
ES 基础
ES 集群
ES 集群上业务优化
一、ES 基础
ES 的安装下载,网上一大片,我这边不在重复。可以看看我以前做的小笔记:
其中 ES 三大要素:
文档(Document)
文档,在面向对象观念就是一个对象。在 ES 里面,是一个大 JSON 对象,是指定了唯一 ID 的最底层或者根对象。文档的位置由 _index、_type 和 _id 唯一标识。文档元数据:_index :文档在哪存放
_type : 文档表示的对象类别
_id :文档唯一标识
索引(Index)
索引,用于区分文档成组,即分到一组的文档集合。索引,用于存储文档和使文档可被搜索。比如项目索引命名为 project ,交易索引命名为 trade 等。类型(Type)
类型,用于区分索引中的文档,即在索引中对数据逻辑分区。比如设计项目分为 ui 、 ux 这些类型。可以放在该类目进行区分。但一般操作,很少用到这么复杂的。
可见, _index 索引的重要性。避免某个索引存储不相关的数据。
二、ES 集群
ES 集群搭建,文章很多。我这边也不一一列举了。先看 ES 集群分布式图
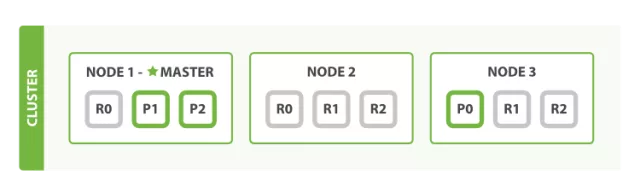
集群(Cluster)
跟服务器集群类似,多个 ElasticSearch 运行实例(节点 Node)的组合体是 ElasticSearch 集群。
ElasticSearch 是天然分布式的,可以通过水平扩容为集群添加更多节点。
ElasticSearch 集群是去中心化的,只有一个主节点(Master)。而且主节点是动态选举,因此不会出现单点故障。
那节点是什么?
节点(Node)
上面说过,一个 ElasticSearch 运行实例就是节点。任何节点都可以被选举成为主节点。主节点负责集群内所以变更,比如文档的增加、删除等。所以集群不会因为主节点流量的增大成为瓶颈。因为任何节点都会成为主节点。
如图,P1 P2 P0 是节点内的主分片,其他 R 是副分片。
那分片是什么?
分片(Shard)
分片,是 ES 节点中最小的工作单元。分片仅保存全部数据的一部分。分片包括主分片和副分片,主分片是副分片的拷贝。主分片和副分片基本没有大的区别。
如果是全文搜索,会查询到每个分片,然后将每个分片的结果进行全局地收集,并处理返回。
举个例子:比如新建了一个索引 project , 存储项目相关的数据。那具体的某个 project A 的数据会被切分,存储在不同的分片上。那么根据 project A 的 _id 如何路由到具体的分片上呢?
分片的路由公式是这样的:
shard = hash(routing) % number_of_primary_shards
hash 函数生成数字,经过取余算法得到余数。余数就是分片的位置。
routing 是可变值,支持自定义。默认文档 _id
number_of_primary_shards 主分片的数量
三、ES 集群上业务优化
倘若如果刚刚那个例子,一个索引 project , 存储项目相关的数据。项目的数量级越来越大,亿量级,万亿量级。那一个大索引的查询啥的都会出现瓶颈。这时候该怎么优化呢?
这时候是不是想到了,一句常说的:空间换时间。
这时候是不是也想到了,MySQL 分库
所以大索引的拆分,也不是很难。类似分片的路由规则,根据具体业务指定即可。
这里,我们可以定义 1000 个索引,分别名为 project_1、project_2、project_3…
然后在 ES 集群上面架一层简单的 proxy 。里面核心的业务路由规则可以这样:
index_id = project_id % 1000
project_id 项目自增 ID
index_id 得出来的索引对应的 ID
总结一张图: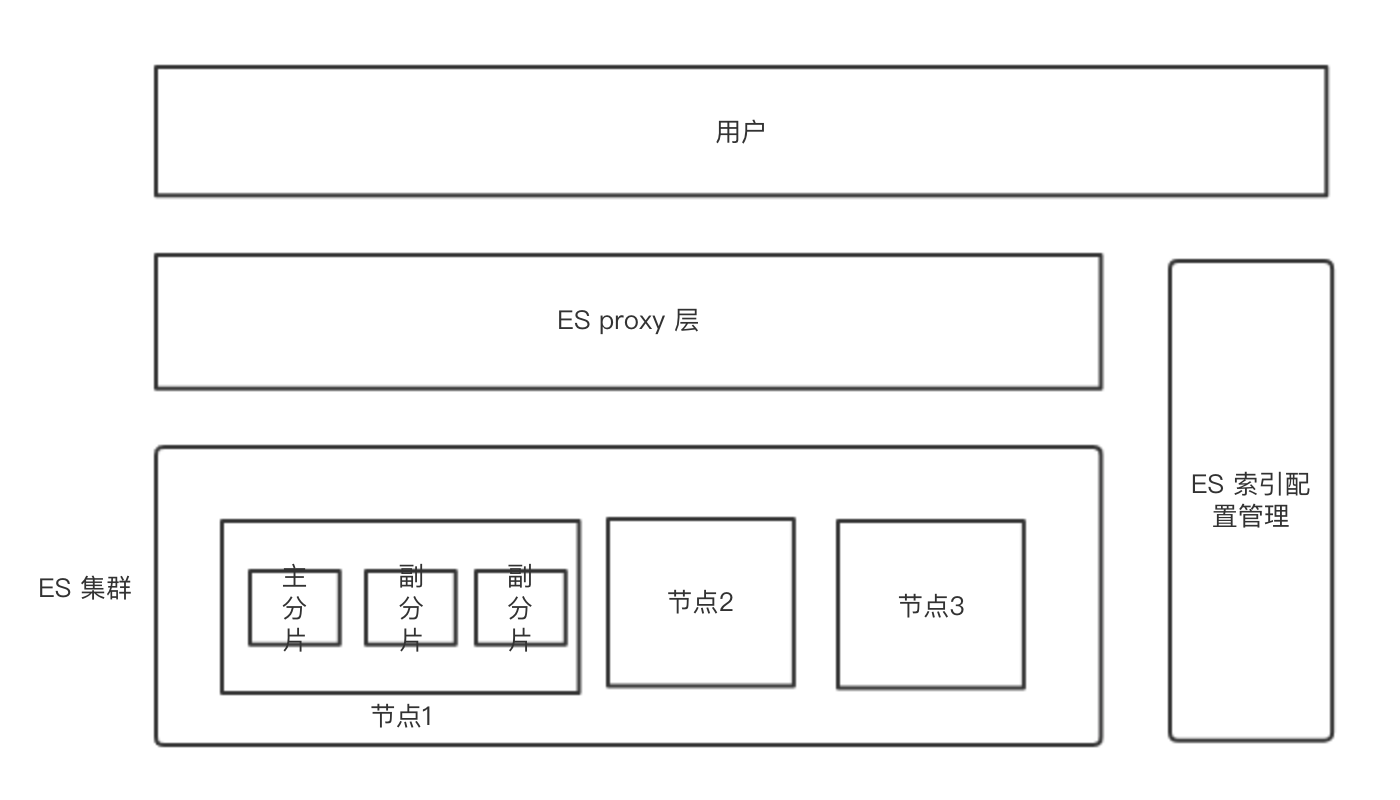
ES proxy 层:做总索引和真正分索引的映射
ES 索引配置管理:做索引与业务的映射
ES 集群:就是上面讲的
参考资料
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-index-field.html





