

前言:毕设项目还要求加了这个做大数据搜索,正好自己也比较感兴趣,就一起来学习学习吧!
Elasticsearch 简介
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
查询
保持好奇心。从数据中探寻各种问题的答案。
通过 Elasticsearch,您能够执行及合并多种类型的搜索(结构化数据、非结构化数据、地理位置、指标),搜索方式随心而变。先从一个简单的问题出发,试试看能够从中发现些什么。
分析
大处着眼,全局在握。
找到与查询最匹配的十个文档是一回事。但如果面对的是十亿行日志,又该如何解读呢?Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。
速度

可扩展性

弹性

灵活性

操作的乐趣

客户端库
使用您自己的编程语言与 Elasticsearch 进行交互
Elasticsearch 使用的是标准的 RESTful 风格的 API 和 JSON。此外,我们还构建和维护了很多其他语言的客户端,例如 Java、Python、.NET、SQL 和 PHP。与此同时,我们的社区也贡献了很多客户端。这些客户端使用起来简单自然,而且就像 Elasticsearch 一样,不会对您的使用方式进行限制。
Java:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder( new HttpHost("localhost", 9200, "http")));
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.aggregation(AggregationBuilders.terms("top_10_states").field("state").size(10));
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("social-*");
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);尽享强大功能

HADOOP 和 SPRAK

照例来说应该是去扒官网,结果一搜就惊了,这官网也忒得劲儿了吧,竟然提供中文版本而且还有中文版本的文档,友好友好,我看了好长一会儿才反应过来自己还有博客要写.咳咳,上面的内容都是摘自官网顺便附一个官网链接:https://www.elastic.co/cn/products/elasticsearch
另外还有一个关于 Elasticsearch 来源很有趣的故事在这里分享一下:
回忆时光
许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。
直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。
后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。
