
【一、项目背景】
小米应用商店给用户发现最好的安卓应用和游戏,安全可靠,可是要下载东西要一个一个的搜索太麻烦了。而已速度不是很快。
今天用多线程爬取小米应用商店的游戏模块。快速获取。
【二、项目目标】
目标 :应用分类 - 聊天社交 应用名称, 应用链接,显示在控制台供用户下载。
【三、涉及的库和网站】
1、网址:百度搜 - 小米应用商店,进入官网。
2、涉及的库:reques****ts、threading 、queue 、json、time
3、软件:PyCharm
【四、项目分析】
1、确认是否为动态加载。
通过页面局部刷新, 右键查看网页源代码,搜索关键字未搜到 。断定此网站为动态加载网站,需要抓取网络数据包分析。
2、使用chrome浏览器,F12抓取网络数据包。
1)抓取返回json数据的URL地址(Headers中的Request URL)。
http://app.mi.com/categotyAllListApi?page={}&categoryId=2&pageSize=30
2)查看并分析查询参数(headers中的Query String Parameters)。
page: 1
categoryId: 2
pageSize: 30
发现只有page再变,0 1 2 3 … … ,这样我们就可以通过控制page的直拼接多个返回json数据的URL地址。
【五、项目实施】
1、我们定义一个class类继承object,然后定义init方法继承self,再定义一个主函数main继承self。准备导入库,url地址和请求头headers。
import requests
from threading import Thread
from queue import Queue
import json
import time
class XiaomiSpider(object):
def __init__(self):
self.headers = {'User-Agent':'Mozilla/5.0'}
self.url = 'http://app.mi.com/categotyAllListApi?page={}&categoryId=15&pageSize=30'
def main(self):
pass
if __name__ == '__main__':
imageSpider = XiaomiSpider()
imageSpider.main()
2、定义队列,用来存放URL地址
self.url_queue = Queue()
3、URL入队列
def url_in(self):
# 拼接多个URL地址,然后put()到队列中
for i in range(67):
self.url.format((str(i)))
self.url_queue.put(self.url)
4、定义线程事件函数get_page(请求数据)
def get_page(self):
