
ChiMerge 是监督的、自底向上的(即基于合并的)数据离散化方法。
它依赖于卡方分析:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
基本思想
对于精确的离散化,相对类频率在一个区间内应当完全一致。
因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。
而低卡方值表明它们具有相似的类分布。
要点
最简单的离散算法: 等宽区间
从最小值到最大值之间,均分为N等份
如此, 若 A, B为min/max, 则每个区间的长度为w=(B-A) / N, 区间边界值为 A+W, A+2W, …. A+(N-1)W类似的一种算法: 等频区间
间隔边界被选择为使得每个间隔包含大约相同数量的训练示例
因此,如果N = 10,每个区间将包含大约10%的例子
以上两种简单算法有弊端
等宽区间划分,划分为5区间,最高工资50000,则所有工资低于10000的人都被划分到同一区间
等频区间可能正好相反,所有工资高于50000的人都会被划分到50000这一区间中。
这两种算法都忽略了实例所属的类型,落在正确区间里的偶然性很大
C4、CART、PVM算法在离散属性时会考虑类信息,但随着算法的运行动态执行,而不是在预处理阶段。
例如,C4算法(ID3决策树系列的一种),将数值属性离散为两个区间,而取这两个区间时,该属性的信息增益是最大的。评价一个离散算法是否有效很难,因为不知道什么是最高效的分类
离散化的主要目的
除了从训练数据中消除数值之外,还要产生一个简洁的数字属性汇总高质量的离散化
区间内均匀性,区间间差异ChiMerge算法用卡方统计量来决定相邻区间的频率明显不同,如果它们足够相似以证明合并它们
ChiMerge算法包括两步,当满足停止条件的时候,区间合并停止
初始化
根据要离散的属性对实例进行排序:每个实例属于一个区间合并区间,又包括两步
(1) 计算每一对相邻区间的卡方值
(2) 将卡方值最小的一对区间合并
预先设定一个卡方的阈值,在阈值之下的区间都合并,阈值之上的区间保持分区间

卡方的计算公式
参数说明
m=2(每次比较的区间数是2个)
k=类的数量
Aij=第i区间第j类的实例的数量
Ri=第i区间的实例数量
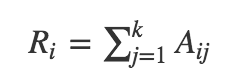
Cj=第j类的实例数量

N=总的实例数量
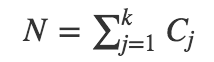
Eij= Aij的期望频率
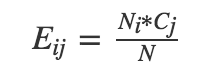
卡方阈值的确定
先选择显著性水平,再由公式得到对应的卡方值。
得到卡方值需要指定自由度,自由度比类别数量小1。例如,有3类,自由度为2,则90%置信度(10%显著性水平)下,卡方的值为4.6。
阈值的意义在于,类和属性独立时,有90%的可能性,计算得到的卡方值会小于4.6,这样,大于阈值的卡方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会进行很多次,离散后的区间数量少、区间大。
用户可以不考虑卡方阈值,此时,用户可以考虑这两个参数:最小区间数,最大区间数。用户指定区间数量的上限和下限,最多几个区间,最少几个区间。ChiMerge算法推荐使用.90、.95、.99置信度,最大区间数取10到15之间以防止
过多的间隔被创建
实战
取鸢尾花数据集作为待离散化的数据集合,使用ChiMerge算法,对四个数值属性分别进行离散化
令停机准则为max_interval=6
下面Python程序

数据集
大致分两步:
整理数据
读入鸢尾花数据集,构造可以在其上使用ChiMerge的数据结构,即, 形如
[
('4.3', [1, 0, 0]),
('4.4', [3, 0, 0]),
...]
的列表,每一个元素是一个元组,元组的第一项是字符串,表示区间左端点,元组的第二项是一个列表,表示在此区间各个类别的实例数目;
离散化
使用ChiMerge方法对具有最小卡方值的相邻区间进行合并,直到满足最大区间数(max_interval)为6
程序最终返回区间的分裂点
# coding=utf-8from time import ctime''' 读取数据'''def read(irisdata):
instances = []
fp = open(irisdata, 'r') for line in fp:
line = line.strip('\n') if line != '':
instances.append(line.split(','))
fp.close() return instances''' 将第i个特征和类标签组合起来
如:
[
[0.2,'Iris-setosa'],
[0.2,'Iris-setosa'],
...
]'''def split(instances, i):
log = [] for line in instances:
log.append([line[i], line[4]]) return log''' 统计每个属性值所具有的实例数量
[['4.3', 'Iris-setosa', 1], ['4.4', 'Iris-setosa', 3],...]'''def count(log):
log_cnt = [] # 以第0列进行排序的 升序排序
log.sort(key=lambda attr: attr[0])
i = 0
while i < len(log):
cnt = log.count(log[i])
record = log[i][:]
record.append(cnt)
log_cnt.append(record)
i += cnt return log_cnt''' log_cnt 是形如: ['4.4', 'Iris-setosa', 3]
的统计对于某个属性值,对于三个类所含有的数量
返回结果形如:{4.4:[0,1,3],...}
属性值为4.4的对于三个类的实例数量分别是:0、1、3 '''def build(log_cnt):
log_dict = {} for record in log_cnt: if record[0] not in log_dict.keys():
log_dict[record[0]] = [0, 0, 0] if record[1] == 'Iris-setosa':
log_dict[record[0]][0] = record[2] elif record[1] == 'Iris-versicolor':
log_dict[record[0]][1] = record[2] elif record[1] == 'Iris-virginica':
log_dict[record[0]][2] = record[2] else: raise TypeError('Data Exception')
log_truple = sorted(log_dict.items()) return log_trupledef collect(instances, i):
log = split(instances, i)
log_cnt = count(log)
log_tuple = build(log_cnt) return log_tupledef combine(a, b):
"""'' a=('4.4', [3, 1, 0]), b=('4.5', [1, 0, 2])
combine(a,b)=('4.4', [4, 1, 2]) """
c = a[:] for i in range(len(a[1])):
c[1][i] += b[1][i] return cdef chi2(a):
"""计算两个区间的卡方值"""
m = len(a)
k = len(a[0])
r = [] '''第i个区间的实例数'''
for i in range(m):
sum = 0
for j in range(k):
sum += a[i][j]
r.append(sum)
c = [] '''第j个类的实例数'''
for j in range(k):
sum = 0
for i in range(m):
sum += a[i][j]
c.append(sum)
n = 0
'''总的实例数'''
for ele in c:
n += ele
res = 0.0
for i in range(m): for j in range(k):
Eij = 1.0 * r[i] * c[j] / n if Eij != 0:
res = 1.0 * res + 1.0 * (a[i][j] - Eij) ** 2 / Eij return res'''ChiMerge 算法''''''下面的程序可以看出,合并一个区间之后相邻区间的卡方值进行了重新计算,而原作者论文中是计算一次后根据大小直接进行合并的
下面在合并时候只是根据相邻最小的卡方值进行合并的,这个在实际操作中还是比较好的
'''def chimerge(log_tuple, max_interval):
num_interval = len(log_tuple) while num_interval > max_interval:
num_pair = num_interval - 1
chi_values = [] ''' 计算相邻区间的卡方值'''
for i in range(num_pair):
arr = [log_tuple[i][1], log_tuple[i + 1][1]]
chi_values.append(chi2(arr))
min_chi = min(chi_values) for i in range(num_pair - 1, -1, -1): if chi_values[i] == min_chi:
log_tuple[i] = combine(log_tuple[i], log_tuple[i + 1])
log_tuple[i + 1] = 'Merged'
while 'Merged' in log_tuple:
log_tuple.remove('Merged')
num_interval = len(log_tuple)
split_points = [record[0] for record in log_tuple] return split_pointsdef discrete(path):
instances = read(path)
max_interval = 6
num_log = 4
for i in range(num_log):
log_tuple = collect(instances, i)
split_points = chimerge(log_tuple, max_interval) print split_pointsif __name__ == '__main__':
print('Start: ' + ctime())
discrete('iris.data')
print('End: ' + ctime())函数说明
collect(Instances,i)
读入鸢尾花数据集,取第i个特征构造一个数据结构,以便使用ChiMerge算法。这个数据结构 形如 [('4.3', [1, 0, 0]), ('4.4', [3, 0, 0]),...]的列表,每一个元素是一个元组,元组的第一项是字符串,表示区间左端点,元组的第二项是一个列表,表示在此区间各个类别的实例数目ChiMerge(log_tuple,max_interval)
ChiMerge算法,返回区间的分裂点
程序运行结果

参考文献
http://www.aaai.org/Papers/AAAI/1992/AAAI92-019.pdf
作者:芥末无疆sss
链接:https://www.jianshu.com/p/5dee6d06f520
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。