第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 Github 上最活跃的项目之一,他拥有超过300名 contributors(目前736名 contributors )。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…
安装 Elasticsearch
官网最新版本 Elasticsearch (6.5.4),但是由于自己的环境使用最新版本的有问题(配合下面的工具 Kibana 有问题..Kibana 启动不了),所以不得不换成更低版本的 6.2.2,下载外链:戳这里,当然你也可以试一下最新的版本:
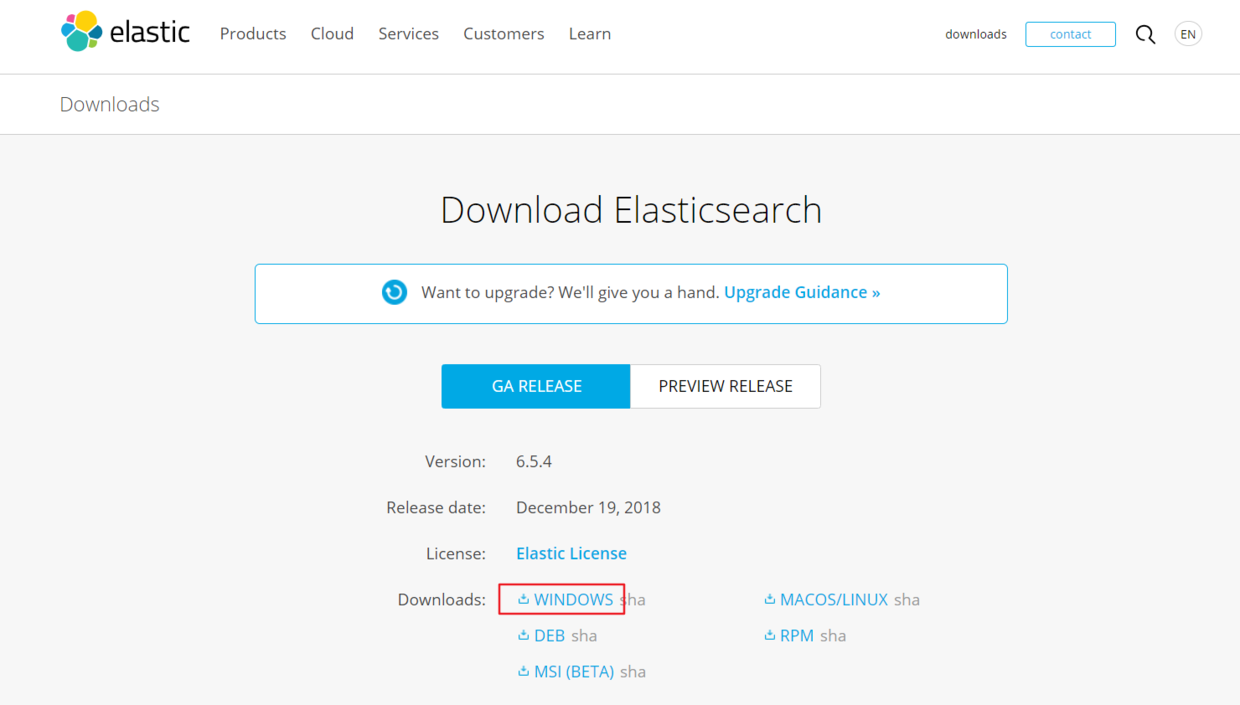
顺带一提:在下载之前你应该确保你的 Java 版本保持在 1.8 及以上(就 1.8 吧..),这是 Elasticsearch 的硬性要求,可以自行打开命令行输入
java -version来查看 Java 的版本
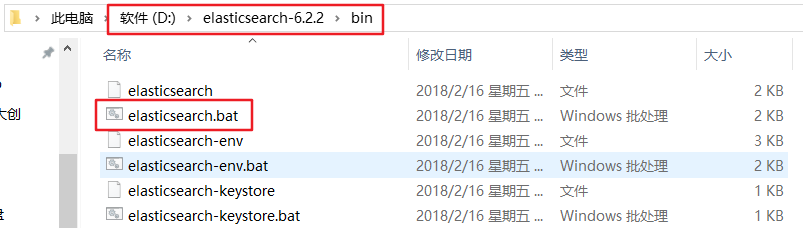
下载完成后,可以看到是一个压缩包,我们直接解压在 D 盘上,然后打开 bin 目录下的 elasticsearch.bat 文件
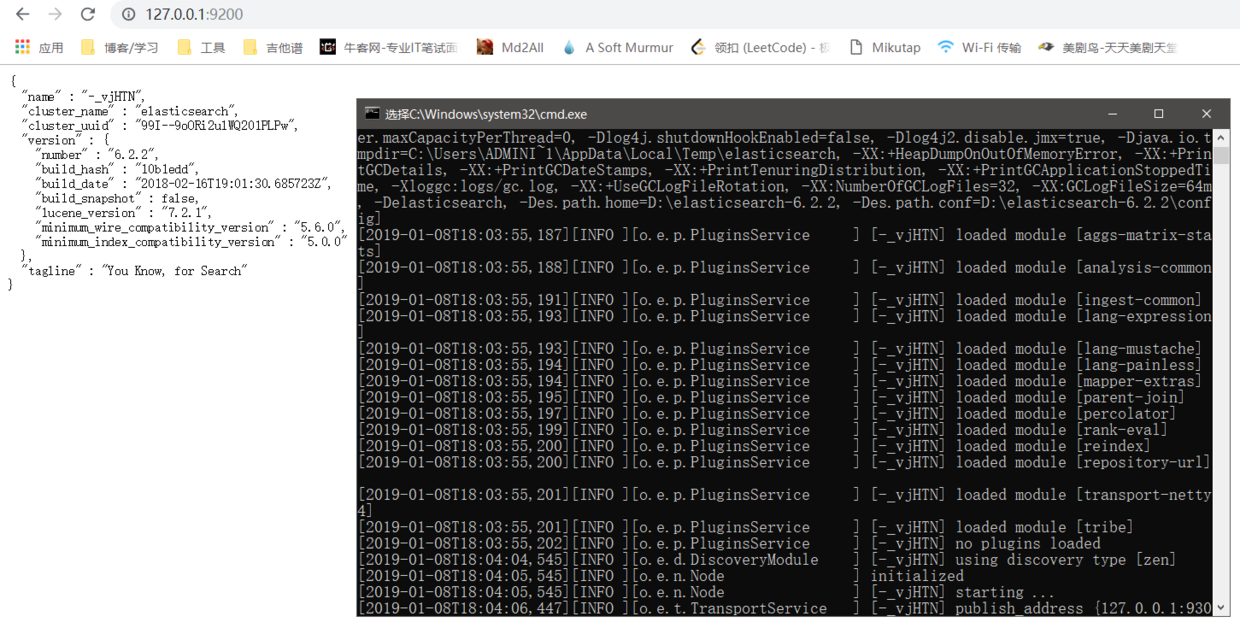
等待一段时间后,可以看到小黑框输出一行 start ,就说明我们的 Elasticsearch 已经跑起来了,我们访问地址:http://127.0.0.1:9200/,看到返回一串 JSON 格式的代码就说明已经成功了:
安装 Kibana
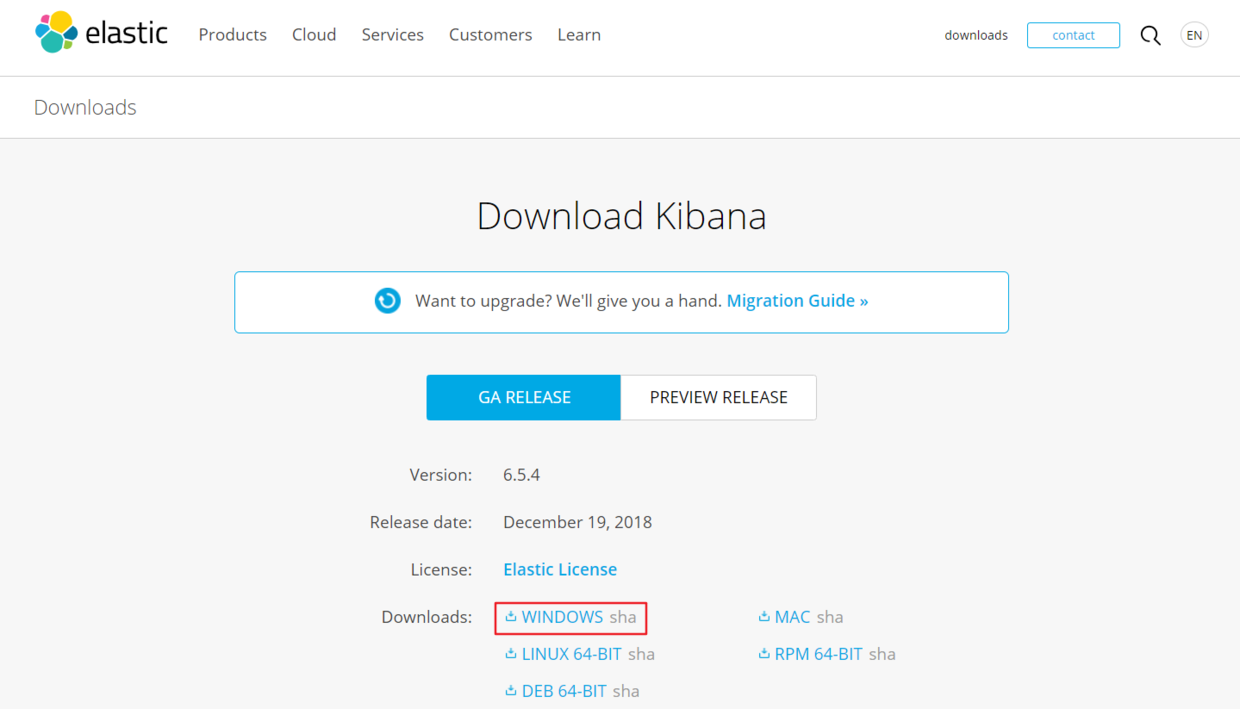
这是一个官方推出的把 Elasticsearch 数据可视化的工具,官网在这里:【传送门】,不过我们现在暂时还用不到那些数据分析的东西,不过里面有一个 Dev Tools 的工具可以方便的和 Elasticsearch 服务进行交互,去官网下载了最新版本的 Kibana(6.5.4) 结果不知道为什么总是启动不起来,所以换一了一个低版本的(6.2.2)正常,给个下载外链:下载点这里,你们也可以去官网试试能不能把最新的跑起来:
解压到 D 盘(意外的有点慢..),同样打开目录下的bin\kibana.bat:
等待一段时间后就可以看到提示信息,运行在 5601 端口,我们访问地址 http://localhost:5601/app/kibana#/dev_tools/console?_g=() 可以成功进入到 Dev-tools 界面:

点击 【Get to work】,然后在控制台输入 GET /_cat/health?v 查看服务器状态,可以在右侧返回的结果中看到 green 即表示服务器状态目前是健康的:

快速入门
一、基础概念-快速入门
节点 Node、集群 Cluster 和分片 Shards
ElasticSearch 是分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个实例。单个实例称为一个节点(node),一组节点构成一个集群(cluster)。分片是底层的工作单元,文档保存在分片内,分片又被分配到集群内的各个节点里,每个分片仅保存全部数据的一部分。
索引 Index、类型 Type 和文档 Document
对比我们比较熟悉的 MySQL 数据库:
index db
type table
document row
如果我们要访问一个文档元数据应该包括囊括 index/type/id 这三种类型,很好理解。
二、使用 RESTful API 与 Elasticsearch 进行交互
所有其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用你最喜爱的 web 客户端访问 Elasticsearch 。一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
被 < > 标记的部件:
| 部件名 | 作用 |
|---|---|
VERB | 适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE。 |
PROTOCOL | http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
HOST | Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
PATH | API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
QUERY_STRING | 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
BODY | 一个 JSON 格式的请求体 (如果请求需要的话) |
就比如计算集群中文档的数量,我们可以用这个:
curl -XGET 'http://localhost:9200/_count?pretty' -d '{ "query": { "match_all": {}
}
}
'不过对于安装了 Kibana 的我们,可以直接在 Kibana 的控制台输出以下语句,也是同样的效果:
GET /_count?pretty
{ "query": { "match_all": {}
}
}文档管理(CRUD)
如果对于 RESTful 不太熟悉的童鞋请右转:【传送门】
增加:
POST /db/user/1{ "username": "wmyskxz1", "password": "123456", "age": "22"}
POST /db/user/2{ "username": "wmyskxz2", "password": "123456", "age": "22"}这一段代码稍微解释一下,这其实就往索引为 db 类型为 user 的数据库中插入一条 id 为 1 的一条数据,这条数据其实就相当于一个拥有 username/password/age 三个属性的一个实体,就是 JSON 数据
执行命令后,Elasticsearch 返回如下数据:
# POST /db/user/1{ "_index": "db", "_type": "user", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0
}, "_seq_no": 2, "_primary_term": 1}
# POST /db/user/2{ "_index": "db", "_type": "user", "_id": "2", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0
}, "_seq_no": 1, "_primary_term": 1}version 是版本号的意思,当我们执行操作会自动加 1
删除:
DELETE /db/user/1
Elasticsearch 返回数据如下:
{ "_index": "db", "_type": "user", "_id": "1", "_version": 2, "result": "deleted", "_shards": { "total": 2, "successful": 1, "failed": 0
}, "_seq_no": 1, "_primary_term": 1}这里就可以看到 version 变成了 2
修改:
PUT /db/user/2{ "username": "wmyskxz3", "password": "123456", "age": "22"}Elasticsearch 返回数据如下:
{ "_index": "db", "_type": "user", "_id": "2", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0
}, "_seq_no": 2, "_primary_term": 1}查询:
GET /db/user/2
返回数据如下:
{ "_index": "db", "_type": "user", "_id": "2", "_version": 2, "found": true, "_source": { "username": "wmyskxz3", "password": "123456", "age": "22"
}
}搜索
上面我们已经演示了基本的文档 CRUD 功能,然而 Elasticsearch 的核心功能是搜索,所以在学习之前,为更好的演示这个功能,我们先往 Elasticsearch 中插入一些数据:
PUT /movies/movie/1{ "title": "The Godfather", "director": "Francis Ford Coppola", "year": 1972, "genres": [ "Crime", "Drama"
]
}
PUT /movies/movie/2{ "title": "Lawrence of Arabia", "director": "David Lean", "year": 1962, "genres": [ "Adventure", "Biography", "Drama"
]
}
