
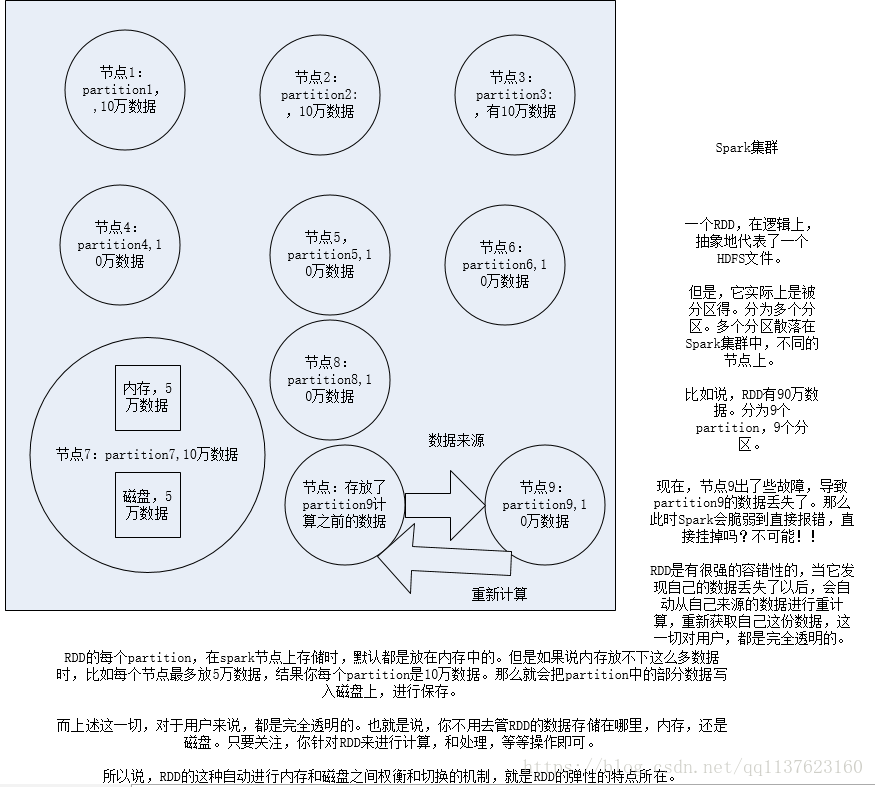
RDD以及其特点
1、RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集。
2、RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)
3、RDD通常通过Hadoop上的文件,即HDFS文件或者Hive表,来进行创建;有时也可以通过应用程序中的集合来创建。
4、RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。
5、RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性)
RDD以及其特性
什么是Spark开发?
1、核心开发:离线批处理 / 延迟性的交互式数据处理
2、SQL查询:底层都是RDD和计算操作
3、实时计算:底层都是RDD和计算操作
Spark核心编程原理
开发wordcount程序
1、用Java开发wordcount程序
1.1 配置maven环境
1.2 如何进行本地测试
1.3 如何使用spark-submit提交到spark集群进行执行(spark-submit常用参数说明,spark-submit其实就类似于hadoop的hadoop jar命令)
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.spark</groupId> <artifactId>spark-study-java</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>spark-study-java</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.10</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.10</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.4.