
1 简介
传统的图像识别一般都是识别花、鸟、汽车等不同类别物体,而细粒度图像识别则是要识别同一类物体下的不同子类。举个例子,识别一张图片是猫、狗、汽车还是飞机就是传统的图像识别,而识别一张图片是贵宾犬、边境牧羊犬、吉娃娃还是斗牛犬,则是细粒度图像识别。不同的犬类相似性一般都很高,比如下面的哈士奇和阿拉斯加雪橇犬,如果事先不知道它们有差别的部位,很难正确识别。现在图像识别大都使用卷积神经网络CNN,卷积层会针对整个图像(不论是背景还是物体)提取特征,而细粒度图像识别重点在于物体的一些关键部分,如此一来CNN提取的有很多特征向量都是没用的。

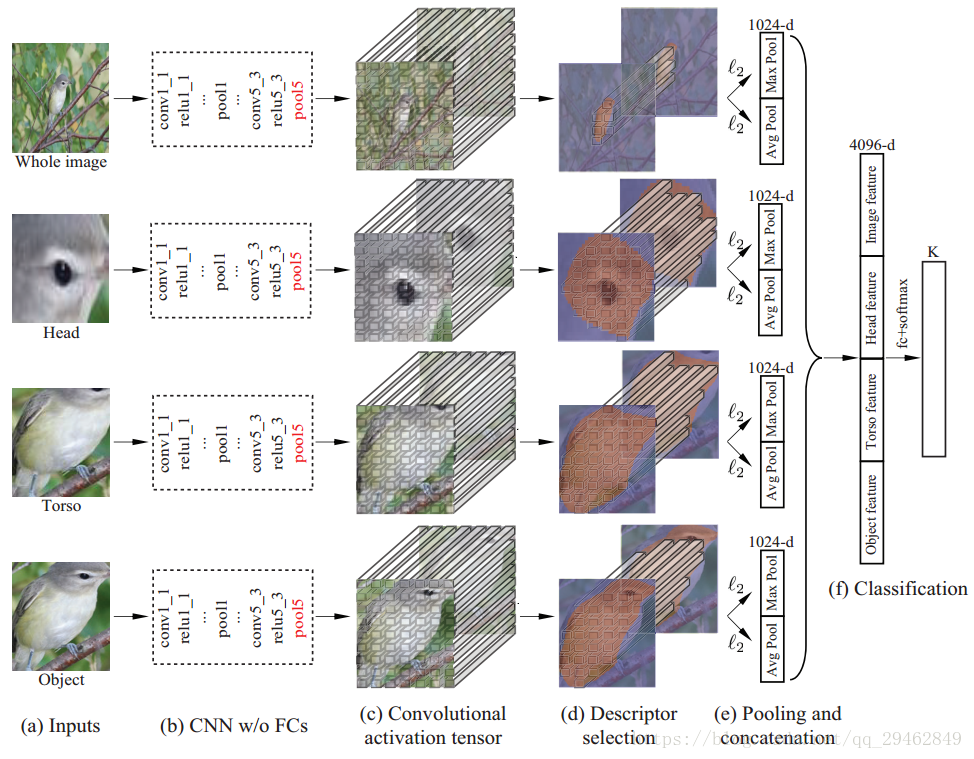
前人已经提出了很多先检测物体部位后识别的方法。本文提出了Mask-CNN模型(M-CNN),它在训练时仅需要part annotations和image-level标签这两个信息。其中part annotations分成两个集合:头部和躯干,如此part localization就成了一个三类分割问题。完整的网络可见下图,M-CNN是一个四线模型(four-stream),四个输入分别为完整图像、检测到的头部、检测到的躯干和检测到的完整物体,每条线程通过卷积最后都得到了deep descriptors(应该是常说的特征图),进而得到1024-d向量,将四个向量拼接在一起,通过l2l2正则化、全连接层和softmax,最后得到类别。

