
摘要
我们针对移动端以及嵌入式视觉的应用提出了一类有效的模型叫MobileNets。MobileNets基于一种流线型结构使用深度可分离卷积来构造轻型权重深度神经网络。我们介绍两个能够有效权衡延迟和准确率的简单的全局超参数。这些超参数允许模型构造器能够根据特定问题选择合适大小的模型。我们在资源和准确率的权衡方面做了大量的实验并且相较于其他在ImageNet分类任务上著名的模型有很好的表现。然后,我们演示了MobileNets在广泛应用上的有效性,使用实例包含目标检测、细粒度分类、人脸属性以及大规模地理位置信息。
1.引言
自从著名的深度卷积神经网络AlexNet赢得ImageNet竞赛:ILSVRC 2012之后,卷积神经网络普遍应用在计算机视觉领域。为了得到更高的准确率,普遍的趋势是使网络更深更复杂。然而,这些在提升准确率的提升在尺寸和速度方面并不一定使网络更加有效。在大多现实世界应用中,比如机器人、无人驾驶和增强现实,识别任务需要在有限的计算平台上实时实现。
本文描述了一个有效的网络结构以及两组用于构建小型、低延迟模型的超参数,能在移动以及嵌入式视觉应用上轻易匹配设计要求。在第二节中回顾了现有构建小型模型的工作。第三节描述了MobileNet的结构以及两种超参数-宽度乘法器(width multiplier)和分辨率乘法器(resolution multiplier)来定义更小更有效的MobileNets。第四节描述了在ImageNet上的实验和大量不同的应用场景以及使用实例。第五节以总结和结论结束。
2.现有工作
近期已经有一些构造小而有效的神经网络的文献,如SqueezeNet、Flattened convolutional neural networks for feedforward acceleration、Imagenet classification using binary convolutional neural networks、Factorized convolutional neural networks、Quantized convolutional neural networks for mobile devices。这些方法可以大概分为要么是压缩预训练网络,要么直接训练小型网络。本文提出一类神经网络结构允许特定模型开发人员对于其应用上可以选择一个小型网络能匹配已有限制性的资源(延迟、尺寸)。MobileNets首先聚焦于优化延迟,但是也产生小型网络,许多文献在小型网络上只聚焦于尺寸但是没有考虑过速度问题。
MobileNets首先用深度可分离卷积(Rigid-motion scattering for image classification中首先被提出)进行构建,随后被用在inception结构中(GoogLeNetv2)来减少首先几层的计算量。Flattened networks构建网络运用完全分解的卷积并证明了极大分解网络的重要性。而Factorized Networks介绍了一个相似的分解卷积和拓扑连接的使用。随后,Xception network描述了如何放大深度可分离滤波器来完成InceptionV3网络。另一个小型网络是SqueezeNet,使用bottleneck的方法来设计一个小型网络。其他的减少计算的网络包含STN(Structured trans- forms for small-footprint deep learning.)和deep fried convnets(Deep fried convnets)。