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.3.0</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/java</sourceDirectory> <testSourceDirectory>src/main/test</testSourceDirectory> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass></mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.2.1</version> <executions> <execution> <goals> <goal>exec</goal> </goals> </execution> </executions> <configuration> <executable>java</executable> <includeProjectDependencies>true</includeProjectDependencies> <includePluginDependencies>false</includePluginDependencies> <classpathScope>compile</classpathScope> <mainClass>cn.spark.study.App</mainClass> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.6</source> <target>1.6</target> </configuration> </plugin> </plugins> </build></project>
代码
package cn.spark.study.core;import java.util.Arrays;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.FlatMapFunction;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.api.java.function.VoidFunction;import scala.Tuple2;/**
* 使用java开发本地测试的wordcount程序
* @author Administrator
*
*/public class WordCountLocal {
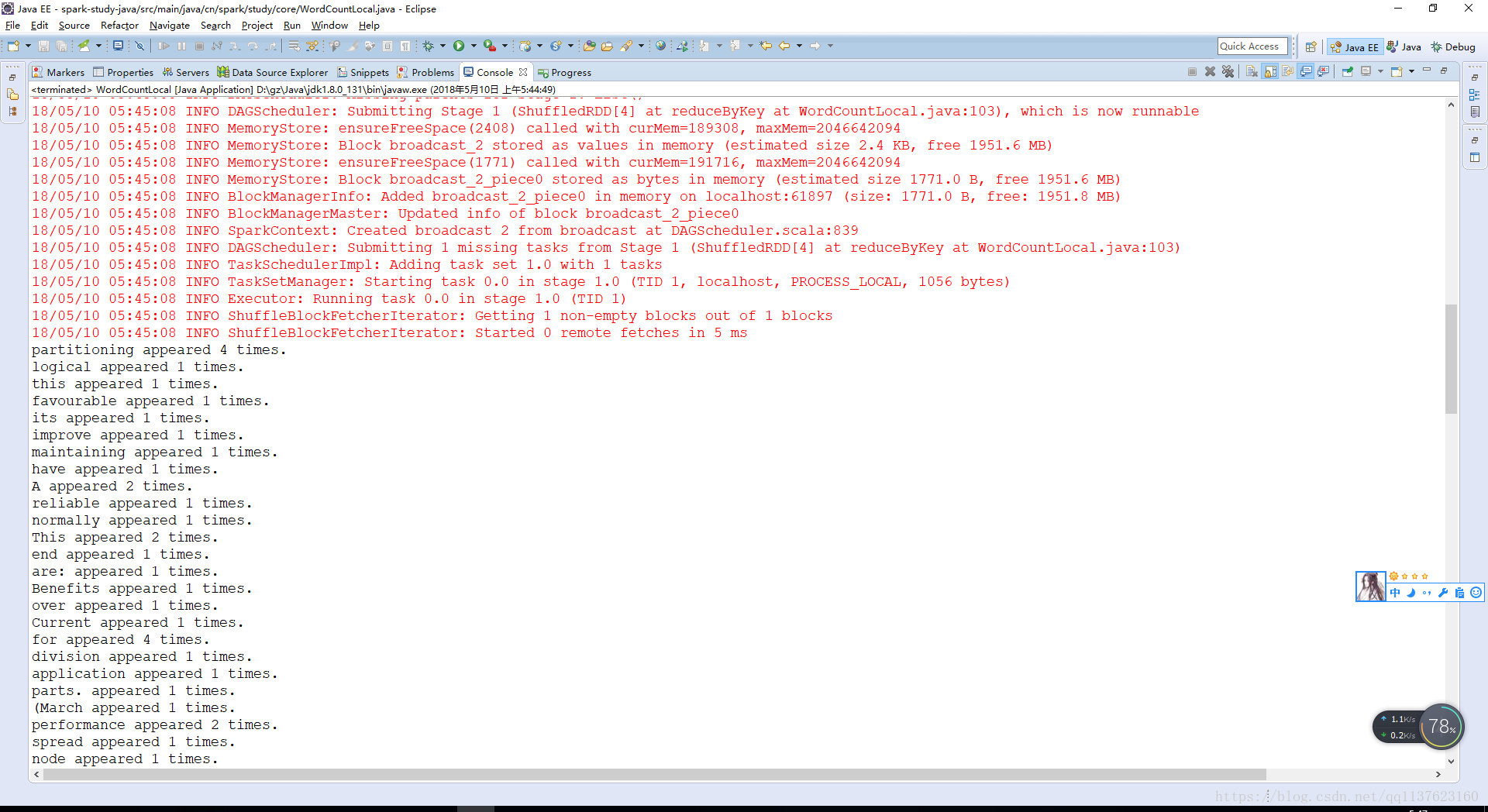
public static void main(String[] args) { // 编写Spark应用程序
// 本地执行,是可以执行在eclipse中的main方法中,执行的
// 第一步:创建SparkConf对象,设置Spark应用的配置信息
// 使用setMaster()可以设置Spark应用程序要连接的Spark集群的master节点的url
// 但是如果设置为local则代表,在本地运行
SparkConf conf = new SparkConf()
.setAppName("WordCountLocal")
.setMaster("local");
// 第二步:创建JavaSparkContext对象
// 在Spark中,SparkContext是Spark所有功能的一个入口,你无论是用java、scala,甚至是python编写
// 都必须要有一个SparkContext,它的主要作用,包括初始化Spark应用程序所需的一些核心组件,包括
// 调度器(DAGSchedule、TaskScheduler),还会去到Spark Master节点上进行注册,等等
