - 全量永久缓存:用户(uid -> map),板块(all -> json),置顶帖(all -> json)
- 部分临时缓存:帖子列表页数据(多种排序, fid-displayorder -> tids), 主题浏览量(tid -> views),帖子数据(tid -> map),用户帖子列表页数据(uid -> json)
- 页面缓存:首页,帖子详情页
3.2 电商系统的缓存设计
数据模型
- 用户,分类,商品SPU,SKU,订单,支付
- 评价,收藏,购物车,联系地址
页面 - 首页,分类商品推荐页,搜索商品列表页
- 商品详情页,用户订单列表页
操作 - 浏览,搜索,下单,支付,推荐,评价
缓存数据 - 全量永久缓存:用户,分类,商品,商品SKU库存,推荐
- 部分临时缓存:大量的临时推荐位,人工干预内容,相关商品,置顶评论等
- 页面缓存:首页,搜索页,商品详情页
3.3 缓存设计,最佳场景,永久缓存
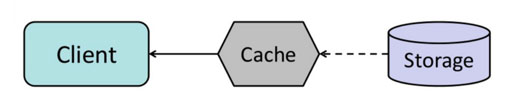
数据只读,极少更新
- 配置类,全局共享数据(置顶帖)
- 后台定时任务生成的数据(推荐内容)
数据占用空间有限 - 单个key的内容比较小(用户信息)
- 总数量比较有限(商品信息)
数据结构简单,容易快速查找 - key-string 直接得到完整数据
- key-hash 易于部分数据读取和更新
- key-list 双向队列
- key-sortedset 有序集合,索引排序
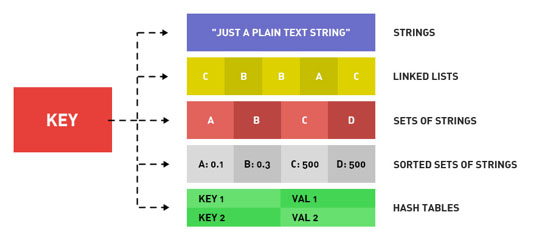
3.4 缓存设计,较好场景,临时缓存
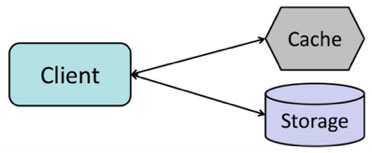
数据读多写少,读取速度慢
- 用户、内容数据,如:用户信息,帖子信息等
- 缓存快过数据库
数据占用空间较大 - 帖子内容,整页缓存
- 过期或者未命中再从数据库读取
保证较高的命中率,90%以上 - 缓存容量较大,过期/失效的缓存减少,命中率提高
- 更新的频率降低,命中率提高
- 更新的时候主动更新缓存,命中率提高
- 合适的缓存淘汰策略,FIFO/LRU/LFU/TTL/RANDOM
3.5 缓存设计,特殊场景,性能优先
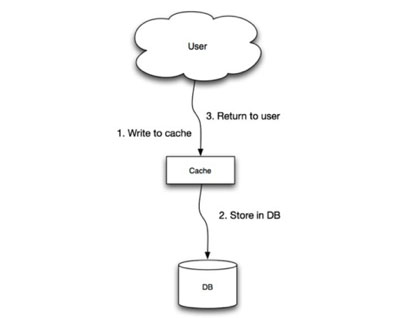
读写过于频繁的时候
- 帖子浏览量更新,更新到缓存,定时更新到数据库,读取数据库+缓存
- 秒杀时,商品库存扣减,隔离数据库的压力
排序方式太多,索引效率下降的时候 - 有序集合类缓存,代替数据库索引
数据表分拆太细,连表查询效率低的时候 - 直接把联合查询的数据缓存起来
3.6 缓存设计,不适合场景,成本超过收益
内容更新太频繁,命中率太低
- 用户的呼吸状态如果也缓冲起来,那么这时候的用户信息缓存命中率就太低了
- 完全散列随机的key值遍历查找,缓存无法重复利用
数据写入超过读取次数 - 日志类、流水式的固定内容,很少使用,不适合用缓存
系统自身性能很好 - 没必要增加缓存来提高不足10%的速度
系统访问量很有限 - 性能需求不高,没必要增加复杂度来做优化
3.7 总结,系统中的缓存设计
提高缓存命中率
- 缓存永不过期,缓存空间充足,数据直接写入和更新缓存
- 扩大缓存容量,减少缓存过期或者失效的概率(内存+SSD文件)
规划缓存容量 - 优先把永久缓存的内容放进去
- 再把读多写少的内容放进去
- 再有富余容量,把实时性要求不高的内容放进去
- 大容量使用简单,风险高;多实例连接多,操作复杂,可用性好
缓存性能优势 - 内存缓存 > 数据库 > 硬盘文件
- 进程内数据 > 本地缓存 > 远程数据
- 缓存数据读取后运算后的复杂结果
4 总结,缓存为王
高性能程序设计与缓存的效果(连蒙带猜)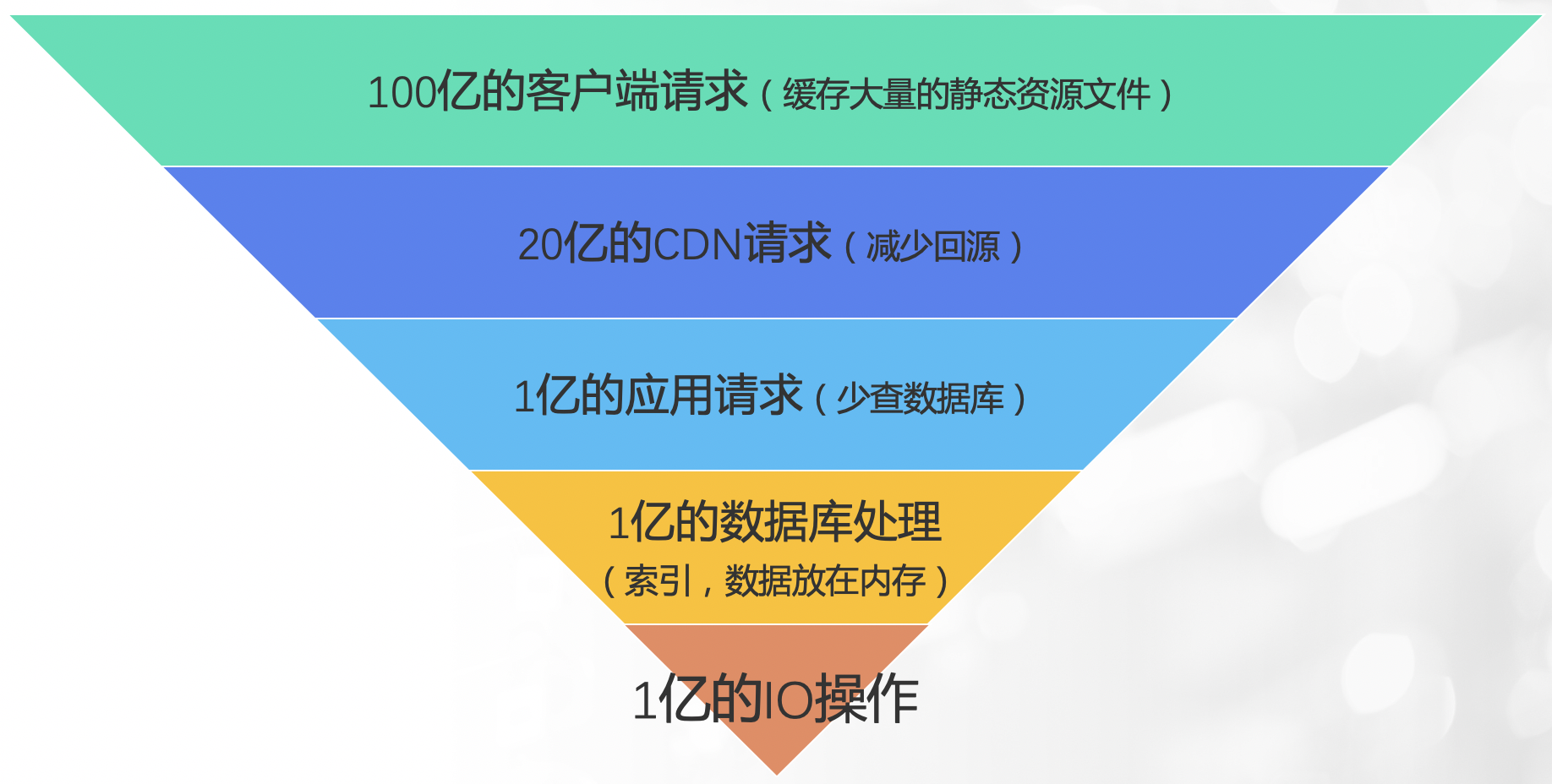
如果没有缓存的情况下,100亿的客户端请求,最后落到数据服务器上会有上万亿的IO操作。
老司机箴言:
- 设计时,分层分级。
- 执行时,少查少写少依赖,Less is more。
- 别让硬盘抗性能,别让内存保持久,别让网线抗稳定。
高性能程序设计的漫漫求索之路