另一种不同的途径就是收缩、分解、压缩预训练网络。基于乘积量化的压缩(Quantized convolutional neural networks for mobile devices.)基于哈希的压缩(Compressing neural networks with the hashing trick)基于剪枝、矢量量化、霍夫曼编码的压缩(Deep compression: Com- pressing deep neural network with pruning, trained quantiza- tion and huffman coding.)也被提出来。另外各种因子分解也被提出来加速预训练网络(Speeding up convolutional neural networks with low rank expansions.)(Speeding-up convolutional neural net- works using fine-tuned cp-decomposition.)其他方法来训练小型网络即为蒸馏法(Distillingtheknowledge in a neural network)即用一个大型的网络来教导一个小型网络。其于我们的方法相辅相成,在第4节中包含了一些我们的用例。另一种新兴的方法即低比特网络(Training deep neural networks with low precision multiplications.)(Quantized neural networks: Training neural net- works with low precision weights and activations.)(Xnor- net: Imagenet classification using binary convolutional neu- ral networks.)。
3.MobileNet结构
本节首先描述MobileNet的核心部分也就是深度可分离卷积。然后描述描述MobileNet的网络结构和两个模型收缩超参数即宽度乘法器和分辨率乘法器。
3.1 深度可分离卷积
MobileNet是一种基于深度可分离卷积的模型,深度可分离卷积是一种将标准卷积分解成深度卷积以及一个1x1的卷积即逐点卷积。对于MobileNet而言,深度卷积针对每个单个输入通道应用单个滤波器进行滤波,然后逐点卷积应用1x1的卷积操作来结合所有深度卷积得到的输出。而标准卷积一步即对所有的输入进行结合得到新的一系列输出。深度可分离卷积将其分成了两步,针对每个单独层进行滤波然后下一步即结合。这种分解能够有效的大量减少计算量以及模型的大小。如图1所示,一个标准的卷积1(a)被分解成深度卷积1(b)以及1x1的逐点卷积1(c)。
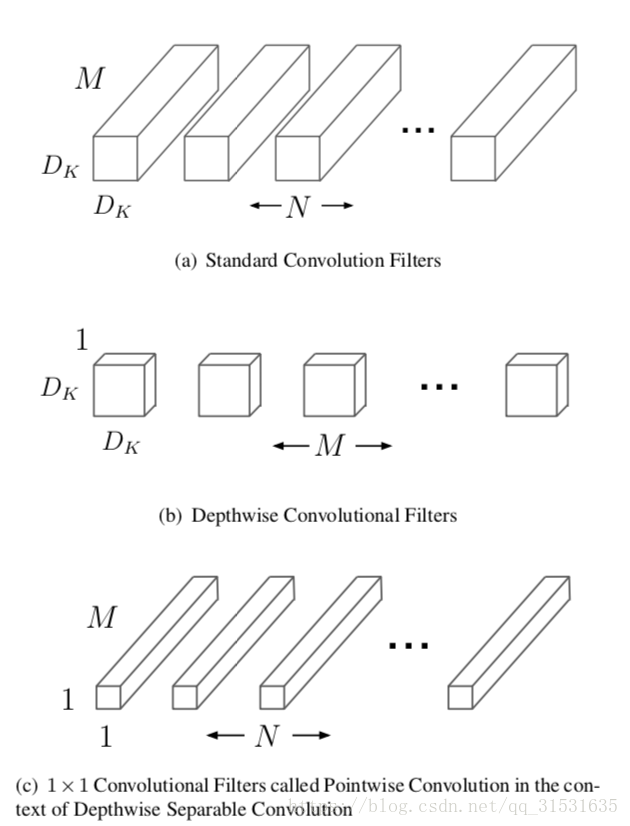
一个标准卷积层输入
标准卷积层通过由大小为
标准卷积的输出的卷积图,假设步长为1,则padding由下式计算:
标准的卷积操作基于卷积核和组合特征来对滤波特征产生效果来产生一种新的表示。滤波和组合能够通过分解卷积操作来分成两个独立的部分,这就叫做深度可分离卷积,可以大幅度降度计算成本。
深度可分离卷积由两层构成:深度卷积和逐点卷积。我们使用深度卷积来针对每一个输入通道用单个卷积核进行卷积,得到输入通道数的深度,然后运用逐点卷积,即应用一个简单的1x1卷积,来对深度卷积中的输出进行线性结合。MobileNets对每层使用batchnorm和ReLU非线性激活。
深度卷积对每个通道使用一种卷积核,可以写成:
深度卷积的计算量为:
深度卷积相对于标准卷积十分有效,然而其只对输入通道进行卷积,没有对其进行组合来产生新的特征。因此下一层利用另外的层利用1x1卷积来对深度卷积的输出计算一个线性组合从而产生新的特征。
那么深度卷积加上1x1卷积的逐点卷积的结合就叫做深度可分离卷积,最开始在(Rigid-motion scattering for image classification.)中被提出。
深度可分离卷积的计算量为:
通过将卷积分为滤波和组合的过程得到对计算量的缩减:
MobileNet使用3x3的深度可分离卷积相较于标准卷积少了8到9倍的计算量,然而只有极小的准确率的下降如第4节。
另外的空间维数的分解方式如(Flattenedconvolutional neural networks for feedforward acceleration)(Rethinking the inception architecture for computer vision.)中。但是相较于深度可分离卷积,计算量的减少也没有这么多。
3.2 网络结构和训练
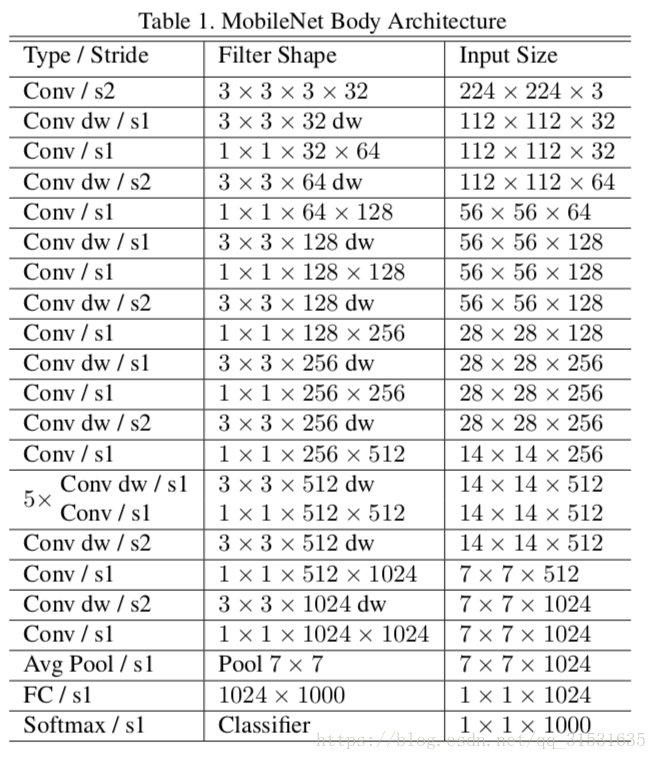
MobileNet结构就像前面所提到的由深度可分离卷积所构成,且除了第一层之外为全卷积。通过用这些简单的项定义网络能够更容易的探索网络的拓扑结构来找到一个更好的网络。MobileNet结构由下表1定义。
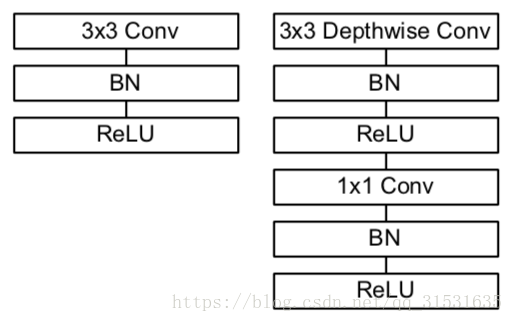
所有的层都跟着一个batchnorm(Batch normalization: Accelerating deep network training by reducing internal covariate shift.)以及ReLU非线性激活函数,除了最后一层全连接层没有非线性激活函数直接送入softmax层进行分类。下图2比较了常规的卷积、batchnorm、ReLU层以及分解层包含深度可分离卷积、1x1卷积、以及在每层卷积层之后的batchnorm和ReLU非线性激活函数。
下采样通过深度可分离卷积中第一层的深度卷积通过步长来进行控制,最后将卷积层中提取到的特征图经过全局平均池化层降维至1维,然后送入全连接层分成1000类。将深度卷积和逐点卷积算作两层,则MobileNet含有28层。
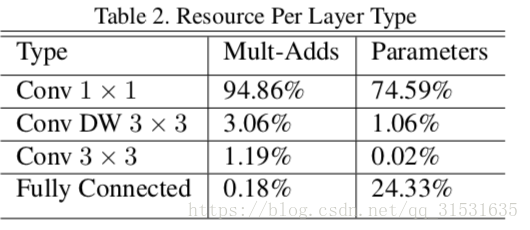
