
乾明 郭一璞 发自 凹非寺
量子位 报道
糟糕。
一张照片被挖了一个“洞”。

不好不好,这可是限量版24k纯金足球纪念勋章挂坠的唯一存世照片,要是没了,就只能飞8个航班越过54座山丘穿越25000公里拿出我逆光也清晰的R213重新拍一张了……
还是请出AI修图匠,试试能不能把我的纯金勋章还给我。
第一位修图师傅,PartialConv,来自家里有GPU的大厂英伟达,据说能把破了相的妹子的脸修复好,还顺带做个医美,去皱隆鼻玻尿酸。
试试效果:

我天庭饱满的圆形勋章,怎么成了这个鬼样子?这是做旧了呀?
第二位修图师傅,GatedConv,来自伊利诺伊大学和Adobe,曾经把岩洞修成爱你的形状。
看看出品:

这、这还不如前面的做旧师傅呢,连个圆都画不出来。
我只是要把我的勋章补圆,怎么这么难?
只能指望第三位修图师傅了,名字有点长,Foreground-aware Image Inpainting,前景感知图像修复,“前”老师。
病急乱投医,请前老师开个方子:

咦?好像不错的样子?
我的勋章还是又亮又圆,还标记出了勋章的轮廓,圆周曲率,合规合矩,不圆不要钱。
这位“前”老师,是新年伊始刚刚发在Arxiv上的最新算法,论文就叫《Foreground-aware Image Inpainting》,研究者们来自罗彻斯特大学、伊利诺伊大学香槟分校和Adobe研究院,其中一作是罗彻斯特大学计算机系学生,完成这项研究时正在Adobe实习。
各项表现优于其他研究
所以,前面那些老牌修图匠,是怎么被PK掉的?
从这张数据对比表可以看出来,前景感知图像修复,在各类结果数据中都是最优秀的,超过了PatchMatch、Global&Local、ContextAttention、PartialConv、GatedConv五大对手。
数据冷冰冰,我们让群众的眼睛来判断一下,哪个修图匠做的最好。
研究团队找了50张照片,随机打洞破坏后,用前面提到的五大AI修图匠和前景感知图像修复算法来修复后,让吃瓜群众们挑选修复的最好的那张。
总共获得1099张选票,877票都投给了前景感知图像修复算法,得票率将近80%。
吃瓜群众们看到的效果图长这样:

这是一个整张照片随机打孔的示例。
在这个示例里,海边的小男孩上半个头都不见了,右腿的一部分也消失了,前面3个AI都填补的相当生硬,PS痕迹明显。
后面的三个AI都不会处理裤腿,左边宽松右边窄,仿佛小男孩穿了一件打折残次品。
而头顶的部分,前景感知图像修复算法是唯一一个把头顶修复清晰的,虽然小男孩看起来年纪轻轻,发际线不低,但整张图片都是完整清晰的。

这个示例则只在背景部分打孔,前景不受影响。
可以看出,前三个AI还是非常生硬,将图片上的颜色随意涂抹一通。
后三个里,第四个和第五个在处理小男孩衣领的时候出现了问题,好像毛衣脱了线。
唯有前景感知图像修复算法完美的修复了这张照片,几乎和原图一模一样,看不出什么明显的问题。
怎么实现的?
整体来说,完成这项神奇的修复技术,只需要3步。
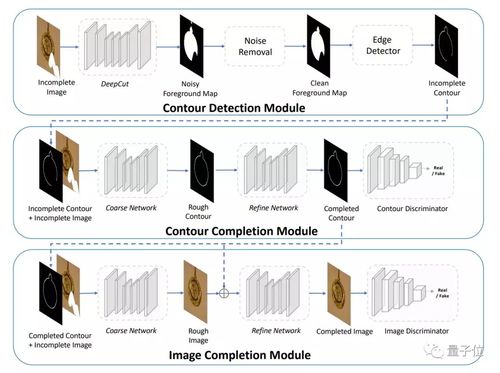
首先,检测损坏图像的前景轮廓。
然后轮廓补全模块登场,来预测完整的图像前景轮廓应该是什么样子。
最后,将补全的轮廓连同损坏的图像一同输入图像补全模块,作为修复图像损坏部分的指导,来生成最后的图像。
在整个模型中,最为核心的,是轮廓补全模块。正是这一部分,赋予了整个研究的“生命力”。下面的这个图片,显示了有轮廓补全模块(左三)与没有轮廓补全模块(左二)之间的对比。

