
前言
微服务是当前非常流行的技术框架,通过服务的小型化、原子化以及分布式架构的弹性伸缩和高可用性,可以实现业务之间的松耦合、业务的灵活调整组合以及系统的高可用性。为业务创新和业务持续提供了一个良好的基础平台。本文分享在这种技术架构下的数据架构的设计思想以及设计要点,本文包括下面若干内容。
微服务技术框架中的多层数据架构设计
数据架构设计中的要点
要点1:数据易用性
要点2:主、副数据及数据解耦
要点3:分库分表
要点4:多源数据适配
要点5:多源数据缓存
要点6:数据集市
为了容易理解,本文用一个简化的销售模型来阐述,如下图。图1显示了客户、卖家、商品、定价、订单的关系(这里省略支付、物流等其他元素)。
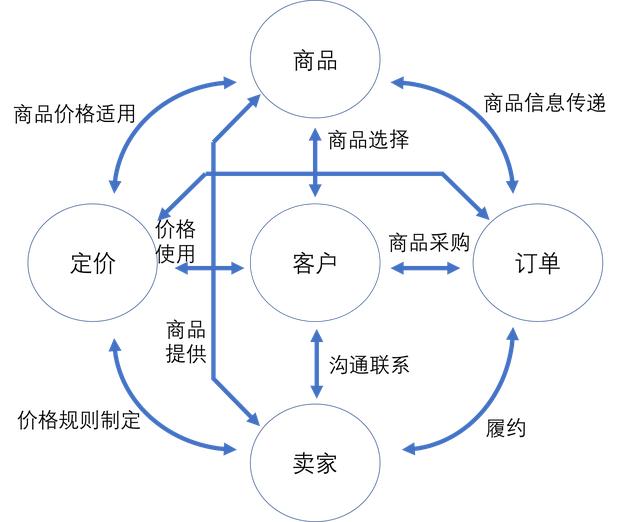
图1 销售模型
在这个销售模型中,卖家提供商品、制定价格,客户选择产品购买、形成销售订单。根据微服务的理念设计,可以划分为客户服务、卖家服务、商品服务、定价服务、订单服务,以及公共服务(比如认证、权限、通知等),如图2所示。

图2 微服务功能
微服务架构中的多层数据架构设计
分布式架构一般把系统分为 Saas(Software-as-a-Service)、Paas(Platform-as-a-Service)、Iaas(Infrastructure as a Service )三层。其中 Saas 层负责对外部提供业务服务,Paas 层提供基础应用平台,Iaas 层提供基础设施。微服务垂直嵌入这三层服务之中,相互独立。因此数据架构设计时需要考虑三层服务对数据的关注点,又要考虑微服务的独立性。
数据架构的分层设计
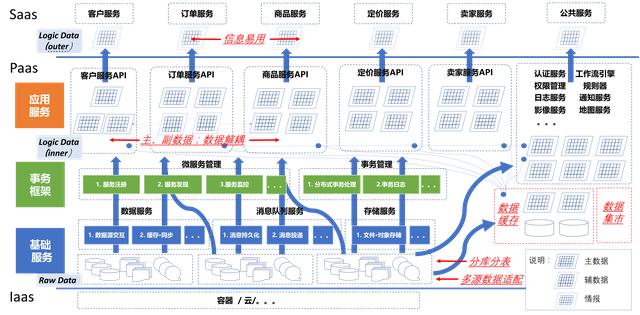
图3 微服务技术框架
如图3所示,Iaas 层提供程序运行的物理基础环境(这边涉及很多硬件·网络内容,在本文中省略)。Pass 层细分为三层,基础服务层,主要负责数据存储处理;事务框架层,主要负责微服务的注册·调度管理、分布式事务处理;应用服务层、主要实现各个微服务的 API,供其它微服务直接调用以及 Saas 层的服务调用。Saas 服务就是公开对外提供的业务服务。全文中架构技术运用到的知识点可以在群619881427免费获取。感兴趣的可以加入进来。