用这些少数的乘加运算来定义简单的网络是不够的。确保这些操作要十分有效也是非常重要的。实例化非结构稀疏矩阵操作除非有一个非常高的稀疏度,否则不一定比稠密矩阵操作更加快速。我们的模型结构几乎将左右的计算量都放在稠密的1x1卷积中,这可以通过高度优化的GEMM通用矩阵乘法函数来实现。通常卷积由GEMM来实现,但是要求一个im2col即在内存中初始化重新排序来映射到GEMM。比如,这个方法用在caffe模型框架中(Caffe: Convolu- tional architecture for fast feature embedding)。而1x1卷积则不需要内存的重新排序,并且能直接用GEMM方法实现,因此是最优化的数值线性代数算法之一。MobileNet95%的计算时间都花费在1x1的逐点卷积上,并且占参数量的75%,如表2所示。其他额外的参数几乎都集中于全连接层。
MobileNet模型在Tensorflow框架(Tensorflow: Large-scale machine learning on heterogeneous systems)中使用与InceptionV3(Rethinking the inception architecture for computer vision.)中一样的RMSprop异步梯度下降算法(] T. Tieleman and G. Hinton. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 4(2), 2012. 4
)然而,与训练大型网络模型不同的是,我们使用了非常少的正则化以及数据增强技术,因为小模型很少有过拟合的问题。当训练MobileNet时,我们没有使用side heads或者标签平滑操作,另外通过限制在大型Inception层训练中小的裁剪的大小来减少失真图片的数量。另外,我们发现在深度卷积中尽量不加入权重衰减(L2范数)是非常重要的,因为深度卷积中参数量很小。对于ImageNet数据集,无论模型大小,所有模型都被相同的超参数训练模型,下一节来说明。
3.3 宽度乘法器:更薄的模型
尽管最基本的MobileNet结构已经非常小并且低延迟。而很多时候特定的案例或者应用可能会要求模型变得更小更快。为了构建这些更小并且计算量更小的模型,我们引入了一种非常简单的参数
加上宽度乘法器的深度可分离卷积的计算量如下:
由于
3.4 分辨率乘法器:约化表达
第二个薄化神经网络计算量的超参数是分辨率乘法器
我们现在可以对网络中的核心层的深度可分离卷积加上宽度乘法器
其中
接下来举个例子,MobileNet中的一个典型的层以及深度可分离卷积、宽度乘法器、分辨率乘法器是如何约化计算量和参数量。表3中展示了一层的计算量和参数量以及结构收缩的这些方法应用在这些层之后的变化。第一行显示了全连接层的Mult-Adds和参数量,其输入特征图为14x14x512,并且卷积核的尺寸为3x3x512x512。我们将在下一节详细阐述资源和准确率之间的权衡关系。

4 实验
在这一节,我们首先调研了深度可分离卷积以及通过收缩网络的宽度而不是减少网络的层数带来的影响。然后展示了基于两个超参数:宽度乘法器和分辨率乘法器,来收缩网络的权衡,并且与一些著名的网络模型进行了对比。然后调研了MobileNet运用在一些不同的应用上的效果。
4.1 模型选择
首先我们展示了运用深度可分离卷积的MobileNet与全标准卷积网络的对比,如表4,我们可以看见在ImageNet数据集上使用深度可分离卷积相较于标准卷积准确率只减少了1%,但在计算量和参数量上却减少了很多。