左一为带洞的输入图像,右一为原始图像。
没有轮廓补全模块的修复图像,脑门、头发、水果浑然一体,并没有很好地区分开。轮廓补全模块的修复图像,虽然仍旧不太完美,但效果要好得多。
这个轮廓补全模块,具体是怎么回事呢?
没有现成的数据集
之前训练图像修复算法用的数据集,一般都没有什么标签。但是到“前景感知图像修复”里就不行了。
因为这个算法有个补全前景轮廓的环节,所以,就需要一个标注了轮廓的数据集。
所以,他们从各种公共数据集中收集了15762张自然图像,每张都包含一两个显著对象,有动物、植物、人物、面部、建筑物、街道等等。
每张图,都用蒙版标注出了显著对象,也就是前景,还用边缘检测算法获取了轮廓。
现实世界中,大家想要修复的图像,缺失的部分很少是“规规矩矩”的。所以在这项研究中,是随机给数据集中的图像“挖洞”。主要有两种:
一种是随意在图像中挖洞,洞可能出现在前景对象上,主要用来处理不需要的对象出现在前景图像中或者遮挡显著对象的情况。
一种是不能出现在前景对象上的洞,主要是为了模拟不需要的区域,或者分散注意力的对象位于显著对象后面的情况。
数据集搞定之后,就轮到前边提到的3步算法出场了。
检测前景轮廓
数据集做好之后,在正式训练轮廓补全模块之前,会先对显著对象进行轮廓检测。在这一环节中,没有输入图像的轮廓蒙版,而是使用了DeepCut来自动检测图像中的显著对象。
DeepCut使用深度神经网络,提取并组合图像中的高级和低级特征,来预测具有非常精确边界的前景蒙版。
但因为输入图像被挖了洞,所以生成的分隔图中会有一些噪声。有时候,洞都被当做了前景。
解决这个问题的办法是使用二值的图像缺失部分蒙版,去除分割图中可能被误认为显著对象的区域。然后,应用连通分量分析进一步去除图中的一些小聚类以获得前景蒙版。
然后采用Sobel算子从分割图中检测物体的不完整轮廓。
下一步,就是——
预测完整轮廓
轮廓补全模块的架构,与现有的图像修复技术的架构类似,是一个基于GAN的模型,由生成器和PatchGAN判别器组成。生成器包括两个网络,一个是粗略网络,一个是精细网络。
其中,粗略网络是一个具有若干卷积和扩张卷积层的编码器-解码器网络。精细网络的架构与其大致相似,只是增加了语境注意力层,从图像全局来推断缺失值。
首先,将不完整的图像、不完整的轮廓和图像缺失部分蒙版输入到粗略网络中,得到一个粗略轮廓图,也就是对图像缺失轮廓的粗略估计。
然后,将粗糙的轮廓输入到精细网络中,来输出更清晰,更精确的轮廓。
更精确的轮廓出来之后,就交由PatchGAN判别器进行对抗训练,它会输出一个得分图,而不是单个得分,来更明确的反映生成的轮廓不同局部区域的真实性。
但在这个过程中,轮廓的稀疏程度不一,数据是不平衡的,因此会带来各种各样的问题,比如无法确定每个像素的权重等等从,从而导致各种损失函数失效。
为了避免在训练过程中数据不平衡问题带来的各种问题,研究团队采用了课程学习(Curriculum learning)的方法, 来逐步训练模型。
第一阶段,轮廓补全模块仅需要输出粗略轮廓,仅训练具有内容损失的模型。
第二阶段,使用对抗性损失来微调预训练网络,但与内容损失相比,权重非常小,即0.01:1,以避免训练失败。
第三阶段,将对抗性损失的权重和内容损失的权重比例调为为1:1来微调整个轮廓补全模块。
最后一步,修复图像
然后,就是图像补全模块上场了。
图像补全模块先在大型Places2数据集上进行预训练。然后,在轮廓补全模块输出的指导下进行微调。
在训练过程中,有两种方法。一种是固定轮廓补全模块的参数,并仅微调图像补全模块。第二种是联合微调两个模块,这次研究采用了效果更好的第二种方法。
除了生成器和判别器不同之外,图像补全模块的结构和轮廓补全模块基本相同。输入不完整的图像、完整的轮廓、和图像缺失部分的蒙版,输出完整的图像。
同样,模块的生成器中也有一个粗略网络和一个精细网络。先生成粗略图像,再生成更准确的结果。
接下来,精细网络生成的图像与图像缺失部分的蒙版连接,并交由图像判别器以进行对抗性学习。再经过训练,来生成最终的图像。
更多内容可以阅读论文~

传送门:
https://arxiv.org/pdf/1901.05945.pdf
作者系网易新闻·网易号“各有态度”签约作者








热门评论
-

慧子於2019-01-24 0
查看全部评论很厉害,打算实际操作看看,哈哈哈哈