PUT /movies/movie/3{ "title": "To Kill a Mockingbird", "director": "Robert Mulligan", "year": 1962, "genres": [ "Crime", "Drama", "Mystery"
]
}
PUT /movies/movie/4{ "title": "Apocalypse Now", "director": "Francis Ford Coppola", "year": 1979, "genres": [ "Drama", "War"
]
}
PUT /movies/movie/5{ "title": "Kill Bill: Vol. 1", "director": "Quentin Tarantino", "year": 2003, "genres": [ "Action", "Crime", "Thriller"
]
}
PUT /movies/movie/6{ "title": "The Assassination of Jesse James by the Coward Robert Ford", "director": "Andrew Dominik", "year": 2007, "genres": [ "Biography", "Crime", "Drama"
]
}**_search端点**
现在已经把一些电影信息放入了索引,可以通过搜索看看是否可找到它们。 为了使用 ElasticSearch 进行搜索,我们使用 _search 端点,可选择使用索引和类型。也就是说,按照以下模式向URL发出请求:<index>/<type>/_search。其中,index 和 type 都是可选的。
换句话说,为了搜索电影,可以对以下任一URL进行POST请求:
http://localhost:9200/_search - 搜索所有索引和所有类型。
http://localhost:9200/movies/_search - 在电影索引中搜索所有类型
http://localhost:9200/movies/movie/_search - 在电影索引中显式搜索电影类型的文档。
搜索请求正文和ElasticSearch查询DSL
如果只是发送一个请求到上面的URL,我们会得到所有的电影信息。为了创建更有用的搜索请求,还需要向请求正文中提供查询。 请求正文是一个JSON对象,除了其它属性以外,它还要包含一个名称为 “query” 的属性,这就可使用ElasticSearch的查询DSL。
{ "query": {
//Query DSL here
}
}你可能想知道查询DSL是什么。它是ElasticSearch自己基于JSON的域特定语言,可以在其中表达查询和过滤器。你可以把它简单同SQL对应起来,就相当于是条件语句吧。
基本自由文本搜索:
查询DSL具有一长列不同类型的查询可以使用。 对于“普通”自由文本搜索,最有可能想使用一个名称为“查询字符串查询”。
查询字符串查询是一个高级查询,有很多不同的选项,ElasticSearch将解析和转换为更简单的查询树。如果忽略了所有的可选参数,并且只需要给它一个字符串用于搜索,它可以很容易使用。
