
没人会看的开场白:本来觉得自己从数据建模转人工智能方向应该问题不大(自我感觉自己算法学的不错)。结果一个K-邻近实现手写数字识别的代码就让我改了三四天。虽然网上这方面的代码是很多,但是我运行了好几个,结果都不是很理想。一次偶然的念想——为什么我不把这些代码的优点结合在一起呢,于是说做就做,年轻人嘛,反正有时间燥起来,再加上自己准备的毕业论文也是这个,动动手总有益处,于是就拙笔于此,有更好的建议与意见,欢迎指正。
开篇说明:内容很多,沉不下心,想速成的朋友请绕行,学习新知识嘛,坑要一个一个填实。打碎的骨头才更牢靠吧!
本篇所有的源码资源都已上传:https://download.csdn.net/download/zzz_cming/10377414
–—-—-—-—-—-—-—-—-—-—-—-—–—-—-—-—-—-—-—-——-—-—-—-—-—-—-—-—-—-—-—-—-—-——-
什么是K-近邻算法

百度百科上的定义:K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
K-近邻算法怎么应用于数字识别

实现过程直观点说:根据测试数据与每个训练集数据距离的大小来判断该测试数据分属哪个类别——我们有一堆已经注明好它是哪个数字的图片(这一堆图片组成训练集,也叫比较集、样本空间)。现在有一个测试数据“6”来了,我们要识别这个“6”的步骤就是:
(说明:左图是我用Windows自带的画图工具写的一个“6”,图片大小是28*28。右图是经过我切割、拉伸转化后的0-1矩阵图) 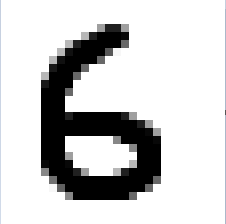

