
SQL优化是我们经常会遇到的问题,无论你是专职的数据分析人员还是全栈开发大神或者是CURD搬运工。
我们在工作中经常会听到这样的声音:“查询慢?加个索引吧”。虽然加索引并不一定能解决问题,但是这体现了SQL优化的思想。
而数据库主要由三部分组成,分别是解析器、优化器和执行引擎。
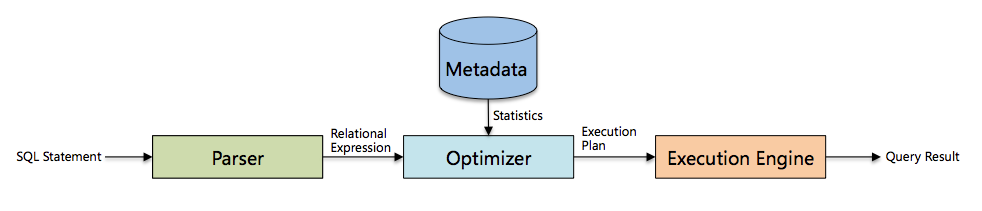
其执行逻辑是我们输入的SQL语句通过解析器解析成关系表达式,通过优化器把关系表达式转换成执行计划,最终通过执行引擎进行执行。所以优化器在很大程度上决定了一个系统的性能。优化器的作用就好比找到两点之间的最短路径。
上篇文章我们提到了Calcite,Calcite本身就支持两种优化方式分别是RBO和CBO。
RBO
RBO(Rule-Based Optimizer) 基于规则的优化器。是根据已经制定好的一些优化规则对关系表达式进行转换,最终生成一个最优的执行计划。它是一种经验式的优化方法,优化规则都是预先定义好的,只需要将SQL按照优化规则的顺序往上套就行,一旦满足某个规则则进行优化。
这样的结果就是同样一条SQL,无论读取的表中的数据是怎样的,最后生成的执行计划都是一样的(优化规则都一样)。而且SQL的写法不同也很有可能影响最终的执行计划,从而影响SQL的性能(基于优化规则顺序执行)。
所以说,虽然RBO是一个老司机,知道常见的套路,但是当路况不同时,无法针对性的达到最佳的效果。
CBO
CBO(Cost-Based Optimizer)基于代价的优化器。根据优化规则对关系表达式进行转换,生成多个执行计划,最后根据统计信息和代价模型计算每个执行计划的Cost。从中挑选Cost最小的执行计划作为最终的执行计划。
从描述来看,CBO是优于RBO的,RBO只认规则,对数据不敏感,而在实际的过程中,数据的量级会严重影响同样SQL的性能。所以仅仅通过RBO生成的执行计划很有可能不是最优的。而CBO依赖于统计信息和代价模型,统计信息的准确与否、代价模型是否合理都会影响CBO选择最优计划。
目前各大数据库和大数据计算引擎都已经在使用CBO了,比如Oracle、Hive、Spark、Flink等等。
动态CBO
顾名思义,就是在执行计划生成的过程中动态优化的方式。随着大数据技术的飞速发展,静态的CBO已经无法满足我们SQL优化的需要了,静态的统计信息无法提供准确的参考,在执行计划的生成过程中动态统计才会得到最优的执行计划。
那么优化器的执行过程是怎样的呢?又有哪些优化规则呢?(请看下回分解~)
参考资料:





