

▶ Export Metrics
1、Prerequisites
- NVIDIA Tesla drivers = R384+ (download from NVIDIA Driver Downloads page)
- nvidia-docker version > 2.0 (see how to install and it’s prerequisites)
- Optionally configure docker to set your default runtime to nvidia
- NVIDIA device plugin for Kubernetes (see how to install)
2、Create PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-gpu-pvc
namespace: kube-system
spec:
accessModes:
- ReadWriteMany
volumeMode: Filesystem
resources:
requests:
storage: 10Gi
3、Run DaementSet, Run Pod On GPU Node
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: prometheus-gpu
namespace: kube-system
spec:
revisionHistoryLimit: 3
selector:
matchLabels:
k8s-app: prometheus-gpu
template:
metadata:
labels:
k8s-app: prometheus-gpu
spec:
nodeSelector:
kubernetes.io/hostname: gpu
volumes:
- name: prometheus
persistentVolumeClaim:
claimName: prometheus-gpu-pvc
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
serviceAccountName: admin-user
containers:
- name: dcgm-exporter
image: "nvidia/dcgm-exporter"
volumeMounts:
- name: prometheus
mountPath: /run/prometheus/
imagePullPolicy: Always
securityContext:
runAsNonRoot: false
runAsUser: 0
env:
- name: DEPLOY_TIME
value: {{ ansible_date_time.iso8601 }}
- name: node-exporter
image: "quay.io/prometheus/node-exporter"
args:
- "--web.listen-address=0.0.0.0:9100"
- "--path.procfs=/host/proc"
- "--path.sysfs=/host/sys"
- "--collector.textfile.directory=/run/prometheus"
- "--no-collector.arp"
- "--no-collector.bcache"
- "--no-collector.bonding"
- "--no-collector.conntrack"
- "--no-collector.cpu"
- "--no-collector.diskstats"
- "--no-collector.edac"
- "--no-collector.entropy"
- "--no-collector.filefd"
- "--no-collector.filesystem"
- "--no-collector.hwmon"
- "--no-collector.infiniband"
- "--no-collector.ipvs"
- "--no-collector.loadavg"
- "--no-collector.mdadm"
- "--no-collector.meminfo"
- "--no-collector.netdev"
- "--no-collector.netstat"
- "--no-collector.nfs"
- "--no-collector.nfsd"
- "--no-collector.sockstat"
- "--no-collector.stat"
- "--no-collector.time"
- "--no-collector.timex"
- "--no-collector.uname"
- "--no-collector.vmstat"
- "--no-collector.wifi"
- "--no-collector.xfs"
- "--no-collector.zfs"
volumeMounts:
- name: prometheus
mountPath: /run/prometheus/
- name: proc
readOnly: true
mountPath: /host/proc
- name: sys
readOnly: true
mountPath: /host/sys
imagePullPolicy: Always
env:
- name: DEPLOY_TIME
value: {{ ansible_date_time.iso8601 }}
ports:
- containerPort: 9100
More info, please see https://github.com/NVIDIA/gpu-monitoring-tools
4、Create Service
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: prometheus-gpu
name: prometheus-gpu-service
namespace: kube-system
spec:
ports:
- port: 9100
targetPort: 9100
selector:
k8s-app: prometheus-gpu
5、Test Metrics
curl prometheus-gpu-service.kube-system:9100/metrics
then you will see some metrics like this:
# HELP dcgm_board_limit_violation Throttling duration due to board limit constraints (in us).
# TYPE dcgm_board_limit_violation counter
dcgm_board_limit_violation{gpu="0",uuid="GPU-a47ee51a-000c-0a26-77cb-6153ec8687b7"} 0
dcgm_board_limit_violation{gpu="1",uuid="GPU-0edfde45-1181-dc4f-947c-eab7c58c10d2"} 0
dcgm_board_limit_violation{gpu="2",uuid="GPU-973ac166-2c6a-12e1-d14d-968237a88104"} 0
dcgm_board_limit_violation{gpu="3",uuid="GPU-1a55c23a-b7d0-e93f-fea6-39c586c9e47b"} 0
# HELP dcgm_dec_utilization Decoder utilization (in %).
# TYPE dcgm_dec_utilization gauge
dcgm_dec_utilization{gpu="0",uuid="GPU-a47ee51a-000c-0a26-77cb-6153ec8687b7"} 0
dcgm_dec_utilization{gpu="1",uuid="GPU-0edfde45-1181-dc4f-947c-eab7c58c10d2"} 0
dcgm_dec_utilization{gpu="2",uuid="GPU-973ac166-2c6a-12e1-d14d-968237a88104"} 0
dcgm_dec_utilization{gpu="3",uuid="GPU-1a55c23a-b7d0-e93f-fea6-39c586c9e47b"} 0
.....