数据架构自下向上相应的分为 Raw Data 层、Logic Data(inner)层和 Logic Data(outer)层(Iaas 中主要以基础硬件环境为主,在本文中省略)。Raw Data 层是基于数据库、文件或者其他形式数据内容。Logic Data(inner)层是微服务 API 使用的逻辑数据,比如客户数据、订单数据等等。Logic Data(outer)层是对外服务提供数据,比如客户订单数据。因此,我们的数据架构的分层结果如图4所示。
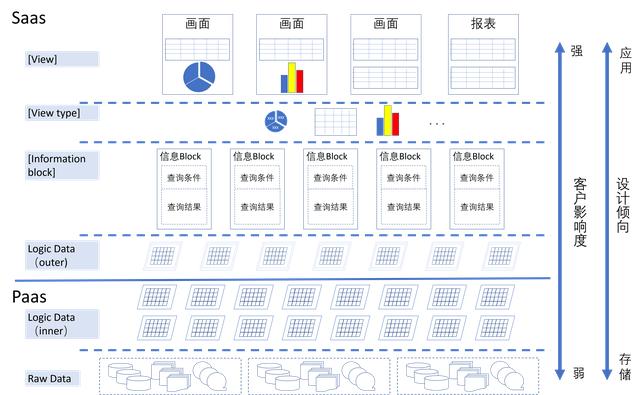
图4 数据分层架构
除此之外,很多情报会以画面或报表的形式展现出来。因此在 Logic Data(outer) 之上,可以构建 Information Block(常用的信息块)、通过 View type(显示模式)的设定后,最终 View 展现出来。
如图4所示,越靠近对外服务层,客户对设计者的影响度越大,越需要从使用性、易用性、适用性等考虑。反之,越远离对外服务层,设计上更关心数据的存储。
数据三层架构的好处是实现数据从系统实现到业务实现的逐层过渡,实现业务数据和系统数据间的松耦合。同时实现业务的灵活扩展和系统的灵活扩展。
数据架构设计中的要点
上面讲述了数据架构的分层设计,下面讲述数据架构设计中的要点。
要点1:数据易用性
数据无论用什么方式实现,其最终目的都是为业务(或者是客户)使用的。因此,在对外提供服务的时候,数据的易用性非常关键。
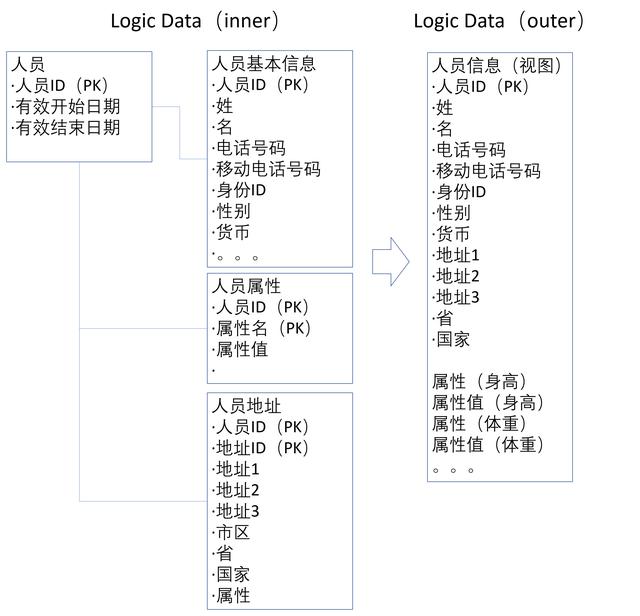
图5 数据易用性
如图5所示,客户信息在 Logic Data(inner) 层中为了数据的柔软性和非冗余,把人员信息拆成若干子表来存储。比如,人员地址表可以无限多的存储客户地址信息。这样的好处在于每次人员地址更新时,不用直接更新人员地址,而是生成一个新的地址数据,原有的地址信息作为历史数据得到保存,易于数据快速恢复和历史信息追踪。但在 Logic Data(outer)层提供外部数据的时候,首先考虑的是一次性能提供足够用的信息(毕竟查询的操作大大高于修改的操作),减少业务场景中不需要的信息。比如对一般客户只提供三个常用地址的时候,数据设计中地址1、地址2和地址3放在一张表中。
