

系统的数据,就是公司的生命。哪怕是狗屎,我们也要将它冷冻起来冰封以备后用。垃圾的产品设计就比较让人费解,会时不时从冰柜中将屎取出,想要品尝其中残留的味道。
不过这其中,还是有些有价值的需求。这种情况,就需要将数据进行冷热分离,对数据进行隔离。不至于让一颗老鼠屎,坏了一锅粥。
xjjdog今天给大家分享的,是一个非常常见的冷热分离的功能,方案有很多,只举例最常见的。
最终,在rds的限制下,只能选了一个不是最美的方案。这从侧面证明了老婆不是最漂亮的好,要最合适的才能幸福圆满。
问题场景
随着业务的发展,数据库增长的很快。老板不明白其中道理,但作为数据库的维护者,却看的胆颤心惊。
终于,数据库慢慢的接近数瓶颈点,管理员也越来越焦虑。
使用分区表吧,不行。就如上面所说,有些挖祖坟的请求,会加载一些很久之前的数据,分区表并不能解决问题。
明显要对数据进行一下切割,进行冷热分离了。
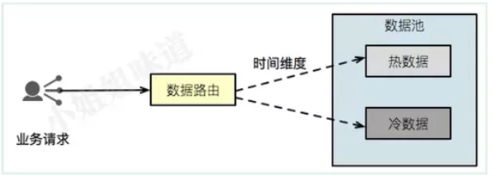
大体的结构如上图。我们有一个数据路由,负责根据时间维度区分数据,定位到相应的数据库中进行查询。
热库和冷库,可能是异构的。
解决思路
问题已经进行了转化。我们接下来的目标,变成了怎么根据时间维度,构建热数据和冷数据的分离。
目前使用最多的数据库是mysql,我们也从它说起。
其实,冷热分离的两份数据,查询“最近时间”的数据,是没什么差别的。唯一不同的是,热库,会定时的删除旧的数据。
双写
双写是最简单,但是又最不靠谱的方案。结构如下图。
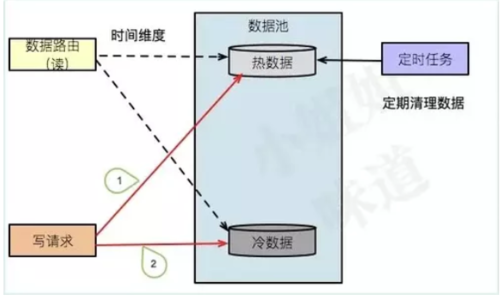
但是注意,操作步骤1、2,涉及到分布式事务,需要同时保证两个库的写入成功。
这就让事情变的麻烦了一些。作为一个吃过无数次事务问题的亏的人,不会重蹈这样的覆辙。
所以,这种方案,直接pass。
走消息
细心的同学应该发现了上图的优化点,通过引入一个叫做消息队列的东西,就可以把分布式事务这座大山给绕过去,只保证最终一致性即可。
多么美好的设想。理想很丰满,现实很骨感。由于冷热分离涉及到非常多的数据表,需要修改不可预知的业务代码,遭到了大家的一致反对。
此方案无疾而终。
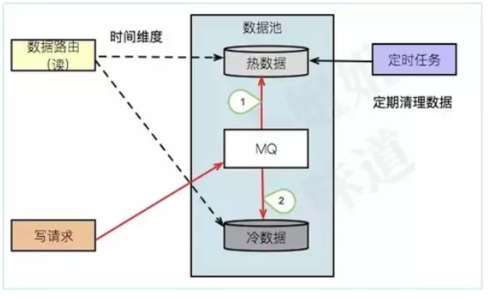
直接看图,变了两根线而已。
使用binlog
有的同学可能已经憋不住了:为什么不用binlog?接下来我们就谈下这种方案。
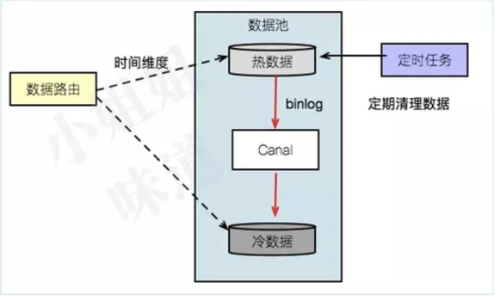
不可否认,这是种非常优雅的方式。数据只需要写入热库就可以了,通过数据订阅的方式,增量的将数据写入到冷库。
但是等等。我们的定时任务,删除数据的时候,同样也要产生binlog。如何区别数据的删除,是定时任务产生的,还是正常的业务产生?
还好,xjjdog知晓一个非常隐秘的方式去操作。
对对对,就是下面的过程。
set session sql_log_bin=0;
//opt
set session sql_log_bin=1;binlog可以设置session级别的,也就是在此session中操作的语句,并不会产生binlog。
这样,我们在定时任务执行时,先关闭binlog,然后,执行删除语句,然后,重新恢复binlog。这些删除的数据,就不会通过canal同步到冷库中了。
万万没想到

mmp?
为什么不支持呢?为什么呢?容我小心翼翼的猜想一下。你的rds啊,有可能在和别人在共用一个实例呢。
其实,除了rds的限制,此方案还存在一个bug。比如热库有冷热分离的时候。想想为甚么吧。
标记清除
得了,xjjdog只能曲线救国了。用最2的方式完成这个操蛋的功能。
标记清除。这四个醒目的大字,让人不由自主的想到jvm的垃圾回收算法。
原理其实也类似,步骤也是一分为二。
第一、标记阶段
给每一张数据表,都加一个叫做mark2Del字段。然后,通过定时,标记所有要过期(也就是要放入冷库的数据)。
第二、清除阶段
在下一次定时来临时,将上次标记要删除的数据,逐条搬迁到冷库。搬迁完毕后,进行下一轮标记。
此方案非常简单,但有个致命弱点。由于所有的库表,都是老表,都需要增加一个叫做mark2Del的字段,甚是麻烦。
然而,上面的介绍,只是解决了数据的删除,并没有解决数据的同步。
最终方案
结合以上的描述,以及环境的限制。我们选择了使用binlog+标记清除的方式。
标记清除负责删除数据。
binlog负责增量同步数据。只是,在这个同步逻辑中,多了一个判断,如果mark2Del的值被设置成了true,则忽略此binlog。
也就是说,我们强行给每条删除的记录,追加了一个判断标志。
这样,系统终于跑起来了。
End
上文描述的,是mysql到mysql之间的冷热分离。
但如果,我想要做一个分层的数据仓库。
第一层,是热库。
第二层,是冷库。
第三层,是存档库,可能是druid这种大数据存储。
该如何设计?
本文不做过多介绍。架构的难点不在结果,而在于过程。
你看起来很挫的方案,总有它背后的故事,尝试着去理解,大有裨益。
除非它是真的挫。不过,这不也是你的机会么?




