
DRC介绍
饿了么的 Data Replicate Center(DRC)项目用于数据双向复制和数据订阅,使用场景如下图:

要点说明:
跨机房的 Mysql 数据复制完全通过 DRC 来完成
还有很多业务团队通过 DRC 来实现数据订阅
目前饿了么100%的跨机房数据复制,90%的数据订阅都通过DRC完成,每天有大量的数据流经DRC。复制延迟保持在1s以下,从来没有发生过数据丢失和错乱的情况。
DRC的设计目标包括:
实时双向数据复制,延时 < 1s ,并能够解决双向修改时的数据冲突
数据变更订阅,能够在DB数据发生变化时通知到相关订阅方
高度可靠和保持顺序,不能丢失数据,也不能因为错乱执行顺序导致数据错误
我们最终达到了这3个目标,下面围绕着如何设计以满足以上目标介绍一下。
DRC的总体设计
DRC采用了多组件的集群化设计,整体结构如下图:

要点说明:
DRC有两个核心服务,Replicator 和 Apply,他们以集群化的方式部署,一个负责从源头数据库拉取变更,一个负责应用变更到目标数据库。
Master Replicator目前实现了 Mysql Binary Log Dump 协议,从Source Mysql 中取得 DataChangeEvent。
对于任何唯一的数据源,数据修改事件(DataChangeEvent)需要能够映射为唯一的单调递增的SCN(System Change Number),如果不能执行这样的映射,则DRC的一致性就不能得到保证。
Replicator接收到 DataChangeEvent 数据后使用一个Heap外的环状内存结构(MMAP)保存,减少GC负荷,为了保证低延迟的复制,不写入本地文件。
Replicator Slave是一种稍微特殊的 Replicator,从 Master Replicator 拉取 DataChangeEvent,并保存到本地EventBuffer中。
Replicator中保存当前 SCN Number,有一个 Master 和任意多个 Slave ,当 Masters失效后,Slave Replicator 可以选举新的 Master
Client SDK 从 Replicator 中拉取 DataChange Event序列,拉取时需要提供当前位置(SCN)和过滤条件,过滤条件支持基于库名,或者表名的过滤。
Replicator 中不保存任何 Client SDK 相关的状态信息(SCN),该信息由 Client SDK 调用方维护。
Data Apply负责把ChangeEvent按照需要的格式应用到数据库中,需要保持事务一致性,按照SCN的顺序执行。
其中 SCN 和 DataChangeEvent 是整个DRC的两个核心概念,需要详细说明一下:
SCN是一个结构体,能够单调有续,并全局唯一,绑定到唯一的事件上,每当 DRC 从 Mysql 拿到一个新的 Data Change Event,就会分配一个新的 SCN 与之对应。
每种数据源对应于一种 SCN 的结构,对于 Mysql 数据源的SCN结构体代码如下:

SCN要求单调有续,并全局唯一,所以SCN 的产生逻辑大部分情况下需要绑定到数据源的唯一逻辑上,例如 Mysql 的 SCN 实现就嵌入了 mysql 的 serverid,logIndex,logPostion,这样能保证对于一个唯一的 mysql server 来说,scn 是单调有序并唯一的,我们还加上了一个 changeId 字段,这样,如果数据抽取切换到另外一个 mysql 上了,changeId 只需要 +1,就可以保证产生的SCN依然有序,关于 Mysql Bin Log 结构的详细信息
整个SCN的产生逻辑如下图:

有了唯一的 SCN 之后,整个系统就有了保证一致性的最基础保障。SCN是在 Replicator 端生成的,并贯穿了整个 DRC 系统的各个组件,所有的组件都用相同的SCN来标志event,也用SCN来记录当前复制的位点。
下面简单介绍一下各个组件的要点,以方便之后的介绍。
Replicator: replicator 负责变更事件的抽取,SCN的生成,以及维护了一个Event Buffer 来存储取到的 event,结构如下图:
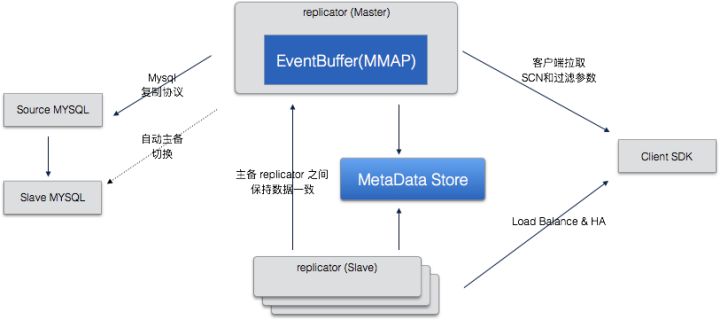
要点说明:
replicator 有一个 master 多个 slave,只有 master 会连接 DB,其他的 slave 只连接 master replicator。
SCN在各个Replicator中是一致的,当 master 失效后会选举出新的 master(zk),并从该 master 的当前位置开始复制,这样就避免了非常复杂的在多个 replicator 间保持一致的问题。
Replicator 中不保存客户端状态,Client SDK Pull 数据的时候需要指定开始 SCN 位置,所以可以随时切换到任何一个Replicator拉取数据。
如果客户端提交的SCN超过当前Replicator的最老数据,Replicator 会回源到源头的数据库拉取。
Replicator 在维护了一个 RingBuffer,用于保存 ChangeEvent,这个buffer我们叫做 EventBuffer,EventBuffer 是 DRC 提高性能的一个非常关键的环节,之后回详细说明。
Apply :Apply 部署在目标端,负责把读取到的数据写入目标数据库,或者把变更消息发送到指定的消息队列中,目前 DRC 支持 Kafka / RabbitMQ / MaxQ 等多种消息队列。

要点说明:
Apply 以 Channel 的形式在 DataApply Server 上组织复制单元
Channel 是一张表或者一组表
Channel 内部逻辑通过串联的 Filter 实现
Change 上实现了诸多的业务逻辑,例如幂等,冲突检查,并行化性能优化等等。
以上就是 DRC 的一个整体介绍,下面说一下 DRC 的实现中一些具体的技术点。
DRC 实现
数据一致保证
如何保证数据一致:一致性是 DRC 的最基本要求,DRC 通过一系列的方法保证双向复制中两边的数据一致。这其中有三个问题要说一下:
问题一:如何防止循环复制?
双向复制要解决的一个重要问题是循环复制,要能够识别出一个改变动作是来自产研,还是来自DRC工具本身。来自产研的数据变更需要复制出去,而来自DRC的数据复制不需要复制。
DRC防止冲突的方案是在由DRC产生的事务中加入DRC标记。如下图的事务2,Apply在写入时,会在事务的开头处加上一个 insert 或者是 update 语句,其中包含了 DRC 的信息。当Replicator 发现一个事物包涵该特殊标记时,就不会再复制出去。
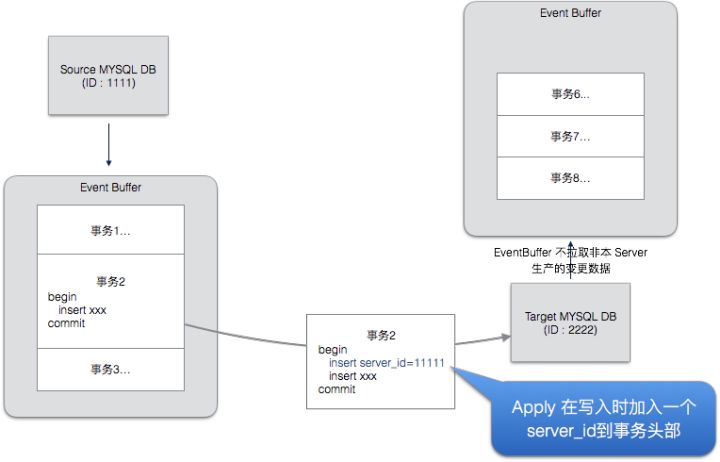
这种方式虽然避免了循环复制,带给目标端数据库带来了一些性能开销,我们会在之后的版本中通过修改 Mysql Binlog 机制来更为高效的阻断循环复制。
问题二:万一发生中断或者是故障,如果保证数据正确?
中断恢复:从中断恢复,主要靠的是SCN,因为SCN有序,并保存在可靠存储中,任何节点的失效,都可以通过SCN位点来恢复,SCN可以被保存在本地文件,ZK和数据库中,达到性能和可靠性的平衡。