要点2:主、副数据及数据解耦
每个微服务 API 的数据完全独立是不太现实的,比如订单中需要有商品、客户(包括收货者)、卖家以及价格等数据。如果这些数据都在订单服务 API 中管理,那么客户情报的变更、价格调整等信息都要同步给订单 API 中数据,数据的耦合度就会变得非常高。在数据设计的时候,需要考虑降低数据间的相互依赖性。因此,首先需要确定每个微服务 API 的主数据和副数据。主数据指微服务 API 的核心数据,这种数据的增删改主要集中在某个微服务 API 中,比如订单服务 API 中的订单数据。副数据指参照或者映射其他微服务 API 的数据,比如订单服务 API 中的商品数据、价格数据等。其次,为了降低数据之间的耦合度,用数据关联表来表征数据间的关系。如果想去掉数据间的关联关系,直接去掉关联表即可,对数据本身的没有任何影响。具体如图6所示。
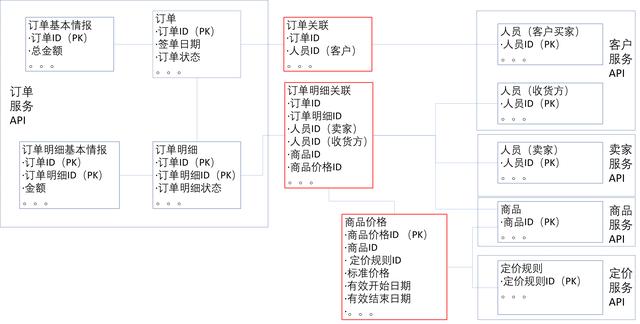
图6 主、副数据及数据解耦
要点3:分库分表
随着业务数据量不断增加,单一数据库或单一数据表中会积累大量的数据,比如订单数据,随着时间推移和客户数量的增加,产生的订单数据也会越来越多。当数据累积到一定程度后,数据操作的性能会大幅下降,也就是我们常说的数据库“带不动了”。所以,在数据架构设计阶段就应该考虑数据的分库分表。
如图7所示,分库,即我们把订单数据分为当前数据应用库、历史数据库、历史归档数据库。当前数据应用库用来支持新订单的生成以及执行中订单的增删改查。历史数据库(这里举例分为最近3个月和最近1年)当客户想看过往订单的时候才使用。历史归档数据(按年间归档)原则上不直接对客户公开,用于备查、统计分析。对于当前数据应用库,可以继续再分库,按客户号范围来分库。这样每个数据库的大小都能得到有效控制。分表,即把一条信息分别存储在两张或多张表中。比如把订单信息按基本信息和详细信息分表,就可以适用于订单的基本信息查询和订单详细信息查询。总之,分库分表的核心就是控制单一数据库的负荷(数据量和数据信息量),通过多表多库来应对业务数据量的增长。
