
堆是一种特殊类型的二叉树,具有以下两个性质:
每个节点的值大于等于(或小于等于)其每个子节点的值
堆属于完全二叉树
就像这样:
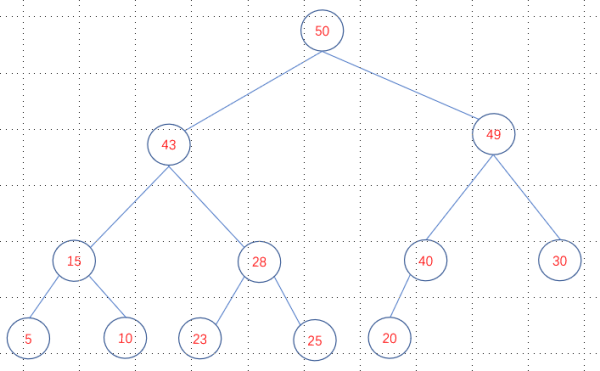
上图是大顶堆,如果每个节点小于等于其每个子节点的值,那它就是小顶堆。
有趣的是,堆可以通过数组来实现。例如,数组 data = [50 43 49 15 28 40 30 5 10 23 15 20] 可以表示上面的堆。数组中元素的排放顺序表示节点按照从顶到底、每一层从左到右的顺序放置。堆之所以可以放到数组中,是因为它是一颗完全二叉树。可以根据任意节点的下标,通过公式计算出子节点的下标。假设节点P的下标为i,那么节点P的左子节点下标为2i + 1,右子节点下标为2i + 2,相关证明过程可以看这里数据结构与算法-二叉树性质。我们这里就以数组来实现堆结构,探讨相关的创建、插入、删除、运用的逻辑。
创建
堆的创建有两种方式。第一种是自上向下从一个空数组中创建堆,第二种是自下向上将已有的数组调整为堆。首先探讨自上向下的逻辑。
1、自上向下
从一个空数组开始,每一个新节点都放到当前堆的末尾,如果发现插入节点之后破坏了堆的特性,那么将新节点与其父节点进行交换,直至重新调整为堆。假如现在有一段数据流:
49 50 43 15 28 40 5 25 10 23 30 20 55
自上向下的过程:

核心逻辑在于每次插入新节点之后,如果破坏了堆的结构,只要和父节点进行交换,直至调整为堆即可。该算法的时间复杂度有O(nlgn),不是很理想,数据量比较大时不适合这种方案。
2、自下向上
一颗完整的二叉树可以分解成根节点,左子树,右子树。对于左右子树又可以分解成更多的子树。如果我们将树中的每个节点都看做一颗树,只要每棵树符合堆的特性,那么整棵树也是符合堆的特性的。基于以上思想,前人提出了一种自下向上的创建堆地方式。树中最小的子树其实是叶子节点,由于叶子节点没有子树,可以认为是符合堆的特性的。所以,我们就从最后一个非叶子节点开始,按照从下向上,从右到左的顺序,调整每个子树符合堆的特性,直到根节点,那么整棵树就成了堆。
假设一共有n的元素,最后一个非叶子节点的下标是多少呢?答案是n/2 -1。证明如下:
假设堆中度为0、度为1、度为2的节点分别有n0、n1、n2个,那么n = n0 + n1 + n2,又知道n0 = n2 +1,证明方式在数据结构与算法-二叉树性质。那么n = 2*n2 + n1 +1。
n1如果为0
那么最后一个非叶子节点的下标为n2 - 1,即(n - n1 - 1)/2 - 1= n/2 - 3/2,由于n = 2*n2 + 1是奇数,所以n/2 - 1向下取整等于n/2 - 3/2。
n1如果为1
那么最后一个非叶子节点的下标为n2,即(n - n1 -1)/2 = n/2 - 1。
对于完全二叉树来讲,n1要么为0要么为1。因此,综上所述,最后一个非叶子节点的下标为n/2 - 1。
既然找到了最后一个非叶子节点P,那就从P节点开始自下向上,自右向左的调整每一个遇到的子树为堆,最终整棵树成为堆。
假设现在存在数组data = [39 50 43 15 28 40 5 25 10 23 30 20 55],展开之后是这样的:
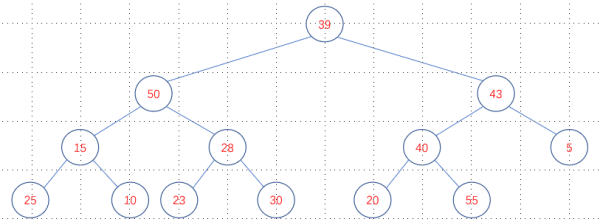
按照自下向上的算法调整是这样的:
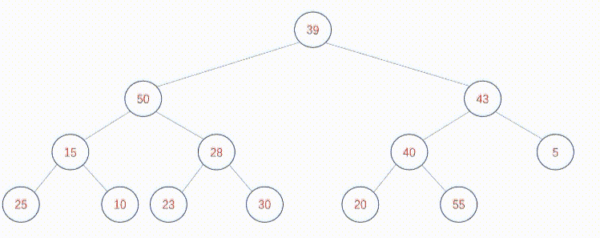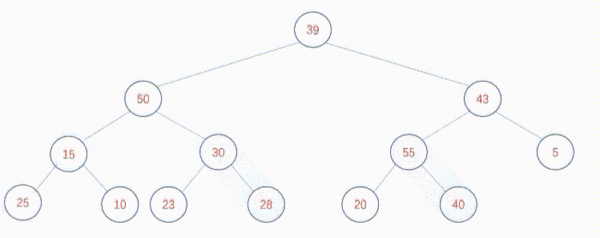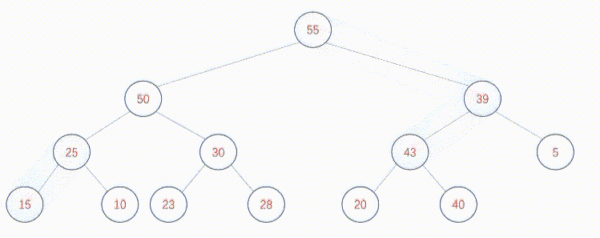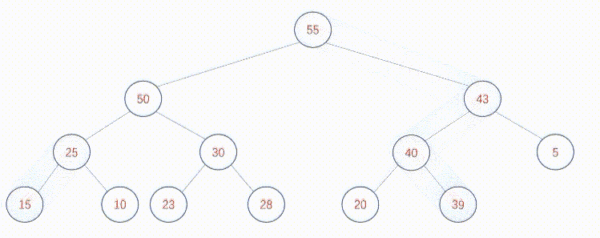
该算法的时间复杂度是O(n),通常情况下优于自上向下创建堆的方式。
添加
在堆中插入一个新的元素,通常会放入到数组的末尾,如果插入到头部或者中间某个位置,有两个缺陷。第一,会移动数组里大量数据,第二,严重破坏堆结构,只能依靠自下向上的方式调整所有子树,才能保持整棵树的堆结构,得不偿失。
如果将新元素插入到数组末尾,仅仅有可能破坏少量子树的堆结构,也能在短时间内调整完毕。假如有以下堆结构:
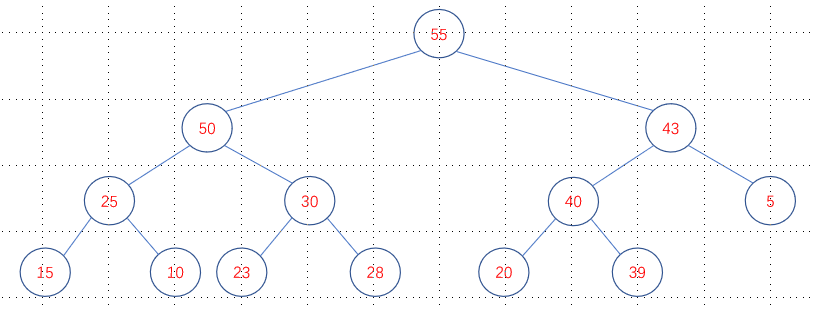
在末尾插入60节点,调整方式如下:
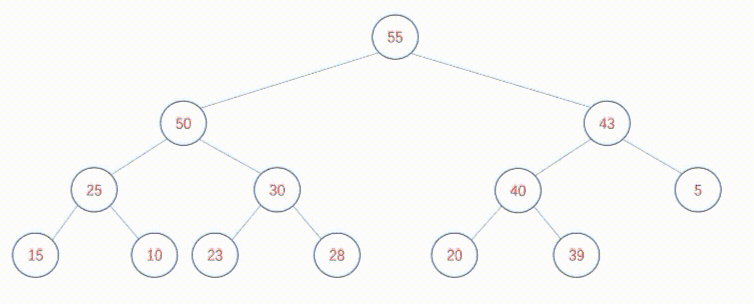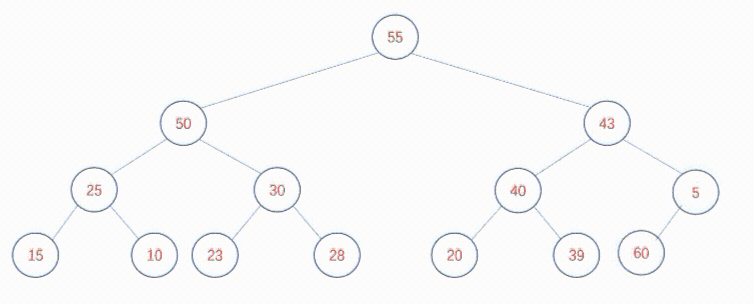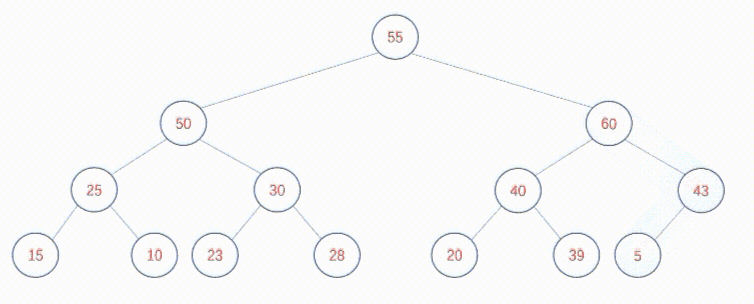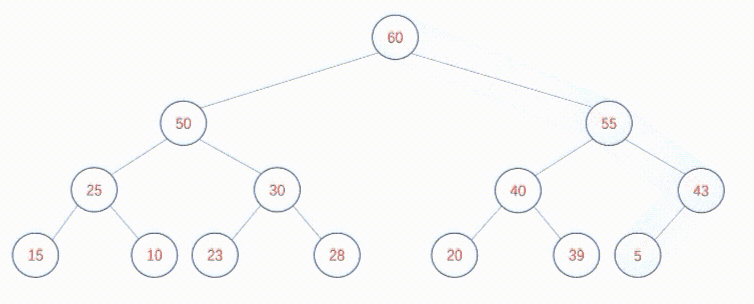 可以发现,无论是自上向下创建堆还是自下向上调整堆,又或者在堆中插入新的元素,核心逻辑总是调整堆的过程。关键在于,二叉树中每个节点总是有两个身份,既是某颗子树(P子树)的根节点,也是其父节点所在树(Q子树)的子节点。调整堆的过程其实就是既要保证P子树是堆,也要保证Q子树是堆。