现在尝试在两部电影的标题中搜索有“kill”这个词的电影信息:
GET /_search
{ "query": { "query_string": { "query": "kill"
}
}
}执行上面的请求并查看结果,如下所示 -
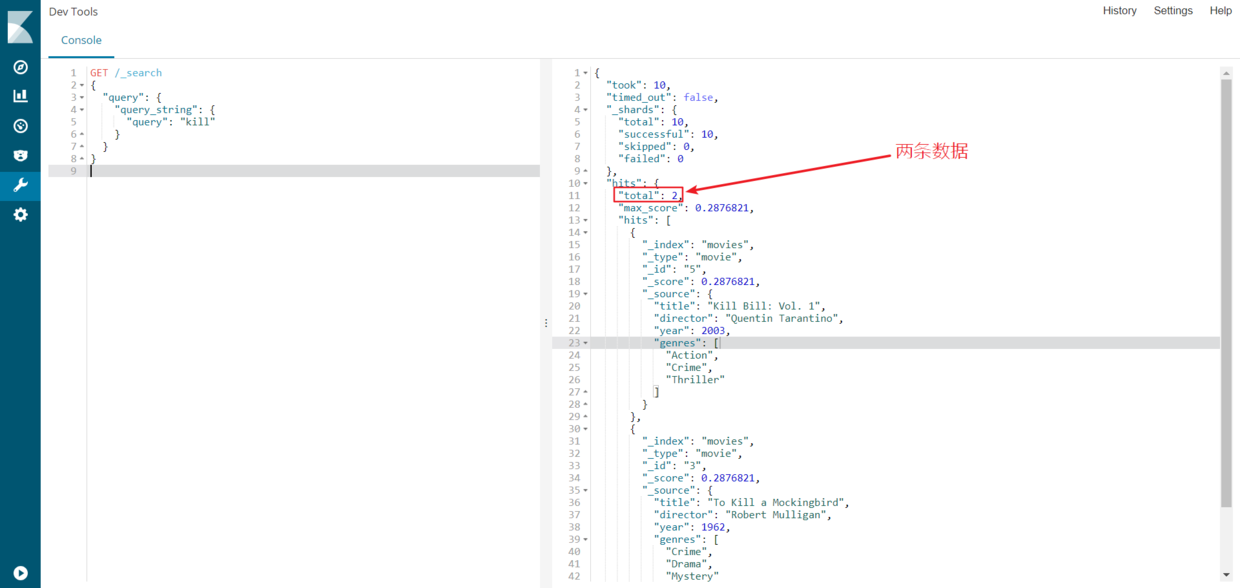
正如预期的,得到两个命中结果,每个电影的标题中都带有“kill”单词。再看看另一种情况,在特定字段中搜索。
指定搜索的字段
在前面的例子中,使用了一个非常简单的查询,一个只有一个属性 “query” 的查询字符串查询。 如前所述,查询字符串查询有一些可以指定设置,如果不使用,它将会使用默认的设置值。
这样的设置称为“fields”,可用于指定要搜索的字段列表。如果不使用“fields”字段,ElasticSearch查询将默认自动生成的名为 “_all” 的特殊字段,来基于所有文档中的各个字段匹配搜索。
为了做到这一点,修改以前的搜索请求正文,以便查询字符串查询有一个 fields 属性用来要搜索的字段数组:
GET /_search
{ "query": { "query_string": { "query": "ford", "fields": [ "title"
]
}
}
}执行上面查询它,看看会有什么结果(应该只匹配到 1 行数据):
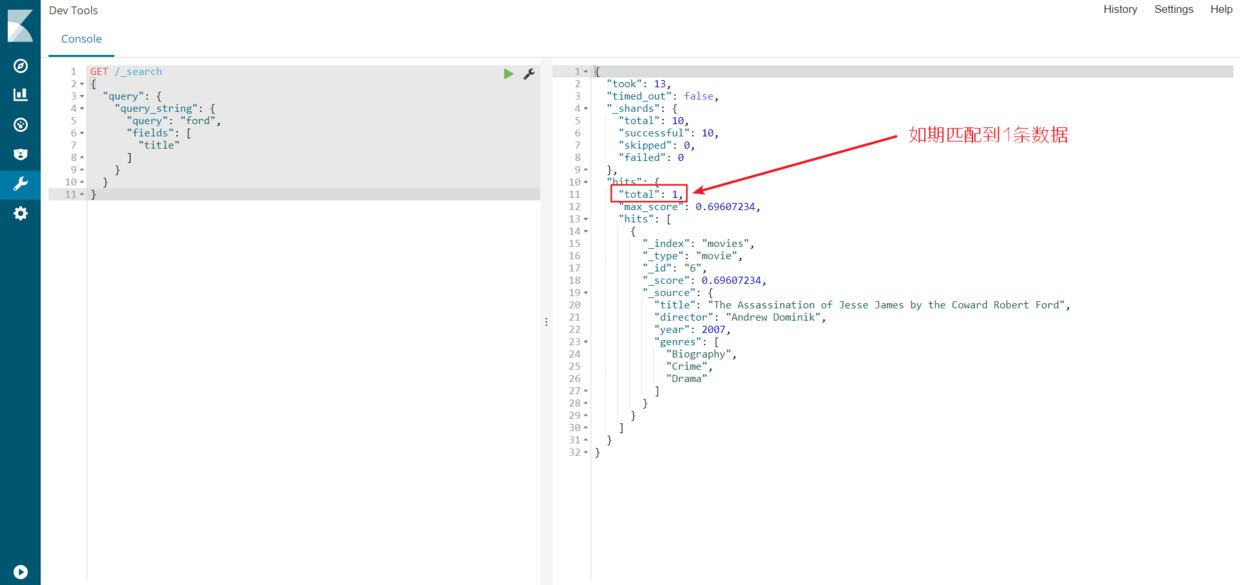
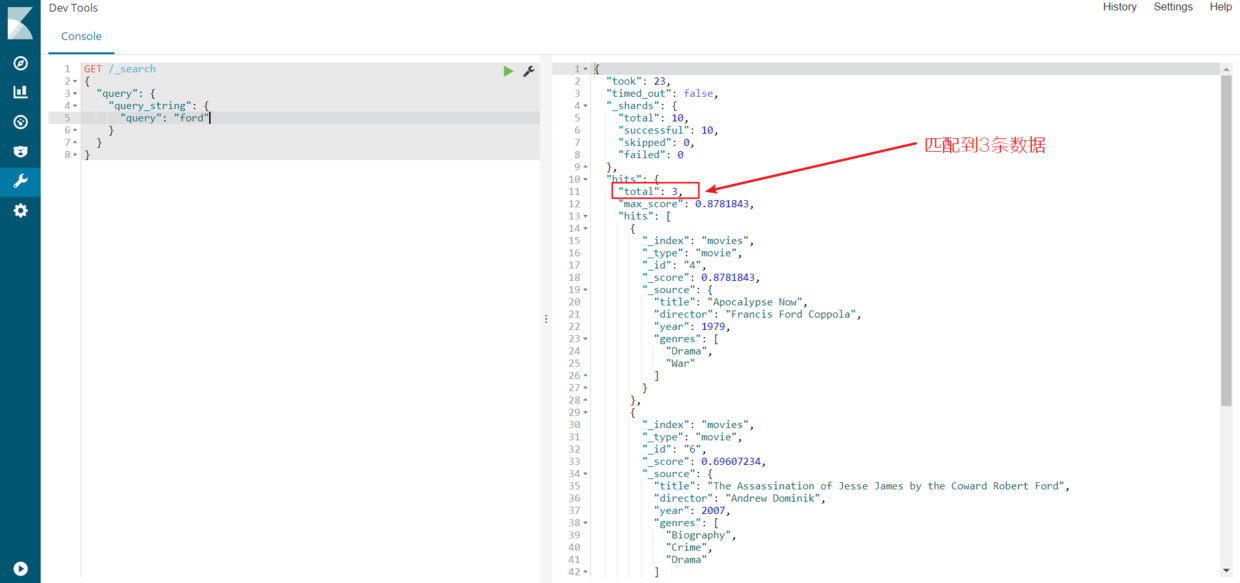
正如预期的得到一个命中,电影的标题中的单词“ford”。现在,从查询中移除fields属性,应该能匹配到 3 行数据:
过滤
前面已经介绍了几个简单的自由文本搜索查询。现在来看看另一个示例,搜索 “drama”,不明确指定字段,如下查询 -
GET /_search
{ "query": { "query_string": { "query": "drama"
}
}
}因为在索引中有五部电影在 _all 字段(从类别字段)中包含单词 “drama”,所以得到了上述查询的 5 个命中。 现在,想象一下,如果我们想限制这些命中为只是 1962 年发布的电影。要做到这点,需要应用一个过滤器,要求 “year” 字段等于 1962。要添加过滤器,修改搜索请求正文,以便当前的顶级查询(查询字符串查询)包含在过滤的查询中:
{ "query": { "filtered": { "query": { "query_string": { "query": "drama"
}
}, "filter": {
//Filter to apply to the query
}
}
}
}过滤的查询是具有两个属性(query和filter)的查询。执行时,它使用过滤器过滤查询的结果。要完成这样的查询还需要添加一个过滤器,要求year字段的值为1962。
ElasticSearch查询DSL有各种各样的过滤器可供选择。对于这个简单的情况,某个字段应该匹配一个特定的值,一个条件过滤器就能很好地完成工作。
"filter": { "term": { "year": 1962 }