▶ Using Prometheus Collect Metrics
1、Create ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
data:
prometheus.yml: |
scrape_configs:
- job_name: 'gpu'
honor_labels: true
static_configs:
- targets: ['prometheus-gpu-service.kube-system:9100']
2、Create Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: kube-system
spec:
replicas: 1
revisionHistoryLimit: 3
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
spec:
volumes:
- name: prometheus
configMap:
name: prometheus-config
serviceAccountName: admin-user
containers:
- name: prometheus
image: "prom/prometheus:latest"
volumeMounts:
- name: prometheus
mountPath: /etc/prometheus/
imagePullPolicy: Always
ports:
- containerPort: 9090
protocol: TCP
3、Create Service
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: prometheus
name: prometheus-service
namespace: kube-system
spec:
ports:
- port: 9090
targetPort: 9090
selector:
k8s-app: prometheus
▶ Grafana Dashboard
1、Deploy grafana in your kubernetes cluster
kind: Deployment
apiVersion: apps/v1
metadata:
name: grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
k8s-app: grafana
template:
metadata:
labels:
k8s-app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:6.2.5
env:
- name: GF_SECURITY_ADMIN_PASSWORD
value: <your-password>
- name: GF_SECURITY_ADMIN_USER
value: <your-username>
ports:
- containerPort: 3000
protocol: TCP
2、Create Service Expose Your Grafana Service
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: grafana