可以发现,无论是自上向下创建堆还是自下向上调整堆,又或者在堆中插入新的元素,核心逻辑总是调整堆的过程。关键在于,二叉树中每个节点总是有两个身份,既是某颗子树(P子树)的根节点,也是其父节点所在树(Q子树)的子节点。调整堆的过程其实就是既要保证P子树是堆,也要保证Q子树是堆。
删除
在堆中删除某个元素,通常我们会删除堆的根节点,因为它是有价值的,要么是最大值要么是最小值。为了避免删除头结点之后数组元素大量移动,前人想出一个巧妙的方式。那就是将最后一个叶子节点和根结点进行交换。最后一个叶子节点成了根节点,根节点成了最后一个叶子节点。这时,我们删除元素不必移动数组数据,但是破坏了堆结构,怎么办呢?老样子,调整堆,调整方式和上面介绍的方法一致,就不多说了。
我们当然可以删除数组中任一元素,方法和删除根节点是一致的。但是,我们往往不会这么做,因为在堆中除了根节点,其他元素没有特别的地方,价值不大。
运用
我们已经了解堆的创建、添加、删除,那它有什么用处呢?
答案是优先队列。对于堆来说,新元素总是插入到数组末尾,被删除元素总是根节点,并且要么是最大的要么是最小的,这不就是优先队列吗?在数据结构与算法-栈与队列中,我们推荐使用链表来实现队列,这对于普通的队列是可以的,因为普通队列保持的是数据插入时的次序。但是对于优先队列就不合适了,数据插入到优先队列之后,需要依靠优先级排序,从队列弹出的数据总是优先级最大(最小)的元素。如果使用链表来实现优先队列,操作复杂度是O(n),但是如果使用数组,将数据按照堆结构排列,那么操作复杂度仅仅有O(lgn),这是非常吸引人的。并且,标准库中的优先队列就是以向量实现的。
堆的另外一个运用是对数据进行排序,称之为堆排序。
算法逻辑很简单,就是不停的删除根节点、调整堆的过程。那么,数据就会以从大到小或者从小到大的顺序从堆中删除。堆排序的操作复杂度有O(nlgn),算不上很优秀,但至少比冒泡、插入这些算法要好用。
堆的内容到这里已经探讨完毕,更多内容就需要在实践中摸索了。