}完整的搜索请求如下所示:
GET /_search
{ "query": { "filtered": { "query": { "query_string": { "query": "drama"
}
}, "filter": { "term": { "year": 1962
}
}
}
}
}当执行上面请求,只得到两个命中,这个两个命中的数据的 year 字段的值都是等于 1962。
无需查询即可进行过滤
在上面的示例中,使用过滤器限制查询字符串查询的结果。如果想要做的是应用一个过滤器呢? 也就是说,我们希望所有电影符合一定的标准。
在这种情况下,我们仍然在搜索请求正文中使用 “query” 属性。但是,我们不能只是添加一个过滤器,需要将它包装在某种查询中。
一个解决方案是修改当前的搜索请求,替换查询字符串 query 过滤查询中的 match_all 查询,这是一个查询,只是匹配一切。类似下面这个:
GET /_search
{ "query": { "filtered": { "query": { "match_all": {}
}, "filter": { "term": { "year": 1962
}
}
}
}
}另一个更简单的方法是使用常数分数查询:
GET /_search
{ "query": { "constant_score": { "filter": { "term": { "year": 1962
}
}
}
}
}参考文章:Elasticsearch入门教程、Elasticsearch官方文档、 ElasticSearch 快速上手学习入门教程
三、集成 SpringBoot 简单示例
第一步:新建 SpringBoot 项目
pom包依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId></dependency><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId></dependency><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope></dependency><!-- Elasticsearch支持 --><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
application.properties:
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
第二步:新建实体类
User类:
@Document(indexName = "users", type = "user")public class User { private int id; private String username; private String password; private int age; /** getter and setter */}第三步:Dao 层
UserDao:
import com.wmyskxz.demo.domain.User;import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;public interface UserDao extends ElasticsearchRepository<User, Integer> {
}第四步:Controller 层
这里紧紧是为了演示,所以就省略 service 层,当然 CRUD 不能少:
@RestControllerpublic class UserController { @Autowired
UserDao userDao; @PostMapping("/addUser") public String addUser(String username, String password, Integer age) {
User user = new User();
user.setUsername(username);
user.setPassword(password);
user.setAge(age); return String.valueOf(userDao.save(user).getId());// 返回id做验证
} @DeleteMapping("/deleteUser") public String deleteUser(Integer id) {
userDao.deleteById(id); return "Success!";
} @PutMapping("/updateUser") public String updateUser(Integer id, String username, String password, Integer age) {
User user = new User();
user.setId(id);
user.setUsername(username);
user.setPassword(password);
user.setAge(age); return String.valueOf(userDao.save(user).getId());// 返回id做验证
} @GetMapping("/getUser") public User getUser(Integer id) { return userDao.findById(id).get();
} @GetMapping("/getAllUsers") public Iterable<User> getAllUsers() { return userDao.findAll();
}
}第五步:测试
使用 REST 测试工具测试没有问题,过程我就不给了..bingo!
总结
其实使用 SpringBoot 来操作 Elasticsearch 的话使用方法有点类似 JPA 了,而且完全可以把 Elasticsearch 当做 SQL 服务器来用,也没有问题...在各种地方看到了各个大大特别是官方,都快把 Elasticsearch 这款工具吹上天了,对于它方便的集成这一点我倒是有感受,关于速度这方面还没有很深的感受,慢慢来吧...