// 一句话,SparkContext,是Spark应用中,可以说是最最重要的一个对象
// 但是呢,在Spark中,编写不同类型的Spark应用程序,使用的SparkContext是不同的,如果使用scala,
// 使用的就是原生的SparkContext对象
// 但是如果使用Java,那么就是JavaSparkContext对象
// 如果是开发Spark SQL程序,那么就是SQLContext、HiveContext
// 如果是开发Spark Streaming程序,那么就是它独有的SparkContext
// 以此类推
JavaSparkContext sc = new JavaSparkContext(conf); // 第三步:要针对输入源(hdfs文件、本地文件,等等),创建一个初始的RDD
// 输入源中的数据会打散,分配到RDD的每个partition中,从而形成一个初始的分布式的数据集
// 我们这里呢,因为是本地测试,所以呢,就是针对本地文件
// SparkContext中,用于根据文件类型的输入源创建RDD的方法,叫做textFile()方法
// 在Java中,创建的普通RDD,都叫做JavaRDD
// 在这里呢,RDD中,有元素这种概念,如果是hdfs或者本地文件呢,创建的RDD,每一个元素就相当于
// 是文件里的一行
JavaRDD<String> lines = sc.textFile("D://1.txt"); // 第四步:对初始RDD进行transformation操作,也就是一些计算操作
// 通常操作会通过创建function,并配合RDD的map、flatMap等算子来执行
// function,通常,如果比较简单,则创建指定Function的匿名内部类
// 但是如果function比较复杂,则会单独创建一个类,作为实现这个function接口的类
// 先将每一行拆分成单个的单词
