
安妮 发自 凹非寺
量子位 出品
平静的水面上,剧变突然出现。

一条黑色弧线从半空延伸而下,划过半个圈。继而自己填满,俨然一座岩山,就这样落在水中间。
水面漾起波纹。揉揉眼睛,绝不是看花了眼:你看那岩山纹路崎岖,倒影也是清晰可见。
第二座、第三座,也接踵而至。
透过现象看本质,控制这一切的,都是电脑前那个手握鼠标乱涂鸦的程序员。
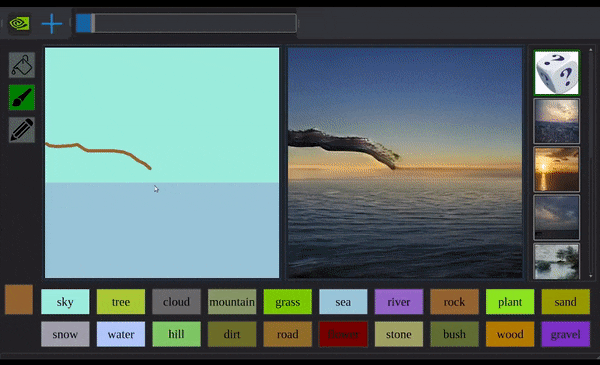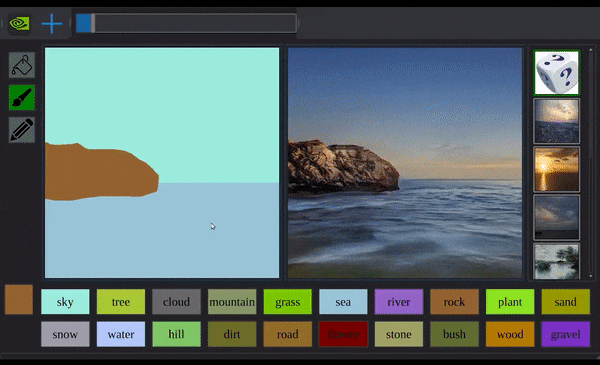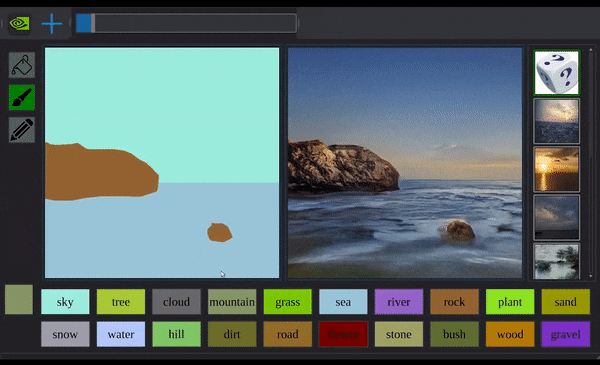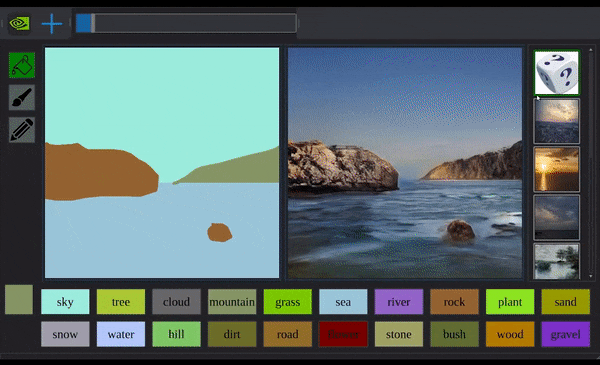
英伟达程序员の现实扭曲力场,发动!