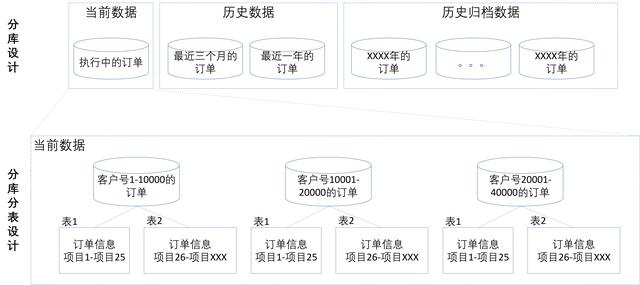
图7 分表分库
要点4:多源数据适配
传统的关系型数据库之外,有多种多样的数据源,比如图像、声音、视频等多媒体数据文件或数据流,CSV、TXT、Doc、Excle、PDF、XML 等各种异构数。这些数据都需要做相应的处理,转换成可管理的数据信息。因此在数据架构设计的时候,需要给不同性质的数据源配置相对应的读写适配器,同时也需要有统一调度的地方,如图8所示。全文中架构技术运用到的知识点可以在群619881427免费获取。感兴趣的可以加入进来。
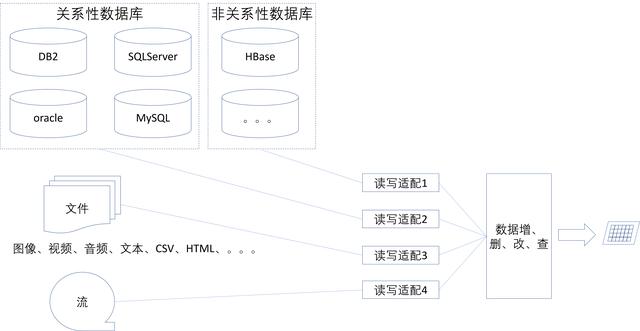
图8 多源数据适配
要点5:多源数据缓存
数据处理的性能除了处理逻辑的复杂度以外,还有很大一部分是目标数据的操作时长(含对硬件磁盘设备的读写以及网络的传输)。网络速度特别是光纤的使用后已经大幅度提高,但机器磁盘的读写效率并没有显著提高,因此减少磁盘读写是提高效率的一个重要途径。数据缓存就是把常用的数据(不会经常更改的数据)、最近使用数据放到内存中。这样就可以大幅降低系统对硬件磁盘设备的操作开销,提高整个数据系统的性能,如图9所示。
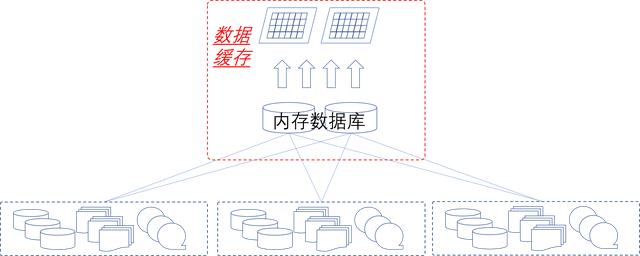
图9 数据缓存
要点6:数据集市
数据集市是一个很大的话题。当现有的数据不能简单地通过几个表数据关联以及简单加工后就可以供业务使用的时候,就需要考虑构建数据集市。数据集市以数据运用的观点来分析加工数据,通过多源数据的导入、清洗、加工、视图做成等一系列的数据操作后,为业务提供可用的、稳定的数据源。例如,对销售分析中、什么样的客户喜欢什么样的商品、价格对销售金额的影响、销售金额跟地区日期的关联关系等多维度分析,就要用数据集市的概念,如图10所示。
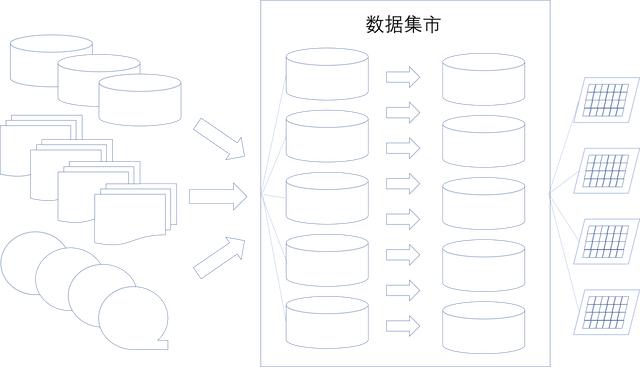
图10 数据集市
数据承载着信息,好的数据架构设计会使业务系统变得更加流畅、更加容易理解和维护。
作者:Java架构资源分享
来源:https://my.oschina.net/u/3779583/blog/1799290






