

随着大数据的热度与市场需求不断提升,学习大数据的小伙伴越来越多,然而,大家的个人电脑平时可能都用做了打游戏,看剧,逛论坛,没有配置过一套适合于学习大数据的环境,于是乎感叹万事开头难,今天,就带大家打开大数据世界的大门,带领大家在自己的电脑下配置Hadoop+Spark+Mysql,当然,还有Python3+Jupyter Notebook的开发环境。

PART1——Windows系统下的配置(以Win7为例)
一、Python3与Jupyter Notebook安装
众所周知,Python是当下最火热的一门编程语言,它以及其简单的编码方式完成程序设计,可以让新手在很短时间内上手,且具备很多实现各种功能的库,学习大数据,Python可谓是必备技能。关于版本,有Python2与Python3两个版本,推荐大家使用Python3,因为Python2在2020年就不会再进行官方维护了,目前来讲,Python3也逐渐成为主流。话不多说,一起跟着柯南来动手吧。
1.首先进入https://www.python.org/downloads/,点选Download Python 3.6.5,如下图所示(确认一下是Windows版本的):

2.下载后,打开对应安装文件,如下所示共色方块所示,勾选“Add Python 3.6 to PATH”,并选择“Customize installation”。


然后点击“Next”。
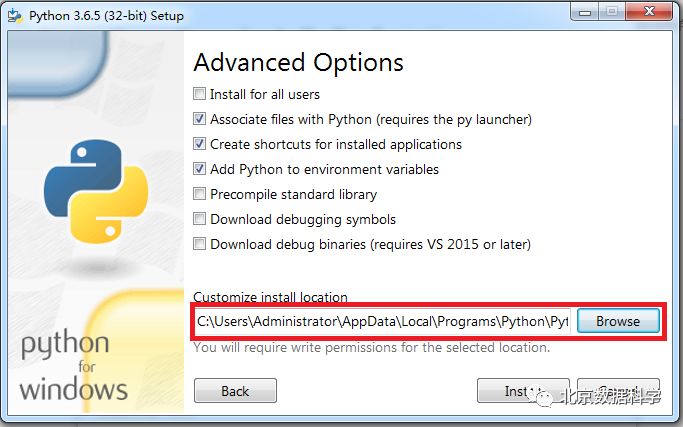
修改安装路径(不要装载C盘,不然某天你可爱的机器挂掉,重装系统就都没了)。然后点击“Install”进行安装,等待很短的时间,就安装完毕了。
安装完毕后进行测试,启动cmd(可以按如下方式启动)。

在cmd中输入Python,就会进入Python的命令行模式。完成!
3.配置Jupyter Notebook开发环境
Python的开发环境有很多,比如Pycharm,Jupyter Notebook等,初学者可以选择使用Jupyter NoteBook,方便快捷,相当于一个美化版和强化班的命令行工具。Python中带有一个叫做pip的工具,用来方便快捷的进行第三方库和工具的安装。
同样先启动cmd,然后如下所示,输入pip install jupyter。

等待一段时间,安装完成。然后在cmd中输入jupyter notebook启动。
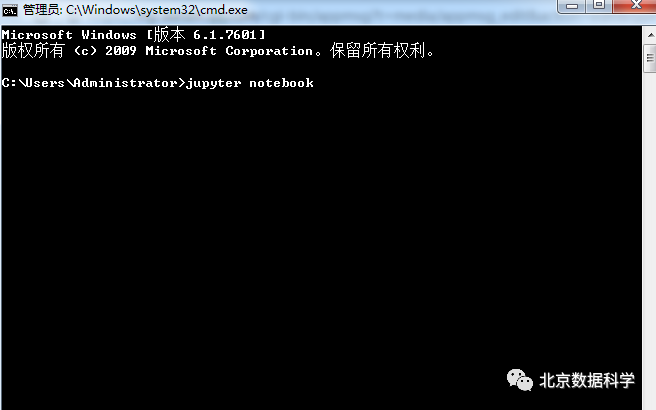

看到上面的界面,就算是大功告成了。点击“New”,再点击“Python”(由于柯南的电脑同时安装了Python2和Python3,可能大家的选项与我不同,不过没事,不要觉得你安装的有问题)。

完美!
二、Mysql安装
业界的数据分析工作,需要具备的最主要的技能之一就是SQL(或HQL,二者在语法上很相似),我们可以在计算机上安装一个Mysql,用来练习SQL。
进入https://dev.mysql.com/downloads/mysql/,选择与自己电脑位数匹配的mysql安装压缩文件,如下所示。