// FlatMapFunction,有两个泛型参数,分别代表了输入和输出类型
// 我们这里呢,输入肯定是String,因为是一行一行的文本,输出,其实也是String,因为是每一行的文本
// 这里先简要介绍flatMap算子的作用,其实就是,将RDD的一个元素,给拆分成一个或多个元素
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" "));
}
}); // 接着,需要将每一个单词,映射为(单词, 1)的这种格式
// 因为只有这样,后面才能根据单词作为key,来进行每个单词的出现次数的累加
// mapToPair,其实就是将每个元素,映射为一个(v1,v2)这样的Tuple2类型的元素
// 如果大家还记得scala里面讲的tuple,那么没错,这里的tuple2就是scala类型,包含了两个值
// mapToPair这个算子,要求的是与PairFunction配合使用,第一个泛型参数代表了输入类型
// 第二个和第三个泛型参数,代表的输出的Tuple2的第一个值和第二个值的类型
// JavaPairRDD的两个泛型参数,分别代表了tuple元素的第一个值和第二个值的类型
JavaPairRDD<String, Integer> pairs = words.mapToPair( new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word, 1);
}
}); // 接着,需要以单词作为key,统计每个单词出现的次数
// 这里要使用reduceByKey这个算子,对每个key对应的value,都进行reduce操作
// 比如JavaPairRDD中有几个元素,分别为(hello, 1) (hello, 1) (hello, 1) (world, 1)
// reduce操作,相当于是把第一个值和第二个值进行计算,然后再将结果与第三个值进行计算