接下来,我们展示了利用宽度是乘法器的薄化模型与只有少数层的千层神经网络进行对比,为了使MobileNet更浅,表1中的5层14x14x512的特征尺寸的可分离卷积层都被去掉了。表5展示了相同计算量参数量的情况下,让MobileNets薄化3%比让它更浅效果更好。

4.2 模型压缩超参数
表6展示了利用宽度乘法器
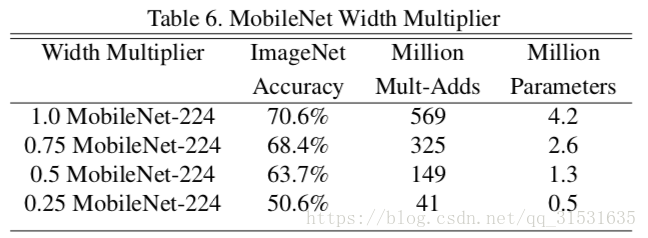
表7展示了通过利用约化的MobileNets时不同分辨率乘法器时准确率、计算量和尺寸之间的权衡关系。准确率随着分辨率下降而平滑减小。
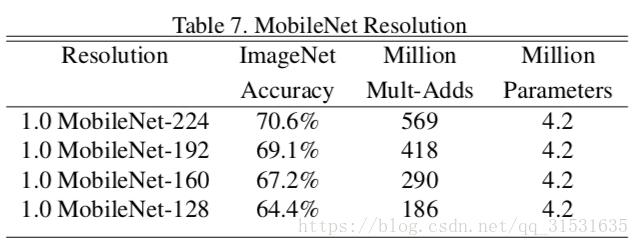
图3显示了16个不同的模型在ImageNet中准确率和计算量之间的权衡。这16个模型由4个不同的宽度乘法器{1,0.75,0.5,0.25}以及不同分辨率{224,192,160,128}组成。当
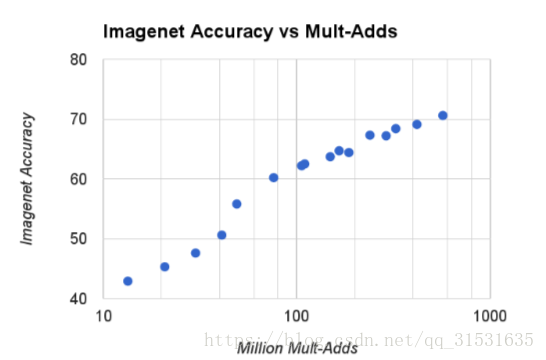
图4显示了16个不同模型在ImageNet中准确率和参数量之间的权衡。这16个模型由4个不同的宽度乘法器{1,0.75,0.5,0.25}以及不同分辨率{224,192,160,128}组成。
表8比较了最基本的MobileNet与原始GoogleNet和VGG16。MobileNet和VGG16准确率几乎一样,但是参数量少了32倍,计算量少了27倍。相较于GoogleNet而言,准确率更高,并且参数量和计算量都少了2.5倍。

表9比较了约化后的MobileNet(

4.3 细粒度识别
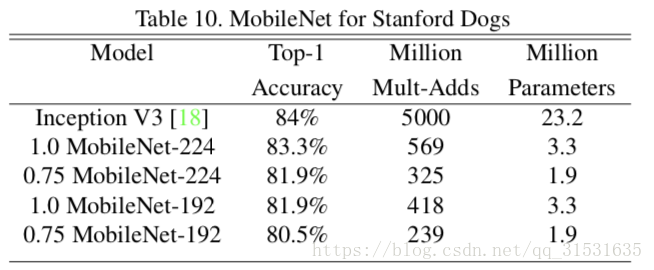
在斯坦福狗数据集(Novel dataset for fine-grained image categorization)上训练MobileNet来进行细粒度识别。我们扩展了(The unreasonable effectiveness of noisy data for fine-grained recognition.)中的方法,并且从网上收集了一个相对其更大,噪声更多的训练集,我们使用网上的噪声数据集先预训练一个细粒度识别狗的模型,然后在斯坦福狗数据集上进行精调。结果显示在表10中。MobileNet几乎可以实现最好的结果,并且大大减少了计算量和尺寸。
4.4 大规模地理信息
(PlaNet - Photo Geolocation with Convolutional Neural Networks)描述了在哪里拍照是一个分类问题。这个方法将地球分割为地理网格作为目标类来利用数以百万的地理标记图片训练一个卷积神经网络。PlaNet已经成功定位了大量照片,相对( IM2GPS: estimating geographic in- formation from a single image)(Large-Scale Image Geolocalization.)针对相同的任务,效果更好。
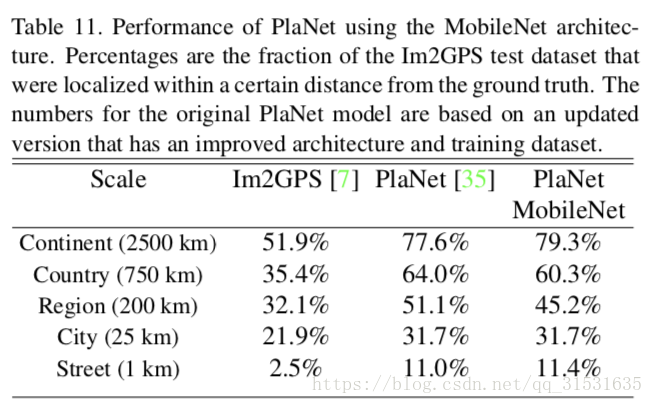
我们在相同数据集上利用MobileNet结构重新训练PlaNet,因为PlaNet基于inceptionV3结构,其有5200万参数以及5.74亿的乘加计算量。而MobileNet只有1300万参数量以及几百万的乘加计算量。在表11中,MobileNet相较于PlaNet只有少数准确率的下降,然而大幅度的优于Im2GPS。