将压缩包解压到某个文件夹,解压后会生成mysql-5.7.11-winx64文件夹(下载的版本不同,这个文件夹的名字也不同),进入该文件夹,创建一个my.ini文件(生成一个名为my.txt的文本文件,然后在文件中编写内容,保存,最后将后缀txt修改为ini)。文件中内容为:注意将对应目录进行修改。

初始化和启动Mysql服务:
1.以管理员权限运行cmd
2.进入mysql的bin文件夹下
3.初始化,生成data文件夹
>mysqld --initialize-insecure (不设置root密码,建议使用)
4.安装MySql服务
>mysqld -install
5.启动mysql
>net start mysql
登陆mysql
>mysql -u root -p

第一次登录时无需密码直接回车登录
登录mysql之后,设置root密码(方便起见可以不设置密码,如果你有保密需求,那就设置一下)
>set password for root@localhost = password('YourPassword');
或者使用mysqlamdin修改root密码
>mysqladmin -u root -p password NewPassword
大功告成!
三、Hadoop+Spark搭建
分布式计算是大数据技术中的一个重要门类,故Hadoop和Spark相关技术也是很多朋友感兴趣的,那么就需要有对应的环境。接下来教学Hadoop和Spark环境搭建。
1.JDK安装
首先,我们需要安装java环境,即JDK的安装,进入http://www.oracle.com/technetwork/java/javase/downloads/index.html,然后按照下图方式点选。

进入如下界面,然后点击共色方框中的“Accept License Agreement”,选择对应版本(windows版本)进行下载,完成下载后使用下载的exe文件进行安装。
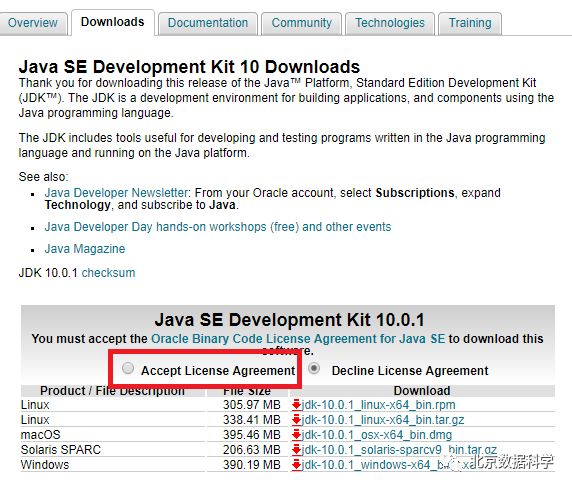
然后需要配置环境变量。依次进行如下操作:右键“我的电脑(或计算机)”——单击“属性”——单击“高级系统设置”,进入如下所示界面:

在“高级”选项卡中选择“环境变量”,进入如下界面:

在系统变量中,找到变量名为“Path”的选项,点击“编辑”,以修改其值。

在“变量值”的输入框中,在最后加上一个半角分号,作为JDK路径与前一个路径的分割,然后把JDK文件夹中bin文件加的路径写在分号后面。完成环境变量的配置。
启动cmd,输入java -version,如果看到对应的java版本,就说明配置完成,如下所示。

2.Scala安装
https://www.scala-lang.org/download/all.html

安装成功后,默认会将Scala的bin目录添加到PATH系统变量中去(如果没有,和JDK安装步骤中类似,将Scala安装目录下的bin目录路径,添加到系统变量PATH中),为了验证是否安装成功,开启一个新的cmd窗口,输入scala然后回车,如果能够正常进入到Scala的交互命令环境则表明安装成功。

完成!
3.Spark安装
Spark的安装比较简单,进入http://spark.apache.org/downloads.html,选择需要的版本(注意它会提示你需要Hadoop版本的对应),如我们选择Spark2.3,需要Hadoop2.7或更新的Hadoop版本支持,然后点击下方的下载,下载tgz文件。

这里使用的是Pre-built的版本,意思就是已经编译了好了,下载来直接用就好,Spark也有源码可以下载,但是得自己去手动编译之后才能使用。下载完成后将文件进行解压(可能需要解压两次),最好解压到一个盘的根目录下,并重命名为Spark,简单不易出错。并且需要注意的是,在Spark的文件目录路径名中,不要出现空格,类似于“Program Files”这样的文件夹名是不被允许的。按照JDK中介绍的环境变量添加方法,将Spark文件夹下的bin文件夹的路径添加如环境变量,这样就可以在任何位置启动cmd,进入spark了。
完成如上操作后,打开cmd,输入spark-shell,即可启动spark+scala环境,如果输入pyspark就是启动spark+python环境。
spark-shell:


pyspark:

完成!
Hadoop安装
进入https://archive.apache.org/dist/hadoop/common/,选择所需Hadoop版本进行下载,如,我们需要的是Hadoop2.7或更新的版本。

下载并解压到指定目录,然后到环境变量部分设置HADOOP_HOME为Hadoop的解压目录,然后再设置该目录下的bin目录到系统变量的PATH下。
注意,有些朋友的hadoop文件夹中的bin文件夹中没有一个名为“winutils.exe”的文件,这时候,运行spark就可能会存在问题,去 https://github.com/steveloughran/winutils 选择你安装的Hadoop版本号,然后进入到bin目录下,找到winutils.exe文件,下载方法是点击winutils.exe文件,进入之后在页面的右上方部分有一个Download按钮,点击下载即可。下载好winutils.exe后,将这个文件放入到Hadoop的bin目录下,比如你的路径是C:\\hadoop\bin。在打开的cmd中输入C:\hadoop\bin\winutils.exe chmod 777 /tmp/hive。这个操作是用来修改权限的。注意前面的C:\hadoop\bin部分要对应的替换成实际你所安装的bin目录所在位置。
完成!
以上就是在Windows系统下搭建自己的大数据学习环境的流程。
PART2——MacOS系统下的配置
一、brew安装
Windows通常不算是一个比较方便的大数据相关技术学习的系统,相比较而言,OS系统或Linux比较方便,且这两个系统内核均为unix,故其相似之处有很多。
在OS系统上,有一个很方便的工具叫做brew,我们可以使用这个工具快捷的安装很多软件。
在mac中启动terminal,然后输入
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
稍等一段时间,brew就安装完成了。
二、Python3和Jupyter Notebook安装
OS系统自带python2,同时,我们利用brew可以轻松的安装python3。
启动terminal,输入brew install python3
稍等片刻,python3就完成安装了。然后在终端输入
python3 -m pip install jupyter(或python -m pip install jupyter)
这是因为mac上有python2和python3,防止系统无法识别你是想用python2的pip还是python3的pip,所以这样输入。
为了让你的Jupyter Notebook可以同时使用python2和python3,我们还要在多输入一些内容。
启动terminal,输入python -m pip install ipykernel(当你使用
python -m pip install jupyter时用这个命令)或者
python3 -m pip install ipykernel(当你使用
python3 -m pip install jupyter时用这个命令)
大功告成!
二、Mysql安装
启动terminal,输入brew install mysql,等待一段时间。
然后配置自启动:启动终端,分别输入如下命令:
$ mkdir -p ~/Library/LaunchAgents
$ ln -sfv /usr/local/opt/mysql/*.plist ~/Library/LaunchAgents
$ find /usr/local/Cellar/mysql/ -name "homebrew.mxcl.mysql.plist" -exec cp {} ~/Library/LaunchAgents/ \;
$ launchctl load -w ~/Library/LaunchAgents/homebrew.mxcl.mysql.plist
接下来修改mysql密码:
先启动mysql服务:在终端输入mysql.server start
继续执行mysql_secure_installation
会有如下输入内容,按照如下操作进行设置:
cometdeMacBook-Pro:~ comet$ mysql_secure_installationSecuring the MySQL server deployment. Connecting to MySQL using a blank password. VALIDATE PASSWORD PLUGIN can be used to test passwords and improve security. It checks the strength of password and allows the users to set only those passwords which aresecure enough. Would you like to setup VALIDATE PASSWORD plugin? Press y|Y for Yes, any other key for No: N // 这个选yes的话密码长度就必须要设置为8位以上,但我只想要6位的 Please set the password for root here.New password: // 设置密码 Re-enter new password: // 再一次确认密码By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only fortesting, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? (Press y|Y for Yes, any other key for No) : Y // 移除不用密码的那个账户 Success. Normally, root should only be allowed to connect from'localhost'. This ensures that someone cannot guess atthe root password from the network.Disallow root login remotely? (Press y|Y for Yes, any other key for No) : n ... skipping.By default, MySQL comes with a database named 'test' that anyone can access. This is also intended only for testing,and should be removed before moving into a production environment. Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y - Dropping test database... Success. - Removing privileges on test database... Success. Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y Success. All done!
接下来,创建my.cnf配置文件:
在终端中输入如下命令:
$ cd /etc
$ sudo vim my.cnf
在vim中粘贴如下内容:
# Example MySQL config file for medium systems.
# This is for a system with little memory (32M - 64M) where MySQL plays
# an important part, or systems up to 128M where MySQL is used together with
# other programs (such as a web server)
#
# MySQL programs look for option files in a set of
# locations which depend on the deployment platform.
# You can copy this option file to one of those
# locations. For information about these locations, see:
# http://dev.mysql.com/doc/mysql/en/option-files.html
#
# In this file, you can use all long options that a program supports.
# If you want to know which options a program supports, run the program
# with the "--help" option.
# The following options will be passed to all MySQL clients
[client]
default-character-set=utf8
#password = your_password
port = 3306