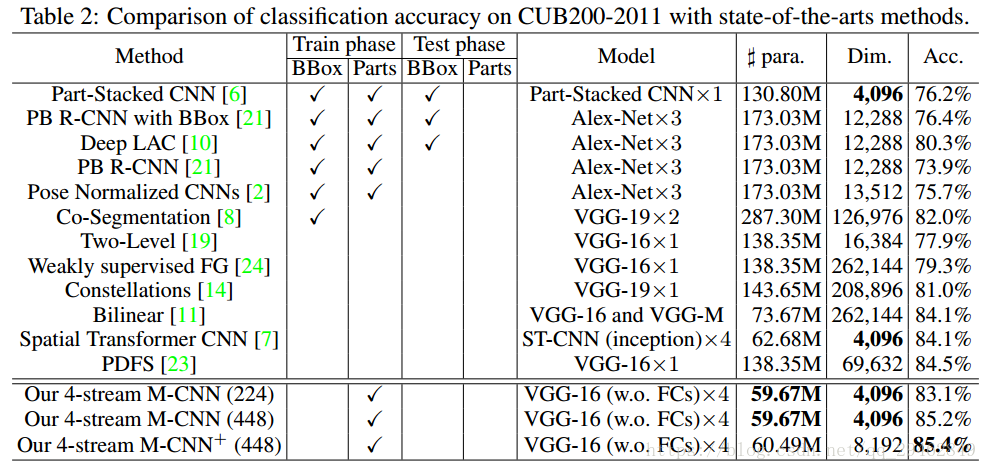
文章做出了三大贡献: 1、在细粒度图像识别方面,M-CNN是首个端到端的,将深度卷积描述符运用到物体检测的模型;2、M-CNN的参数最少(40.96M),向量维度最小(8192-d),CUB200-2011上准确率最高(85.4%)。如果通过SVD压缩特征向量至4096-d,准确率还能提高到85.5%;3、part localization方面同样比其他细粒度识别方法的高,尤其是其他方法还需要额外的边界框(bounding boxes)头部定 位准确率要比state-of-the-art高10%。
2 相关工作
过去几年,细粒度识别方法可以分成三类。第一类单纯地增加网络深度;第二类试图消除物体姿势、相机位置等影响,在更加统一的环境下进行分类;第三类注重物体部分的细节,因为现实中不同子类的区别也正是在一些独特的细节方面。
part-based细粒度识别方法也有许多区别。例如有的方法在训练时既用到了bounding boxes又用到了part annotations。有的方法在测试阶段也使用了bounding boxes以确保准确率。有的方法不使用任何额外信息,只用图像级别的标签来训练(弱监督)。还有一些方法基于分割而非基于bounding box。
3.1 Learning Object and Part Masks
首先,整个M-CNN的设计基于全卷积网络(FCN),也就是说,前面的掩膜和特征提取只用到了卷积层。作者不仅用全卷积网络(FCN)定位细粒度图像中的目标和parts,还将预测的分割部分视为目标和parts的掩膜。
在数据集CUB200-2011中,每个鸟类细粒度图像都有许多part annotations,比如左腿、右腿、喉、喙、眼睛、肚子、前额等等,它们都以key points的形式标注(见图2的第一张)。本论文将这些key points分成头、躯干两大类,简单地连接这些点来生成头和躯干两个Mask,剩下的都是背景。学习Mask的网络结构如下所示:

以下是部分图像学习到的Mask。红色的称作head mask,蓝色的称作torse mask,这两个合并在一起就是一个完整的物体,称作object mask。学习这三个mask就是标题说的Learning Object and Part Masks(不得不说一下,当时我愣是没看懂这标题的意思)。需要注意的是,虽然基于key points生成的ground-truth不是特别准确,但是FCN模型能够返回更加准确的Mask。