数据结构和算法(应用优化)
- 数组、链表、集合、哈希表、二叉树等
- 排序算法:冒泡、快速、归并等
并发编程的问题(增加CPU) - 共享变量的读写,线程安全性问题
- 数据存储、依赖服务等瓶颈点
分布式系统设计(增加服务器) - 有状态服务高可用和数据一致性问题
- 全局、中心节点的可靠性问题
缓存优化(空间换时间) - 精细化分析和设计,提高命中率和可用性
- 监控工具、运维工具等
总结,缓存为王
高性能程序设计,使用缓存来优化可能会是第一选择。只是,方法虽然简单,过程还是曲折的。每一次缓存设计,都还是要针对具体场景和需求,制定最合适的方案,要考虑的地方也还是有很多。
- 速度、成本的平衡(开发速度、执行效率,人力成本、服务器成本)
- 空间、时间的平衡
- 复杂、简单的平衡
- 设计方案,没有最优,只有最合适
- 高性能程序系统,一个动态演进的过程

关注我的实战课程
《PHP秒杀系统 高并发高性能的极致挑战》
《Go语言实战抽奖系统》















热门评论
-

慕神814643_浅川好孩子2019-05-31 2
-

慕神814643_浅川好孩子2019-05-31 2
-

吧啦咪呀啾啾啾2019-06-01 0
查看全部评论老师开个实战课讲讲?
老师开个实战课讲讲?
讲得好精辟啊, 谢谢大佬