4.5 人脸属性
另一个MobileNet的使用实例就是利用未知深奥的训练过程来压缩大型系统。在人脸属性分类任务中,我们证明了MobileNet与蒸馏(一种针对深层网络的知识转换理论)(Distilling the knowledge in a neural network)之间的协同关系。我们利用7500万参数以及16亿乘加运算计算量来约化一个大型人脸属性分类器。这个分类器在一个类似于YFCC100M数据集(Yfcc100m: The new data in multimedia research.)上的一个多属性数据集上训练。
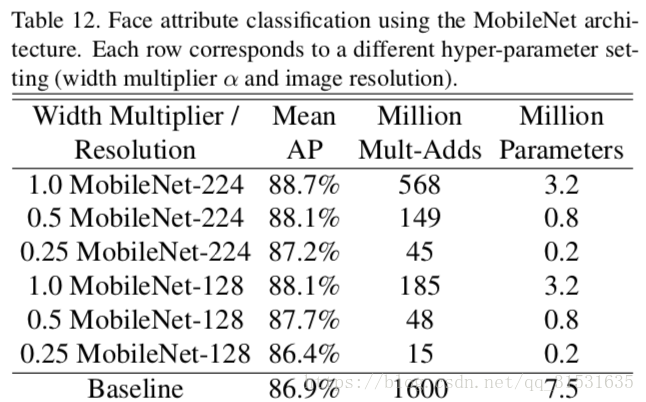
我们使用MobileNet结构提炼一个人脸属性分类器。通过训练分类器来蒸馏工作来模拟一个大型模型的输出,而不是真实的标签。因此能够训练非常大(接近无限)的未标记的数据集。结合蒸馏训练的可扩展性以及MobileNet的简约参数化,终端系统不仅要求正则化(权重衰减和早停),而且增强了性能。如表12中可以明显看到基于MobileNet-base分类器针对模型收缩更有弹性变化:它在跨属性间实现了一个相同的mAP但是只用了呀哪里1%的乘加运算。
4.6 目标检测
MobileNet也可以作为一个基本网络部署在现代目标检测系统中。我们在COCO数据集上训练得到结果并且赢得了2016COCO挑战赛。在表13中,MobileNet与VGG和InceptionV2在Faster-RCNN以及SSD(Ssd: Single shot multibox detector.)框架下进行比较。
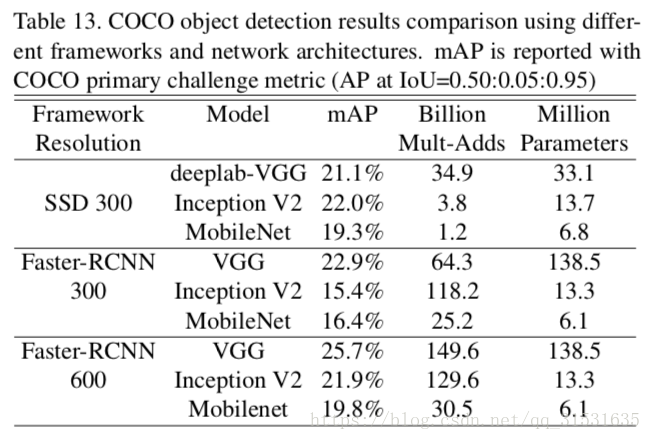
在我们的实验中,SSD由分辨率为300的输入图片进行检测,Faster-RCNN有300和600两种分辨率进行比较。Faster-RCNN模型每张图片测试了300RPN候选区域框,模型利用COCO的训练和验证集进行训练,包含了8000张微缩图片,并且在微缩图片中进行测试。对于上述框架,MobileNet与其他网络进行比较,计算复杂度和模型尺寸相当于其他模型的一小部分。
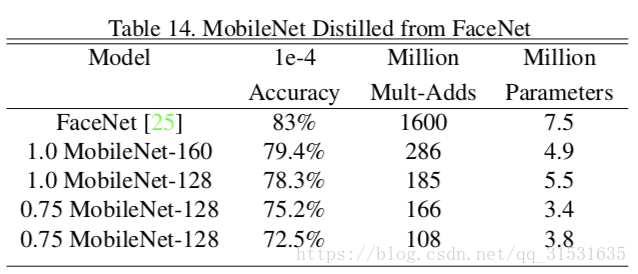
4.7 人脸嵌入
FaceNet是艺术人脸识别模型中最好的(Facenet: A uni- fied embedding for face recognition and clustering.)它构建了基于三次损失的人脸嵌入。为了构建移动端FaceNet模型,我们在训练集上通过最小化FaceNet和MobileNet之间的平方差来蒸馏训练。结果展示在表14中。
5 结论
我们提出了一个新的模型基于深度可分离卷积网络结构MobileNet。我们调研了一些重要的设计决策来引领一个有效的模型。然后我们描述了如何使用宽度乘法器和分辨率乘法器通过权衡准确率来减少尺寸和延迟来构建更小更快的MobileNets。然后将MobileNet与著名的模型在尺寸、速度和准确率上进行比较。我们总结了当MobileNet应用在各种任务中的有效性。下一步为了帮助探索MobileNets的更多改进和应用,我们计划在tensorflow中加入MobileNet。