// 比如这里的hello,那么就相当于是,首先是1 + 1 = 2,然后再将2 + 1 = 3
// 最后返回的JavaPairRDD中的元素,也是tuple,但是第一个值就是每个key,第二个值就是key的value
// reduce之后的结果,相当于就是每个单词出现的次数
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey( new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2;
}
}); // 到这里为止,我们通过几个Spark算子操作,已经统计出了单词的次数
// 但是,之前我们使用的flatMap、mapToPair、reduceByKey这种操作,都叫做transformation操作
// 一个Spark应用中,光是有transformation操作,是不行的,是不会执行的,必须要有一种叫做action
// 接着,最后,可以使用一种叫做action操作的,比如说,foreach,来触发程序的执行
wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
}
});
sc.close();
}
}
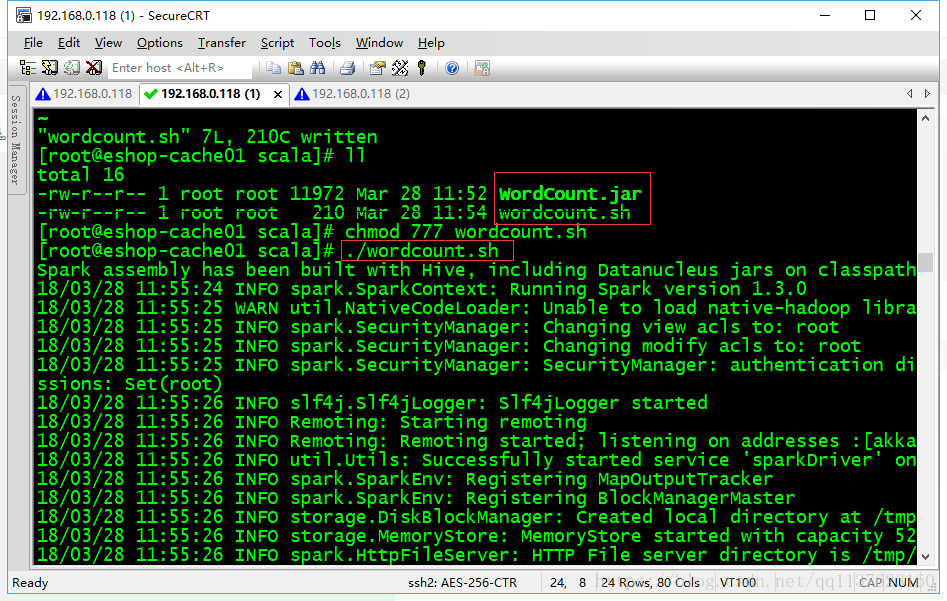
集群上运行、操作步骤和Scala差不多、可参考下面
2、用Scala开发wordcount程序
2.1 下载scala ide for eclipse
2.2 在Java Build Path中,添加spark依赖包(如果与scala ide for eclipse原生的scala版本发生冲突,则移除原生的scala / 重新配置scala compiler)
2.3 用export导出scala spark工程
pom.xml同上
代码
