
第一模块
课程名称:Hadoop 系统入门+核心精讲
章节名称:2-1 ~ 2-10
讲师姓名:Michael_PK
第二模块
内容概述:
2-1 ~ 2-10 章节系统的介绍了Hadoop和Hadoop的3大核心组件——HDFS、MapReduce和YARN,已经Haddop的各个发行版的优缺点,系统而全面的带领我认识了Hadoop,很大程度上打消了我对Hadoop的神秘感,感觉大数据也不在那么高不可攀!
第三模块
学习心得:
毕业到现在走的技术路线都是java 的web开发,对大数据相关的技术知道的不多,这次借助本门课很好的阔宽了自己的技术视野,知道了java开发的另一条技术路线——java开发大数据方向。当今最火的技术当属ABC,而java转大数据开发具有天然的优势,而Hadoop又是大数据开发中绕不开的·一个技术栈,有必要进行深入学习,下面附上学习笔记:
2-3 Hadoop核心组件之分布式文件系统HDFS
源自于Google的GFS论文,论文发表于2003年10月
HDFS是GFS的克隆版
HDFS特点:扩展性&容错性&海量数据存储
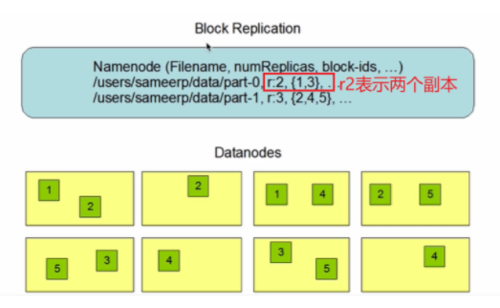
容错实现方式:把数据/文件拆成块,以block为单位进行存储,每个block都存在多个副本,每个副本存在不同机器上。
HDFS工作方式:
1.将文件切分成指定大小的数据块并以多份副本存储在多个机器上。
解析:
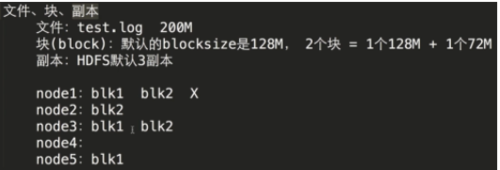
2.数据切分、多副本、容错性等操作对用户是透明的
2-4 Hadoop核心组件之MapReduce(分布式计算框架)
源自于Google的MapReduce论文,发布于2004年12月
MapREduce是Google MapReduce的克隆版
特点:扩展性&容错性&海量数据离线处理
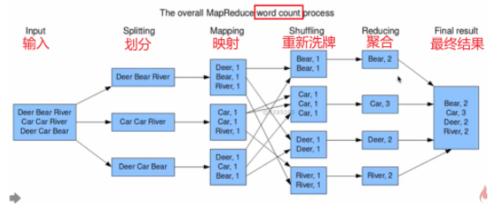
MapReduce应用统计实例——词频统计
2-5 Hadoop核心组件之YARN(资源调度器)、
YARN:yet another resource negotiator
负责整个资源的管理和调度
特点:扩展性&容错性&多框架资源统一调度
理解多框架资源统一调度:
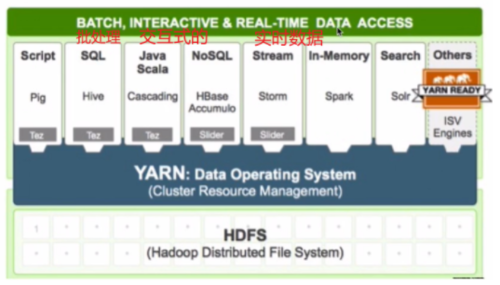
借助YARN可以很方便的进行资源管理和作业调度
2-6 Hadoop优势
高可靠性:
数据块多副本
重新调度计算
扩展信:
水平扩展
一个集群中可以容纳千计万计的节点
其他:
机器廉价,成本低
成熟生态圈
2-7 Hadoop发展史
链接:infoQ中有一篇文章......
2-8 Hadoop生态圈
狭义的Haddop:
HDFS
YARN
MapReduce
广义的Haoop:
以hadoop为核心构建起来的一套大数据技术的生态圈!!!
圈中的子系统只去解决特定的问题域,而不是搞一个全能的大系统。
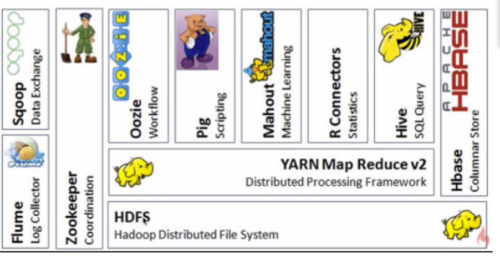
Mahout:不推荐使用,因为差不多已经停止维护
Hadoop生态系统特点:
开源、社区活跃
包括了大数据的方方面面
成熟的生态圈
注意:JD上的职位描述,Hadoop指的就是狭义上的Hadoop
2-9 Hadoop发行版
常用Hadoop发行版:
apache
优点:纯开源
缺点:不同版本不同框架之间的整合很容易出现jar冲突,会吐血的!!!安装方式只支持纯手工安装
CDH(国内的使用率在60 - 70)
优点:安装简单,官方提供了cm(cloudera manager)通过页面就可以一键安装,升级,底层支持impala;与spark联系的非常紧密,文档也写的非常好
缺点:cm不开源,但CDH版本开源,与社区版本有些许出入(不开源的化,用起来,不踏实!!!
Hortonworks:HDP 企业发布自己的数据平台可以直接基于页面框架进行改造
优点:原装Hadoop,纯开源、支持tez
缺点:企业级安全不开源
MapR(了解下就行,不建议使用)
实际使用时建议选用CDH、HDP
第四模块
学习截图:






热门评论
-

只是为了好玩2022-08-18 0
查看全部评论大佬多写点,让我多学习学习。