幂等:另外,大部分的DB操作在DRC下是幂等的,从任意一点开始,重复执行一次,还是会得到相同的结果。DRC能够处理各种重复执行带来的异常,并且保证最终数据始终一致。这里主要靠的是详细分析各种重复执行可能带来的异常,对能够跳过的异常就直接跳过,而不停止复制。

问题三:万一一笔数据在两边都修改了,如何解决冲突?
避免冲突:首先我们通过全局定义的规则避免数据冲突,仔细设计的数据规则,让每笔数据都有自己的归属机房,两个机房同时修改一笔数据的情况很少出现。两个机房产生的数据在 ID 上是错开的,各种和业务相关的ID 也通过设计避免了重复,这样数据复制到一起后,不会发生冲突。对于有唯一键索引的数据,我们也进行了改造,加上了用于区别机房的数据字段。

冲突解决:即使如此,有时候冲突还是不可避免的,比如发生机房切换,或者是业务方的代码有Bug等,所以我们还提供2层冲突解决方案,万一发生同一笔数据,在两个机房同时修改,则引入冲突处理:
基本的冲突处理,通过时间戳完成,两边机房的都有实时同步的毫秒级别的NTP服务,每笔数据上都打上了变更时间戳。在发生冲突的时候,最后发生的修改会胜出,最终两个机房的数据都会被同步成最后的数据。
如果时间戳不能满足需要,还可以通过调用业务提供的冲突解决方案解决,冲突解决时,为业务方提供了原始数据和最新数据,由业务逻辑来决定哪个数据才是最终正确的数据。
但是我们不会对数据进行合并,因为合并带来的问题比较多,事实上看,基于时间戳已经解决了99%的数据冲突问题。

性能优化
DRC 具有非常高的吞吐量,主要归功于Replicator的本地EventBuffer,几个月的Event数据都会被缓冲到 EventBuffer 中,EventBuffer 是一个跳表结构,如下图:

其中跳表的索引是SCN,通过SCN能够快速的找到对应Event,之后按照顺序输出其后的 Event,每次输出一批Event,磁盘读取和网络传输都很高效。
EventBuffer 落地在磁盘上,通过内存映射Map到内存中。Java Heap 中只保存比较少的索引数据,大量的Event数据维持在堆外,避免大内存带来的GC开销。大部分 EventBuffer 的大小维持在512G空间,能够支持数月到数个星期的事件。
EventBuffer 中只保存了二进制的数据,数据的结构被保存在另外一个独立的存储中,我们称为MetaData Store。MetaData Store 保存了每个表的历史数据格式的快照,每次发生表结构变化,都会创建一个新的快照,结构如下:

要点说明:
Meta History 记录了数据结构以及对应的 SCN
通过 Meta History,可以回放任意时间点的数据
通过 Meta Histroy 的翻译,可以把数据翻译成业务需要的格式,或者组装成对应的SQL
以上主要介绍了DRC 的一些实现细节,DRC 作为一个核心的中间件,还有很多其他的设计,例如集群管理,高可用性设计,性能优化等,但考虑到篇幅,就不在这里全部写出来了。有兴趣的朋友可以可留言和我联系,大家共同探讨。
作者介绍:
李双涛,饿了么框架工具部高级架构师,参与了整个饿了么多活的设计和实施过程。职业生涯中,有两次参与这种大规模的整站高可用改造,一次在 Cisco Webex,一次在饿了么,积累了一些高可用和异地多活方面的经验