package cn.spark.study.core;import java.util.Arrays;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.FlatMapFunction;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.api.java.function.VoidFunction;import scala.Tuple2;/**
* 将java开发的wordcount程序部署到spark集群上运行
* @author Administrator
*
*/public class WordCountCluster {
public static void main(String[] args) { // 如果要在spark集群上运行,需要修改的,只有两个地方
// 第一,将SparkConf的setMaster()方法给删掉,默认它自己会去连接
// 第二,我们针对的不是本地文件了,修改为hadoop hdfs上的真正的存储大数据的文件
// 实际执行步骤:
// 1、将spark.txt文件上传到hdfs上去
// 2、使用我们最早在pom.xml里配置的maven插件,对spark工程进行打包
// 3、将打包后的spark工程jar包,上传到机器上执行
// 4、编写spark-submit脚本
// 5、执行spark-submit脚本,提交spark应用到集群执行
SparkConf conf = new SparkConf()
.setAppName("WordCountCluster");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://eshop-cache01:9000/spark.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String, Integer> pairs = words.mapToPair( new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey( new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2;
}
});
wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
}
});
sc.close();
}
}wordcount.sh
/usr/local/spark/bin/spark-submit \--class cn.spark.study.core.WordCount \--num-executors 3 \--driver-memory 100m \--executor-memory 100m \--executor-cores 3 \/usr/local/spark-study/scala/WordCount.jar \
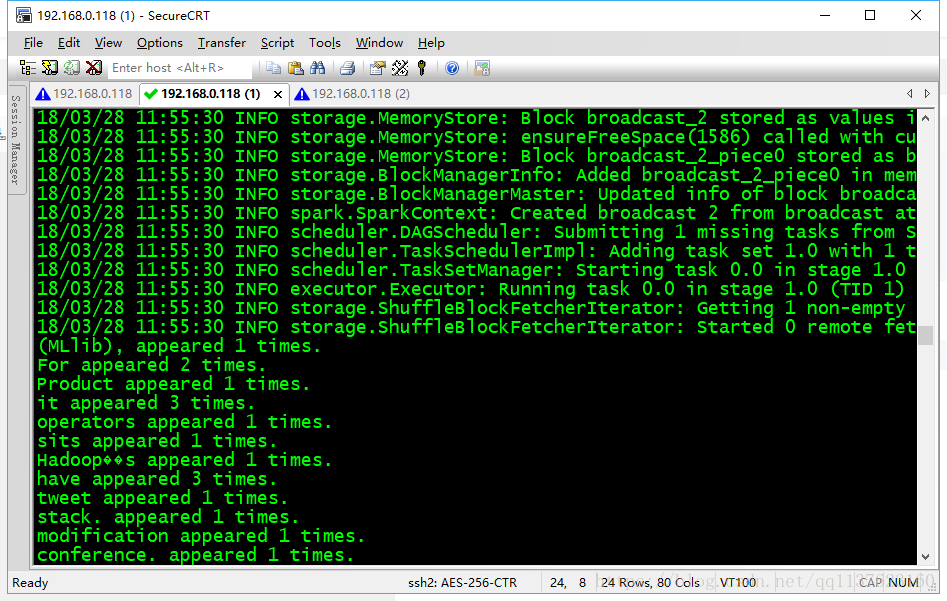
3、用spark-shell开发wordcount程序
3.1 常用于简单的测试 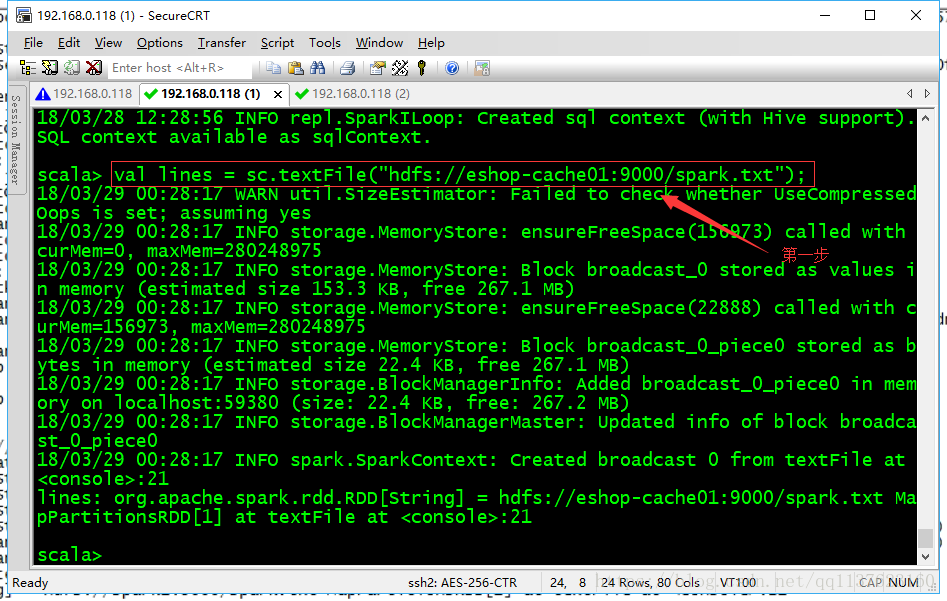
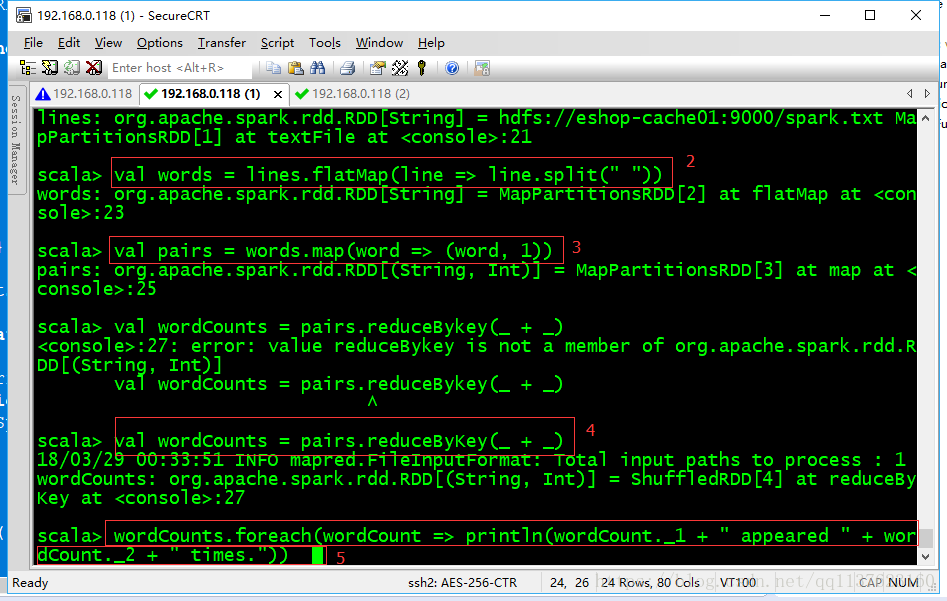
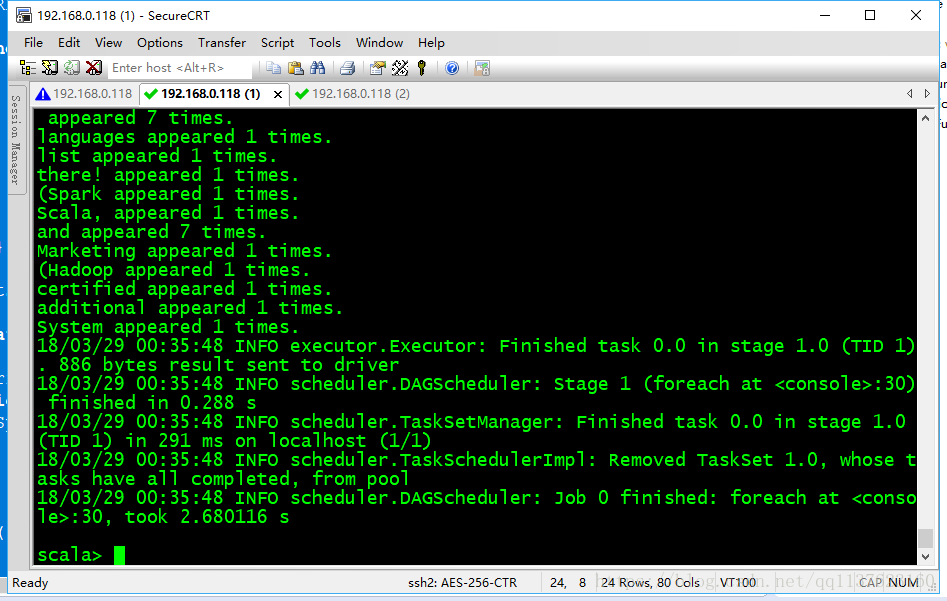
wordcount程序原理深度剖析
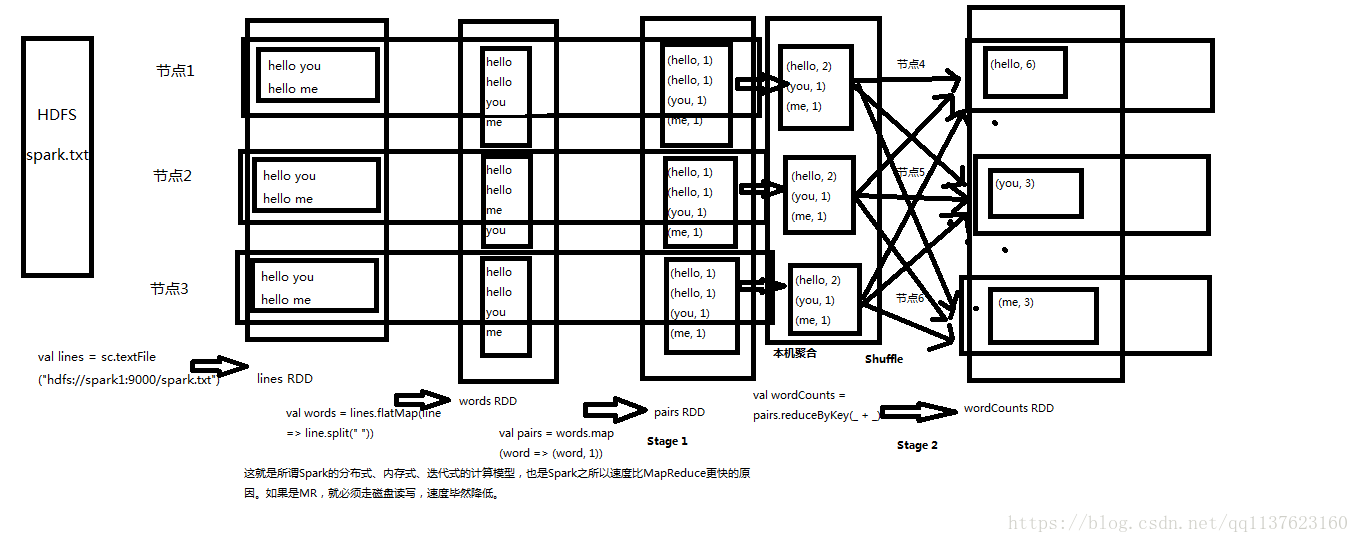
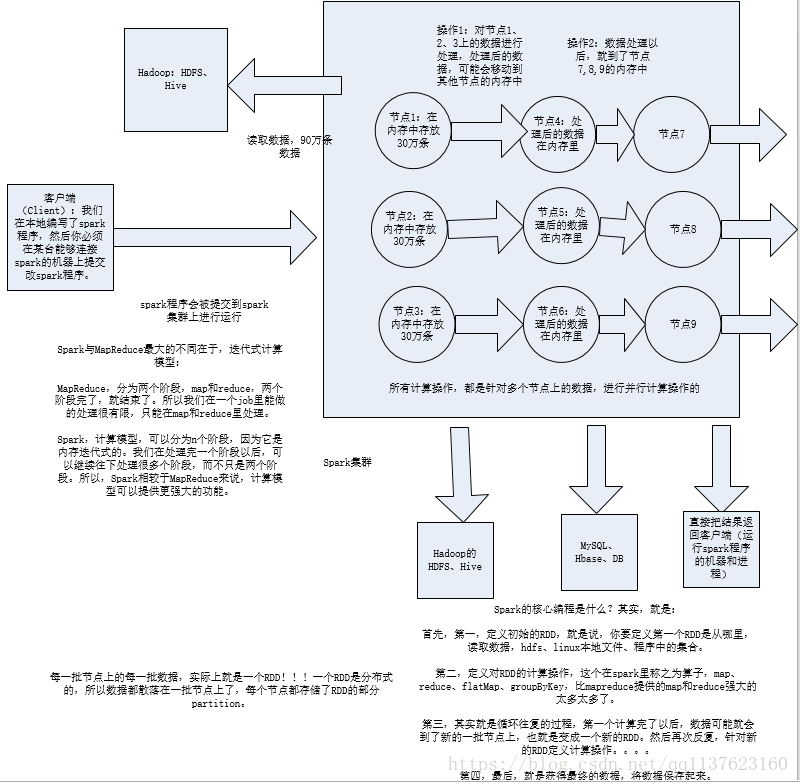
Spark架构原理
对于上面的wordcount程序在Spark各个组件的执行流程一个简单的图、详细流程后面会有 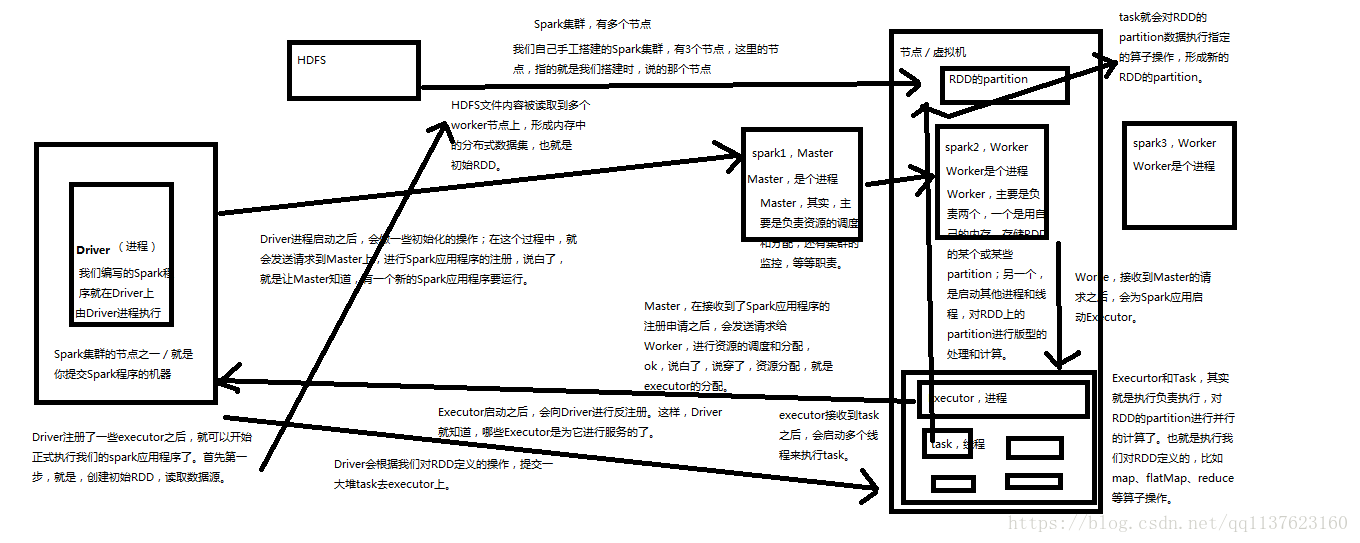






热门评论
-

Lily_Dak2019-01-16 0
查看全部评论请问你这个手记看的哪个课程写的?