name: grafana-service
namespace: kube-system
spec:
ports:
- port: 3000
targetPort: 3000
nodePort: 31111
selector:
k8s-app: grafana
type: NodePort
3、Access Grafana
grafana address may be http://:31111/ , username and password is that you config in step 1.
4、Add New DataSource
Click setting -> DateSource -> Add data source -> Prometheus. Config example:
- Name:
Prometheus - Default:
Yes - URL:
http://prometheus-service:9090 - Access:
Server - Http Method:
Get
Then click Save & Test. OK, you can access prometheus data now.
5、Custom GPU Monitoring Dashboard
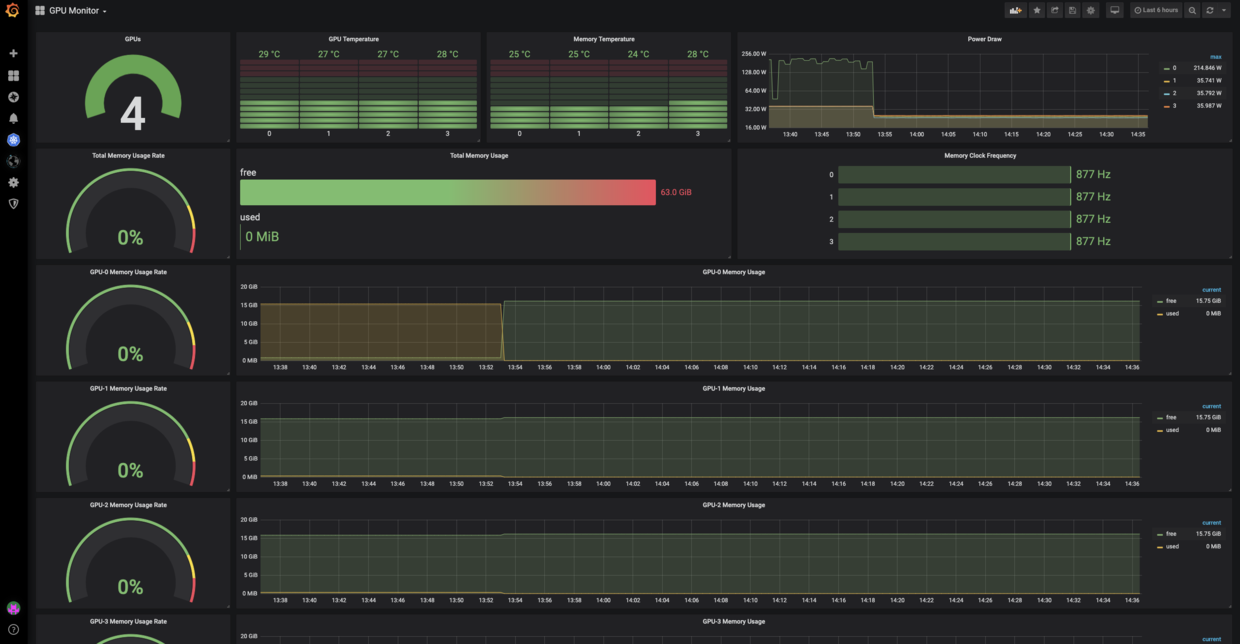
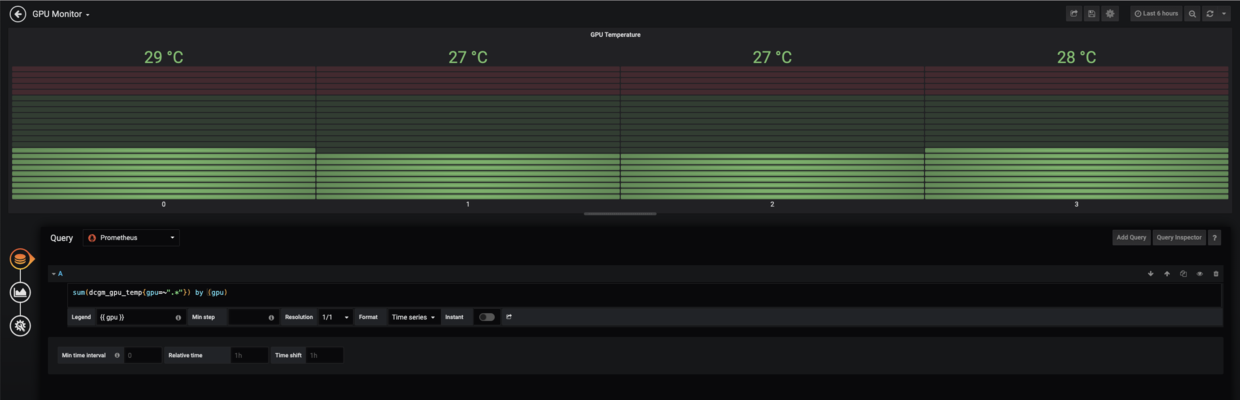
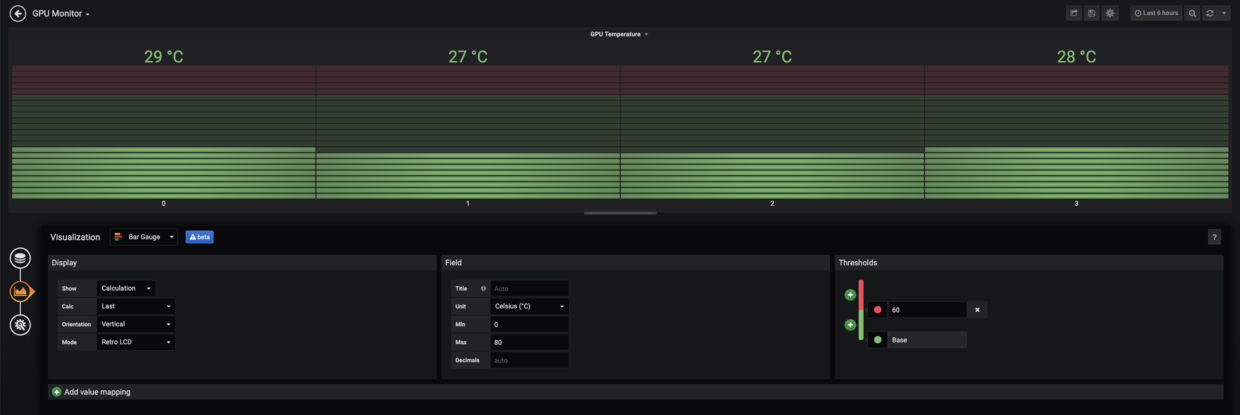
For example, Show GPU temperature:
# HELP dcgm_gpu_temp GPU temperature (in C).
# TYPE dcgm_gpu_temp gauge
dcgm_gpu_temp{gpu="0",uuid="GPU-a47ee51a-000c-0a26-77cb-6153ec8687b7"} 29
dcgm_gpu_temp{gpu="1",uuid="GPU-0edfde45-1181-dc4f-947c-eab7c58c10d2"} 27
dcgm_gpu_temp{gpu="2",uuid="GPU-973ac166-2c6a-12e1-d14d-968237a88104"} 27
dcgm_gpu_temp{gpu="3",uuid="GPU-1a55c23a-b7d0-e93f-fea6-39c586c9e47b"} 28
Get each gpu temperature by query sum(dcgm_gpu_temp{gpu=~".*"}) by (gpu)
extra query:
- gpu number:
count(dcgm_board_limit_violation) - total memory usage rate:
sum(dcgm_fb_used) / sum(sum(dcgm_fb_free) + sum(dcgm_fb_used)) - power draw:
sum(dcgm_power_usage{gpu=~".*"}) by (gpu) - memory temperature:
sum(dcgm_memory_temp{gpu=~".*"}) by (gpu)
本文由博客一文多发平台 OpenWrite 发布!





