
前言
前面我们学习过,master节点的职责有:
- 负责决定当前某个分片要分配到哪个节点上面。
- 在节点间移动分片,保证集群的平衡。等等。
分片分配-基于集群配置
分片分配是指将分片分配到某个主机节点上的一个过程。触发的场景有:
- 初始化恢复
- 分片副本分配
- 集群平衡
- 集群节点加入或者移除
分片的分配,对整个es集群有重要的影响,所以,如何熟悉控制它,是一个很重要的知识点。es集群提供设置集群允许分配那种类型的分片,包括所有分片(默认)、主分片、新索引的主分片、禁止所有索引分配分片。这几个选项。
可能你会觉得奇怪,禁止分片分配,那还怎么玩?
存在即是合理的,这个属性在运维集群(滚动重启、需要维护集群,推迟分片分配)的时候用处很大,比如,在手动关闭掉一个节点后,集群会在固定的一个时间窗口后发现节点的丢失,并且开始数据平衡,这个操作在多个数据量较大的分片上平衡是相当的耗时的,所以在这种情况下,可以在集群级别上,先禁止索引分配分片,
维护完毕后,再设置回来。
小结:在你知道节点会从故障中很快恢复回来的时候,可以使用它来推迟副本分片的移动。

index.unassigned.node_left.delayed_timeout
会让你的集群在触发重新分配前有时间去检测节点是否会重新加入。
-
延迟分配不会阻止副本被提拔为主分片。集群会立马进行必要的提拔来让集群回到 yellow状态。缺失副本的重建是这个配置唯一能控制延迟的对象。
也就是说,这个delayed_timeout只对副本的重建起作用。 -
图中并没有提到的一点是,如果宕机的节点是Master节点,则集群会多一步【选主】动作,因为集群要想正常工作,必须得从Master候选节点(配置node.master: true)中选拔一个主节点出来。
阻止一个主机上运行多个实例
在CPU和内存资源富余的情况下,可能会使用一台主机启动多个实例的情况,这在一定程度上能充分利用资源,但同时也带来了风险。以一个主机启动两个实例为例。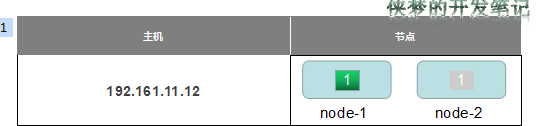
由图可知,192.161.11.12这台主机上部署了两个es实例,node-1和node-2。
假如此索引有1个副本,图上分片1和它的副本分别分片到了node-1、node-2。
在这种情况下,可用性是比较低的,如果这台主机宕机,
那么此索引的分片1数据就会全部丢失。
如何避免这种情况呢?当然就是避免在一主机上启动多个实例,
或者通过设置:cluster.routing.allocation.same_shard.host:true。
来强制阻止这种情况发生。
分片分配-基于磁盘感知
elasticsearch除了从集群整体层面考虑分片分配,同时也会考虑到可用磁盘空间等环境因素。
- elasticsearch在向某个主机的节点上分配分片时,会考虑其可用的磁盘空间。
disk.watermark.low代表着磁盘使用率的低水位线,默认85%,这个配置意味着,es不会将分片分配给超过这个值的节点,此设置对新创建的索引的主分片没有影响,但是会阻止分配它们的副本。
同理存在高水位线配置disk.watermark.high. 默认为90% ,这意味着Elasticsearch将尝试将分片从磁盘使用率超过90%的节点上分离出来,这个配置同样影响集群的平衡。
防止节点用完磁盘空间的最后手段的配置,disk.watermark.flood_stage,默认值95%,采用强制只读的方式来保护集群和主机。
机架感知
机架感知,让elasticsearch在分配分片时,考虑物理硬件配置。
感知物理硬件配置的好处是:当硬件出现问题时,比如物理机、或者同一机架,某一个机房出问题时,依靠物理感知,寻求一个最优的部署配置,最大程度的保证集群可用性。
不过单纯部署是无法让其得知对应的物理部署的,所以我们需要指定相关配置的值,来告诉es。具体配置方式有两种:
-
/bin/elasticsearch -Enode.attr.rack_id=rack_one` 启动时指定。
-
cluster.routing.allocation.awareness.attributes: rack_id 配置文件中指定。
-
es可以考虑将不同的节点配置到不同的物理机器上去。
-
不同的节点分配到不同的物理机架。
-
不同的节点分配到不同的网络区域中去。
CAP理论
机架感知需要考虑的情况(权衡可靠性、可用性、带宽消耗等各种情况)。
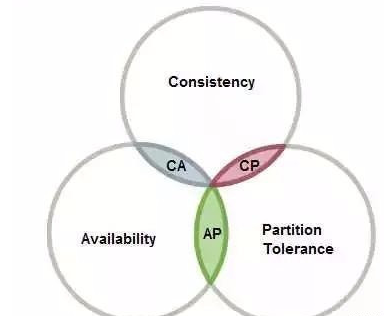
elasticsearch作为分布式的组件,CAP特性中的P(分区容错性)必须要考虑。
用通俗的语言来讲一下就是:我们知道,正常情况下es集群的各个节点应该都是互相连通的。
然而无论是环境还是人为因素影响,都可能造成节点的故障,此时网络可能会被分为几块区域。如果一个数据只在一个节点上保存,那么无法连通后,就再也访问不到这个数据了,这时我们说它是分区无法容忍的。
分片分配过滤
允许某些节点或某些节点组从分配中排除,以便将其停用。
这里的应用场景是:我们计划对节点进行停机下线的时候,可以避免新建的索引分片落到这个节点上。
总结
- elasticsearch的最小工作单元是分片,所以掌握分片在节点上的分配方式很重要,通过梳理,我们清楚了节点宕机后恢复对集群的影响。
- 基于磁盘感知的分片分配方式。
- 基于机架感知的分片分配方式。
- CAP理论中的p(分区容错性)简要理解。
- 排除节点,不分配分片,灵活下线节点。
本文由博客一文多发平台 OpenWrite 发布!