socket = /tmp/mysql.sock
# Here follows entries for some specific programs
# The MySQL server
[mysqld]
character-set-server=utf8
init_connect='SET NAMES utf8
port = 3306
socket = /tmp/mysql.sock
skip-external-locking
key_buffer_size = 16M
max_allowed_packet = 1M
table_open_cache = 64
sort_buffer_size = 512K
net_buffer_length = 8K
read_buffer_size = 256K
read_rnd_buffer_size = 512K
myisam_sort_buffer_size = 8M
character-set-server=utf8
secure_file_priv=''
init_connect='SET NAMES utf8'
# Don't listen on a TCP/IP port at all. This can be a security enhancement,
# if all processes that need to connect to mysqld run on the same host.
# All interaction with mysqld must be made via Unix sockets or named pipes.
# Note that using this option without enabling named pipes on Windows
# (via the "enable-named-pipe" option) will render mysqld useless!
#
#skip-networking
# Replication Master Server (default)
# binary logging is required for replication
log-bin=mysql-bin
# binary logging format - mixed recommended
binlog_format=mixed
# required unique id between 1 and 2^32 - 1
# defaults to 1 if master-host is not set
# but will not function as a master if omitted
server-id = 1
# Replication Slave (comment out master section to use this)
#
# To configure this host as a replication slave, you can choose between
# two methods :
#
# 1) Use the CHANGE MASTER TO command (fully described in our manual) -
# the syntax is:
#
# CHANGE MASTER TO MASTER_HOST=<host>, MASTER_PORT=<port>,
# MASTER_USER=<user>, MASTER_PASSWORD=<password> ;
#
# where you replace <host>, <user>, <password> by quoted strings and
# <port> by the master's port number (3306 by default).
#
# Example:
#
# CHANGE MASTER TO MASTER_HOST='125.564.12.1', MASTER_PORT=3306,
# MASTER_USER='joe', MASTER_PASSWORD='secret';
#
# OR
#
# 2) Set the variables below. However, in case you choose this method, then
# start replication for the first time (even unsuccessfully, for example
# if you mistyped the password in master-password and the slave fails to
# connect), the slave will create a master.info file, and any later
# change in this file to the variables' values below will be ignored and
# overridden by the content of the master.info file, unless you shutdown
# the slave server, delete master.info and restart the slaver server.
# For that reason, you may want to leave the lines below untouched
# (commented) and instead use CHANGE MASTER TO (see above)
#
# required unique id between 2 and 2^32 - 1
# (and different from the master)
# defaults to 2 if master-host is set
# but will not function as a slave if omitted
#server-id = 2
#
# The replication master for this slave - required
#master-host = <hostname>
#
# The username the slave will use for authentication when connecting
# to the master - required
#master-user = <username>
#
# The password the slave will authenticate with when connecting to
# the master - required
#master-password = <password>
#
# The port the master is listening on.
# optional - defaults to 3306
#master-port = <port>
#
# binary logging - not required for slaves, but recommended
#log-bin=mysql-bin
# Uncomment the following if you are using InnoDB tables
#innodb_data_home_dir = /usr/local/mysql/data
#innodb_data_file_path = ibdata1:10M:autoextend
#innodb_log_group_home_dir = /usr/local/mysql/data
# You can set .._buffer_pool_size up to 50 - 80 %
# of RAM but beware of setting memory usage too high
#innodb_buffer_pool_size = 16M
#innodb_additional_mem_pool_size = 2M
# Set .._log_file_size to 25 % of buffer pool size
#innodb_log_file_size = 5M
#innodb_log_buffer_size = 8M
#innodb_flush_log_at_trx_commit = 1
#innodb_lock_wait_timeout = 50
[mysqldump]
quick
max_allowed_packet = 16M
[mysql]
no-auto-rehash
# Remove the next comment character if you are not familiar with SQL
#safe-updates
default-character-set=utf8
[myisamchk]
key_buffer_size = 20M
sort_buffer_size = 20M
read_buffer = 2M
write_buffer = 2M
[mysqlhotcopy]
interactive-timeout
完成!在终端中输入mysql -u root -p,然后输入密码,如果没有设置密码,直接按回车键,即可启动mysql。