# 先get()URL地址,发请求
while True:
# 当队列不为空时,获取url地址
if not self.url_queue.empty():
url = self.url_queue.get()
html = requests.get(url,headers=self.headers).text
self.parse_page(html)
else:
break
5、定义函数parse_page 解析json模块,提取应用名称,应用链接内容。
# 解析函数
def parse_page(self,html):
app_json = json.loads(html)
for app in app_json['data']:
# 应用名称
name = app['displayName']
# 应用链接
link = 'http://app.mi.com/details?id={}'.format(app['packageName'])
d = { '名称' : name,'链接' : link }
print(d)
6、main方法, 定义t_list = [] 存放所有线程的列表。调用get_page多线程爬取。
def main(self):
self.url_in()
# 存放所有线程的列表
t_list = []
for i in range(10):
t = Thread(target=self.get_page)
t.start()
t_list.append(t)
7、for循环遍历列表,统一回收线程。
# 统一回收线程
for p in t_list:
p.join()
8、统计一下执行时间。
start = time.time()
spider = XiaomiSpider()
spider.main()
end = time.time()
print('执行时间:%.2f' % (end-start))
【六、效果展示】
1、运行程序。点击运行,将游戏名称,下载链接,执行时间,显示在控制台。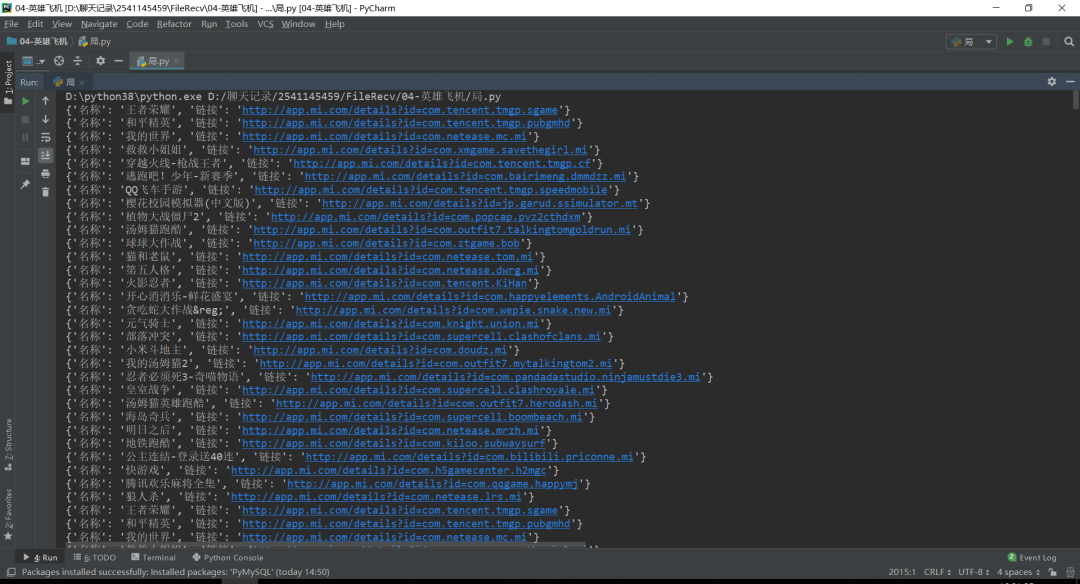
2、点击蓝色的网址可以直接去到下载页面下载应用,如下图所示。
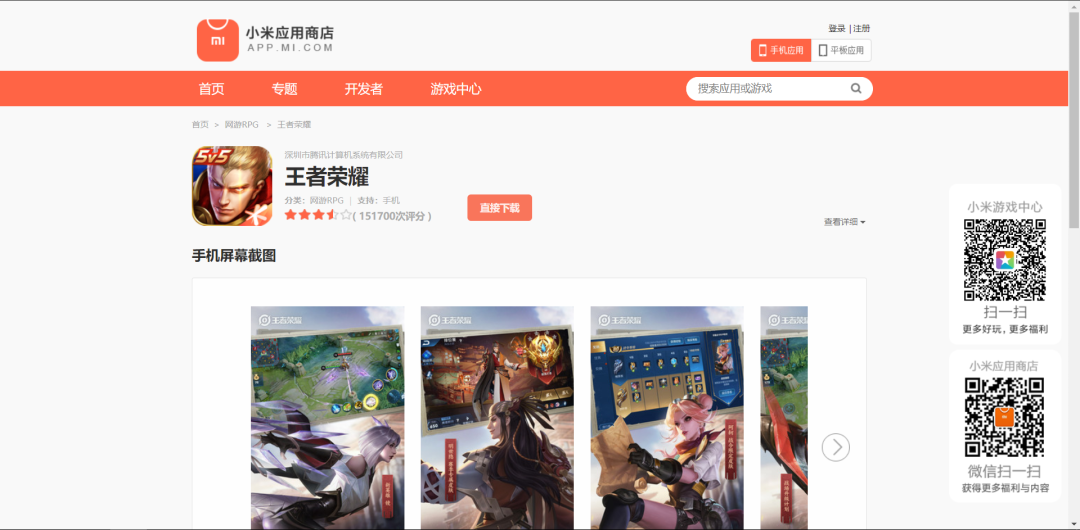
【七、总结】
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、Python多线程优点。使用线程可以把占据长时间的程序中的任务放到后台去处,程序的运行速度可能加快。
3、单线程可以被抢占(中断),而已多线程就有了更多的选择。而已在其他线程正在运行时,线程可以暂时搁置(也称为睡眠)。可以释放一些珍贵的资源如内存占用。
4、大家也可以尝试在爬取其他分类,按照操作步骤,自己尝试去做。自己实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。