他手握的工具,名叫GauGAN,和印象派大师高更(Gauguin)不到一字之差,而绘画的逼真程度又远在其上。
除了凭空造山,还能秒加飞流直下的大瀑布:
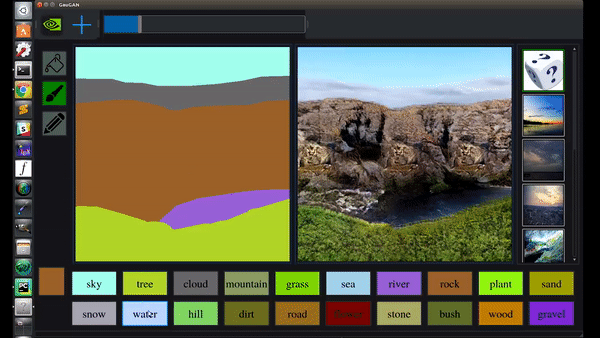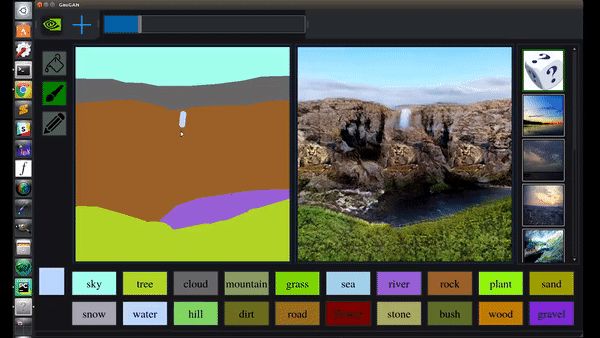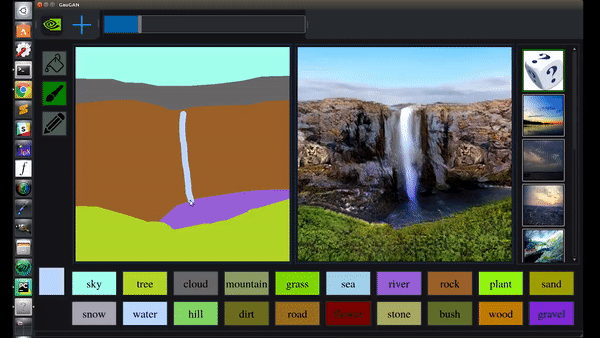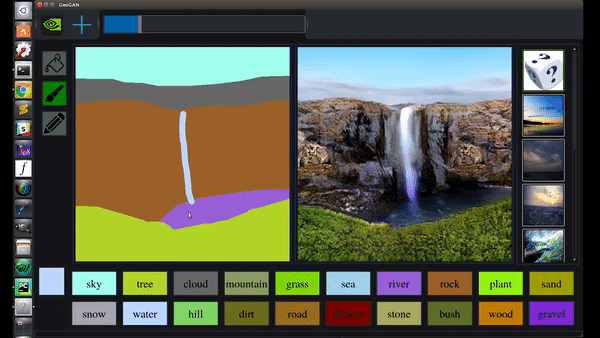
栽棵树什么的,就更是小菜一碟:

照片里该有什么,全凭鼠标安排。
除了造出不存在的物体,GauGAN还能穿越日夜,扭曲季节:
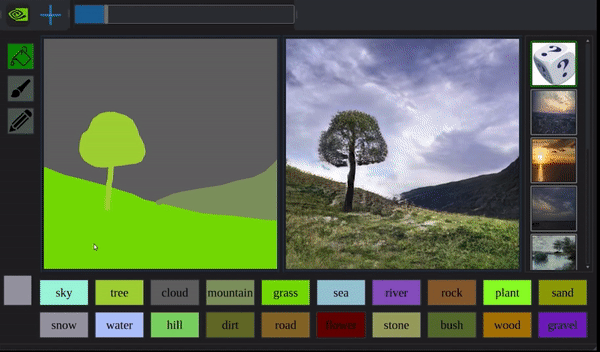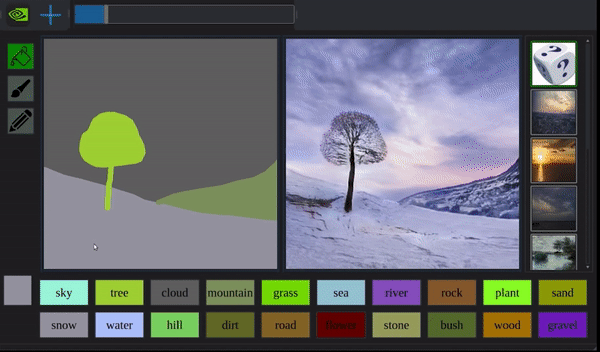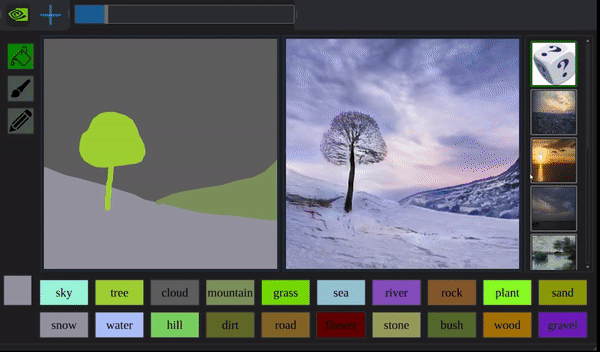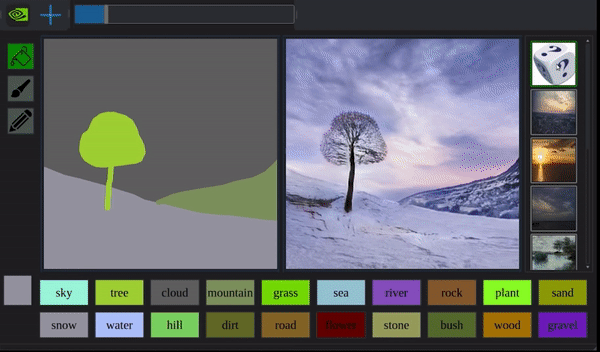
而且它造出来的景物,细致到以前的算法都望尘莫及。

那些对细节要求甚高的作品,比如运动场景、动物照片等等,它也都能根据一张涂鸦生成出来。

有Twitter网友发出来自英伟达GTC展厅的惊呼:
妈呀我被自己的艺术能力惊呆了!
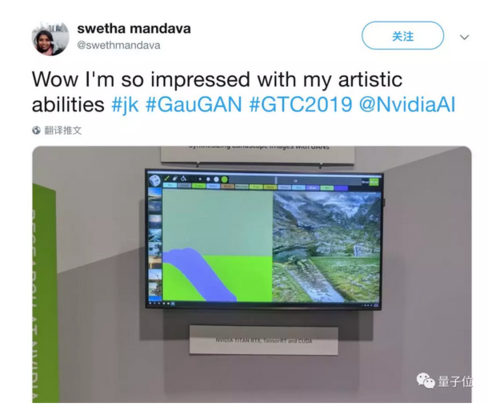
神仙操作,大洋此岸的量子位自愧不如。
好了,正式介绍一下英伟达出品的GauGAN:你画一幅涂鸦,用颜色区分每一块对应着什么物体,它就能照着你的大作,合成以假乱真的真实世界效果图。在AI界,你的涂鸦有个学名,叫“语义布局”。
要实现这种能力,GauGAN靠的是空间自适应归一化合成法SPADE架构。这种算法的论文Semantic Image Synthesis with Spatially-Adaptive Normalization已经被CVPR 2019接收,而且还是口头报告(oral)。
这篇论文的一作,照例还是实习生。另外几位作者来自英伟达和MIT,CycleGAN的创造者华人小哥哥朱俊彦也在其中。
在基于语义合成图像这个领域里,这可是目前效果最强的方法。
神奇的空间适应
在论文中,研究人员揭开了SPADE的神秘面纱。
此前,在语义图像合成领域有一套“流水线式”的加工流程:直接将语义布局(Semantic Layout)作为深度神经网络的输入,然后通过卷积、归一化和非线性层的处理,输出合成图像。