三、Hadoop与Spark安装
1.Hadoop安装
SSH免密登录
首先,需要先设置一下SSH免密登录,这样使用hadoop会方便的多。
先在系统偏好设置的“共享”中将远程登录模式修改为如下:(勾选远程登录)

1、安装ssh
直接 sudo apt-get install openssh-server
2、查看ssh运行状态
ps -e | grep ssh
如果发现 sshd 和 ssh-agent 即表明 ssh服务基本运行正常
3、生成公钥和私钥
ssh-keygen -t rsa -P ""
4、将公钥追加到文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
5、测试ssh localhost
如果发现不用输入密码就可以登录那么 ssh无密码机制就算建立成功了。
安装JDK
启动terminal,输入brew cask install java,稍等一会儿,JDK就安装完成了,在terminal中输入java -version,如果显示了jdk版本,就说明安装成功。

安装Hadoop
启动终端,输入brew install hadoop(看到brew的强大了吧!),等待一段时间,hadoop就会安装完毕,路径通常位于/usr/local/Cellar/hadoop下。不过我们还需要进行一些配置才能完成伪分布式的hadoop。
配置Hadoop
首先,将hadoop的路径添加进环境变量:
启动终端,输入sudo vim .bash_profile
然后输入:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_91.jdk/Contents/Home
export JRE_HOME=$JAVA_HOME/jre
export HADOOP_HOME=/usr/local/Cellar/hadoop/2.7.3
export HADOOP_HOME_WARN_SUPPRESS=1
export CLASS_HOME=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:${PATH}
当然,这几行命令中文件夹名称,或者说路径,要按照你实际安装路径修改一下。使用wq保存这些内容,然后在终端中输入source .bash_profile使它生效。
接下来要对hadoop中的几个文件进行修改:
修改/usr/local/Cellar/hadoop/2.7.3/libexec/etc/hadoop/hadoop-env.sh 文件
进入到 /usr/local/Cellar/hadoop/2.7.3/libexec/etc/hadoop (就是Hadoop的安装目录下)
vim hadoop-env.sh
需要修改的地方:
# The java implementation to use.
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_91.jdk/Contents/Home"
# Extra Java runtime options. Empty by default.
#export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
export HADOOP_OPTS="-Djava.security.krb5.realm=OX.AC.UK -Djava.security.krb5.kdc=kdc0.ox.ac.uk:kdc1.ox.ac.uk"
# The maximum amount of heap to use, in MB. Default is 1000.
export HADOOP_HEAPSIZE=2000
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
然后修改/usr/local/Cellar/hadoop/2.7.3/libexec/etc/hadoop/core-site.xml 文件
修改成如下内容
修改/usr/local/Cellar/hadoop/2.7.3/libexec/etc/hadoop/hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/Library/hadoop-2.7.3/tmp/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/Library/hadoop-2.7.3/tmp/hdfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
修改/usr/local/Cellar/hadoop/2.7.3/libexec/etc/hadoop/mapred-site.xml. 文件
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9010</value>
</property>
</configuration>
修改/usr/local/Cellar/hadoop/2.7.3/libexec/etc/hadoop/yarn-site.xml 文件
<configuration>
<!-- Site specific YARN configuration properties -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</configuration>
配置完成。终端运行:hadoop namenode -format
这样就完成了初始化。
在终端输入start-all.sh
打开浏览器,输入localhost:50070,出现如下界面:
输入localhost:8088
输入localhost:8042
好了,Hadoop安装完成!你可以使用stop-all.sh停止hadoop服务。
2.Spark安装
首先,使用brew install scala进行scala的安装。稍等片刻就会完成。
输入sudo vim ~/.zshrc进行环境变量的配置:(注意修改为你自己的路径)
export SCALA_HOME=/usr/local/Cellar/scala/2.12.2
export PATH=$PATH:$SCALA_HOME/bin
然后,依然去到spark官网(见前文),下载你需要的spark版本,然后直接安装即可。下载完直接双击压缩包就可以解压,将其重命名为spark放到/usr/local/Cellar/下。同样配置一下环境变量。终端输入sudo vim ~/.zshrc添加:
export SPARK_HOME=/usr/local/Cellar/spark
export PATH=$PATH:$SPARK_HOME/bin
完成,在终端输入spark-shell即可启动spark。
编辑:柯南