3.2 M-CNN训练
经过了3.1的FCN,我们已经得到了head mask、torse mask和object mask三个Mask。接下来,前面提到的four-stream model就要派上用场了。
根据上面三个Mask,返回对应的 mallest rectangle bounding box,再加上原图本身,这四张图像就是four-stream model的输入;
(a)->(b)->(c):作者选用VGG-16作为基础模型,四个输入通过五个卷积层、relu层和池化层,最终得到512维的特征向量。如果输入尺寸统一为224*224,那么它们特征向量为7*7*512,其实它也对应着一张图像7*7方格的空间位置;
(c)->(d):对于后三条线程,把Mask用最近邻方法缩放成7*7大小地二值矩阵,并和对应的7*7*512的特征向量比较:如果某一条512-d向量对应位置的Mask值为1(表示有检测到东西),则向量的值保留,如果对应的Mask值为0,则向量的值置零。而第一条线程,也需要通过object mask的过滤;
(d)->(e):每条线程中,对于被Mask选中的那么多条512-d特征向量,用求平均和求最大值两种方法得到两条512-d特征向量,并经过l2l2正则化处理。最后把两个向量拼接起来成为一条1024-d的向量。
(e)->(f):经过上一步,每条线程都有一个1024-d的向量了,将它们拼接起来,送进全连接层 + softmax,得到结果。由于CUB200-2011有200个类别,所以最终向量也是长200。
训练时,所有图像都保持原有的分辨率,并且只取中间384*384的部分(应该是为了统一尺寸+去除部分背景);
M-CNN的四个线程都是端到端训练的,而且参数同时学习;
训练M-CNN时,前面的FCN参数保持不变。
4 实验
4.1 数据集和封装细节
Caltech-UCSD 2011 bird dataset有200种鸟类,其中每类都有30个训练图像,每张图像还有15个标注点,用来标记鸟类的身体部位。
四线程网络中每一条都有一个VGG-16模型,其参数通过在ImageNet分类上预训练得到。
作者还用水平翻转的方法使训练图像翻倍。在测试时将原图和对应的翻转图像的预测求平均,并输出得分最高的那个分类。
直接使用softmax的结果要比使用logistic回归差
4.2 分类准确度
4.2.1 Baseline
为了验证M-CNN的优越性,作者额外设计了两个Baseline方法:
在4-stream M-CNN中,把卷积网络替换成全连接层。于是(b)到(e)变成一个最后为全连接层的CNN,输出4096-d的向量,拼接起来为16384-d的向量。此方法称作“4-stream FCs”。
抛弃(d)部分的descriptor selection,把(c)的结果直接求平均和求最大值。此方法称作“4-stream Pooling”。
三种方法的结果:

4.2.2 与state-of-the-art对比
M-CNN准确率的提升之路:
一开始,输入的图像是224*224,M-CNN的准确率有83.1%;
将输入图像变为448*448后,准确率提升到了85.3%;
提高4-stream M-CNN的输入大小到448*448后,准确率反而有些下降;
如果从relu5_2层来提取deep descriptors,并且用Mask过滤一遍,提取出4096-d向量,再和pool5提取出来的拼在一起,变成一个8096-d向量,后续操作相同。该模型称作“4-stream M-CNN+”,它的准确率提升到了85.4%;
用SVD whitening方法将上述的8096-d向量压缩到4096-d,准确率提升到了85.5%;
如果CNN部分采用和part-stacked CNN一样的 Alex-Net模型,准确率只有78.0%,但还是比part-stacked CNN高。关键是替换后的参数只有9.74M了。
为了与其他方法公平比较,所有方法在测试时都不使用part annotations。实验结果如下:
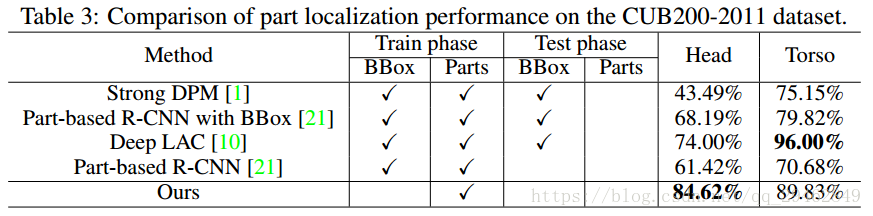
4.3 Part定位结果
为了评价定位效果,作者采用常用的PCP准则(Percentage of Correctly Localized Parts),该准则指的是与ground-truth相比,IOU大于50%的bounding box的比例;
下表是和其他方法相比的分割结果。作者的方法和Deep LAC相比躯干的准确率更低,主要是因为Deep LAC在测试时有用到Bounding box,而M-CNN没有。
4.4 object分割结果
下图是一个分割的结果。第一行是原图像,第二行是ground-truth,第三行是M-CNN的分割结果。M-CNN在分割鸟的细微部分(例如爪子)存在一些困难,但M-CNN的任务不是细致地分割出物体,因此可以不用做微调。