推断语义布局合成图像 | 图片来自论文Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis
但是,这种传统神经网络架构并不是最优解,其中的归一化层通常会让输入语义蒙版中的信息流失,导致合成效果变差。
为了解决这个问题,研究人员提出了一种新的方法,空间适应标准化(SPatially-Adaptive (DE)normalization),简称SPADE。
这是一种条件归一化层,它通过学习到的空间适应变换,用语义布局调节激活函数,让语义信息在整个网络中有效传播,避免语义信息流失。
SPADE与批标准化(Batch Normalization)类似,激活函数channel-wise是标准化的,但在很多标准化技术中,实际标准化操作后就应用到了学习过的仿射层(Affine Layer)。
但在SPADE中,仿射层是从语义分割图中学习的。这类似于条件标准化,不过所学习的仿射参数现在需要空间自适应,也就是对每个语义标签使用不同的缩放和偏差。
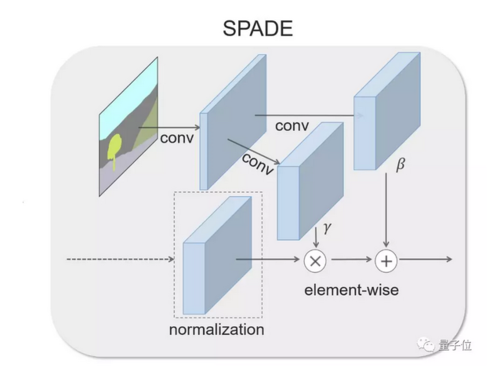
就这样一个小小的改变,让语义信号可以作用于所有层输出,不会在生成图像中丢失语义信息。
SPACE生成器结构
此外,因为语义信息是通过SPADE层提供的,因此随机向量成为神经网络的输入,所以,你还能随心改变图像的画风。
效果+++
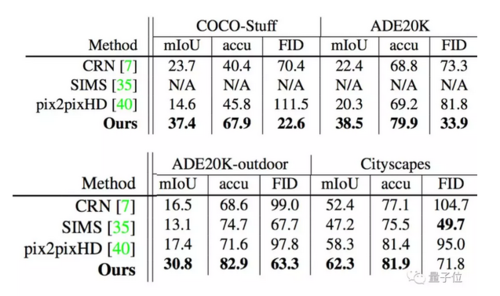
研究人员用COCO-Stuff、ADE20K和Cityscapes等数据集测试SPADE与前人的效果如何。
结果发现,这项新研究面前,此前CRN、pix2pixHD等明星语义图像合成方法效果已经成为渣渣:
此前的pix2pixHD和CRN算法只能分辨开天和海的颜色,而GauGAN却遥遥领跑,连渐变的海水颜色和四散的浪花都合成出来了,甚至运动场的场地线:

此外,研究人员用平均检测评价函数(mIoU)、像素准确度(accu)和FID(Frechet Inception Distance)三个维度评估SPADE与其他语义合成模型的评分,SPADE均优于其他模型。
传送门
目前,论文已经放出,研究人员表示代码、训练模型和所有图像马上就要来了。
在正在举办的英伟达GTC 19大会上,GauGAN已经亮相了。美国时间周三周五Ting-Chun Wang和Ming-Yu Liu还将进行相关演讲。
论文地址:
https://arxiv.org/abs/1903.07291
GitHub地址(代码即将上线):
https://github.com/NVlabs/SPADE
项目地址:
https://nvlabs.github.io/SPADE/
最后,附上GTC现场Demo演示视频~
作者系网易新闻·网易号“各有态度”签约作者
— 完 —