1. 将测试数据由图片形式转换成只有一列的0-1矩阵形式:上左图中有像素点的位置记为1,没有像素点的位置记为0,成上右图(上右图是经过我切割、拉伸后的结果)。再将上右图中所有后一行数字接到前一行末尾,形成一行,最后转置即可得一列0-1矩阵形式
2. 将所有(L个)训练数据也都用上方法从图片形式转换成只有一列的0-1矩阵形式
3. 把L个单列数据存入新矩阵A中——矩阵A每一列存储一个图片的所有信息
4. 用测试数据与矩阵A中的每一列求距离,求得的L个距离存入距离数组中(距离 = 对应位差值的平方和再求平方根)
5. 从距离数组中取出最小的K个距离所对应的训练集的索引
6. 拥有最多索引的值就是预测值(有多个众数时,按距离和最小)
三个KNN实现数字识别的方法
(说明:这是自己在网上看到的三个大神写的比较好的代码,前两个都能实现要求,后一个是预处理方法。我也只是站在大神的肩膀上做一点点修改,原理还是他们教的我,在此向他们表示致敬)
第一个:图片大小28*28,手写数字图片识别
来源说明:腾讯课堂米度教育《AI人工智能 机器学习 深度学习VIP实战就业班(人脸识别 无人驾驶)》第一节课。
献丑贴出自己的代码:
优化说明如下:(小修改未说明)
Pierre老师的代码中K值是等于1,即只选取与训练集数据最近的那个类。优化后成为可变的K,可自由选择最近的K个值进行比较
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing
# -*- 2017/12/25
# -*- python3.5
import numpy as np
from image import image2onebit as it
import sys
from tensorflow.examples.tutorials.mnist import input_data
import math
import datetime
#KNN算法主体:计算测试样本与每一个训练样本的距离
def get_index(train_data,test_data, i):
#1、 np.argmin(np.sqrt(np.sum(np.square(test_data[i]-train_data),axis=1)))
#2、a数组存入:测试样本与每一个训练样本的距离
all_dist = np.sqrt(np.sum(np.square(test_data[i]-train_data),axis=1)).tolist()
return all_dist
#KNN算法主体:计算查找最近的K个训练集所对应的预测值
def get_number(all_dist):
all_number = []
min_index = 0
#print('距离列表:', all_dist,)
for k in range(Nearest_Neighbor_number):
# 最小索引值 = 最小距离的下标编号
min_index = np.argmin(all_dist)
#依据最小索引值(最小距离的下标编号),映射查找到预测值
ss = np.argmax((train_label[min_index])).tolist()
print('第',k+1,'次预测值:',ss)
#将预测值改为字符串形式存入新元组bb中
all_number = all_number + list(str(ss))
#在距离数组中,将最小的距离值删去
min_number = min(all_dist)
xx = all_dist.index(min_number)
del all_dist[xx]
print('预测值总体结果:',all_number)
return all_number
#KNN算法主体:在K个预测值中,求众数,找到分属最多的那一类,输出
def get_min_number(all_number):
c = []
#将string转化为int,传入新列表c
for i in range(len(all_number)):
c.append(int(all_number[i]))
#求众数
new_number = np.array(c)
counts = np.bincount(new_number)
return np.argmax(counts)
t1 = datetime.datetime.now() #计时开始
print('说明:训练集数目取值范围在[0,60000],K取值最好<10\n' )
train_sum = int(input('输入训练集数目:'))
Nearest_Neighbor_number = int(input('选取最邻近的K个值,K='))
#依照文件名查找,读取训练与测试用的图片数据集
mnist = input_data.read_data_sets("./MNIST_data", one_hot=True)
#取出训练集数据、训练集标签
train_data, train_label = mnist.train.next_batch(train_sum)
#调用自创模块内函数read_image():依照路径传入图片处理,将图片信息转换成numpy.array类型
x1_tmp = it.read_image("png/55.png")
test_data = it.imageToArray(x1_tmp)
test_data = np.array(test_data)
#print('test_data',test_data)
#调用自创模块内函数show_ndarray():用字符矩阵打印图片
it.show_ndarray(test_data)
#KNN算法主体
all_dist = get_index(train_data,test_data,0)
all_number = get_number(all_dist)
min_number = get_min_number(all_number )
print('最后的预测值为:',min_number)
t2=datetime.datetime.now()
print('耗 时 = ',t2-t1)
评价:使用的训练集、测试集数据来源于Google的那个经典的压缩包。程序限制图片数据大小是28*28的,也就是说像素点一共784个,所以缺陷在于(应该说是KNN算法缺陷硬伤)
大多数数据图片占据的像素点很接近,距离区分度比较低;
未考虑不同数字间的内部结构特征
改善的方法有:
将图片尺寸扩大,但这样又会增加内存,使计算时间变长
规范的书写测试数据
增大训练数据集有效空间大小
这是我学习KNN算法做数字识别的启蒙物,再次感谢老师的帮助与指导
第二个:32*32,0-1字符矩阵的数字识别
来源说明:算法实现功能的大体步骤是不会变的,只是实现的方法各有不同。网上又看到的《Python 手写数字识别-knn算法应用》。虽然这位前辈一运用的是0-1字符矩阵,与之前Pierre老师的图片有不同,但是前辈一的代码更细致的展示出KNN算法实现的过程。源码链接地址:https://www.cnblogs.com/chenbjin/p/3869745.html
献丑再贴出自己的代码:
说明如下:大的优化没有,由于我有自己习惯的名称定义,修改了源代码中大部分的名称,小的修改也未注明
注意:代码中需要的训练集、测试集数据均来源于上链接里,为了让大家更清楚下面代码的原理,强烈建议看完上面前辈的作品。
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing
# -*- 2017/12/28
# -*- python3.5
from os import listdir
from numpy import *
import numpy as np
import operator
import datetime
def KNN(test_data,train_data,train_label,k):
#已知分类的数据集(训练集)的行数
dataSetSize = train_data.shape[0]
#求所有距离:先tile函数将输入点拓展成与训练集相同维数的矩阵,计算测试样本与每一个训练样本的距离
all_distances = np.sqrt(np.sum(np.square(tile(test_data,(dataSetSize,1))-train_data),axis=1))
#print("所有距离:",all_distances)
#按all_distances中元素进行升序排序后得到其对应索引的列表
sort_distance_index = all_distances.argsort()
#print("文件索引排序:",sort_distance_index)
#选择距离最小的k个点
classCount = {}
for i in range(k):
#返回最小距离的训练集的索引(预测值)
voteIlabel = train_label[sort_distance_index[i]]
#print('第',i+1,'次预测值',voteIlabel)
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#求众数:按classCount字典的第2个元素(即类别出现的次数)从大到小排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
#文本向量化 32x32 -> 1x1024
def img2vector(filename):
returnVect = []
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect.append(int(lineStr[j]))
return returnVect
#从文件名中解析分类数字
def classnumCut(fileName):
#参考文件名格式为:0_3.txt
fileStr = fileName.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
return classNumStr
#构建训练集数据向量,及对应分类标签向量
def trainingDataSet():
train_label = []
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
train_data = zeros((m,1024))
#获取训练集的标签
for i in range(m):
# fileNameStr:所有训练集文件名
fileNameStr = trainingFileList[i]
# 得到训练集索引
train_label.append(classnumCut(fileNameStr))
train_data[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
return train_label,train_data
#测试函数
def main():
t1 = datetime.datetime.now() # 计时开始
Nearest_Neighbor_number = int(input('选取最邻近的K个值,K='))
train_label,train_data = trainingDataSet()
testFileList = listdir('testDigits')
error_sum = 0
test_number = len(testFileList)
for i in range(test_number):
#测试集文件名
fileNameStr = testFileList[i]
#切片后得到测试集索引
classNumStr = classnumCut(fileNameStr)
test_data = img2vector('testDigits/%s' % fileNameStr)
#调用knn算法进行测试
classifierResult = KNN(test_data, train_data, train_label, Nearest_Neighbor_number)
print ("第",i+1,"组:","预测值:",classifierResult,"真实值:",classNumStr)
if (classifierResult != classNumStr):
error_sum += 1.0
print ("\n测试集总数为:",test_number)
print ("测试出错总数:",error_sum)
print ("\n错误率:",error_sum/float(test_number)*100,'%')
t2 = datetime.datetime.now()
print('耗 时 = ', t2 - t1)
if __name__ == "__main__":
main()
评价:这位前辈一所使用的训练集、测试集数据虽然是0-1矩阵,但是是可以通过代码生成打印出来。除此之外,前辈一代码的识别错误率比较低,测试时候946个测试数据只出错11个,出错率是1.16%,也就是成功率达98.84%。有图有真相:

大神一的方法也让我检验了最合适的K值选定是3(大家自己动手试试,选取不同的K值,就能得到不同的错误率)
于是用大神一的方法,再结合米度教育Pierre老师的代码,写了第一份自己的手写数字识别的代码(这里就没有贴出了)。问题总是在实际实现的过程中被发现——每个人用画板写出来的数字各不相同,形状有大有小,笔画有粗有细,就连同一个数字的结构比例都千差万别。这对识别的成功率影响很大。恰当这时,无意中发现了大神二的方法——统一不同人写出来的数字,也就是添加图片预处理,加入切割、拉伸函数。
第三个:图片预处理——切割、拉伸函数
大神二的原贴链接地址附上:http://m.blog.csdn.net/Hanpu_Liang/article/details/78237913
大神二的思路如下:
将读取的图片先转换成0-1矩阵形式
再根据灰度阈值,计算有效图片的边界索引,切割返回有效图片的索引尺寸
切割后的有效图片尺寸各不相同,运用拉伸函数将各不相同的有效图片转换成尺寸相同的有效图片
最后用转化后的同尺寸的训练集、测试集数据求距离,做预测

贴出自己的代码:注意图片存放的路径,标准大小N的值
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing
# -*- 2017/12/29
# -*- python3.5
from skimage import io
import numpy as np
import os
#Standard size 标准大小
N = 100
#灰度阈值
color = 100/255
#读取训练图片并保存
def GetTrainPicture(files):
Picture = np.zeros([len(files), N**2])
#enumerate函数用于遍历序列中的元素以及它们的下标(i是下标,item是元素信息)
for i, item in enumerate(files):
#读取这个图片并转为灰度值(黑死字体为0,白底为255)
img = io.imread('./png1/'+item, as_grey = True)
#清除噪音
img[img>color] = 1
#将图片进行切割,得到有手写数字的的图像
img = CutPicture(img)
#将图片进行拉伸,得到标准大小100x100
img = StretchPicture(img).reshape(N**2)
#将图片存入矩阵
Picture[i, 0:N**2] = img
#将图片的名字存入矩阵(需要存入名字,上面语句改Picture = np.zeros([len(files), N**2+1]))
#Picture[i, N**2] = float(item[0])
return Picture
#切割图象
def CutPicture(img):
#初始化新大小
size = []
#图片的行数
length = len(img)
#图片的列数
width = len(img[0,:])
#计算新大小
size.append(JudgeEdge(img, length, 0, [-1, -1]))
size.append(JudgeEdge(img, width, 1, [-1, -1]))
size = np.array(size).reshape(4)
#print('图像尺寸(高低左右):',size)
return img[size[0]:size[1]+1, size[2]:size[3]+1]
def JudgeEdge(img, length, flag, size):
for i in range(length):
#判断是行是列
if flag == 0:
#正序判断该行是否有手写数字
line1 = img[img[i,:]<color]
#倒序判断该行是否有手写数字
line2 = img[img[length-1-i,:]<color]
else:
line1 = img[img[:,i]<color]
line2 = img[img[:,length-1-i]<color]
#若有手写数字,即到达边界,记录下行
if len(line1)>=1 and size[0]==-1:
size[0] = i
if len(line2)>=1 and size[1]==-1:
size[1] = length-1-i
#若上下边界都得到,则跳出
if size[0]!=-1 and size[1]!=-1:
break
return size
#拉伸图像
def StretchPicture(img):
newImg = np.ones(N**2).reshape(N, N)
newImg1 = np.ones(N ** 2).reshape(N, N)
#对每一行/列进行拉伸/压缩
#每一行拉伸/压缩的步长
step1 = len(img[0])/N
#每一列拉伸/压缩的步长
step2 = len(img)/N
#对每一行进行操作
for i in range(len(img)):
for j in range(N):
newImg[i, j] = img[i, int(np.floor(j*step1))]
#对每一列进行操作
for i in range(N):
for j in range(N):
newImg1[j, i] = newImg[int(np.floor(j*step2)), i]
return newImg1
#用字符矩阵打印图片
def show_ndarray(pic):
for i in range(N**2):
if(pic[0,i] == 0):
print ("*",end='')
else:
print ("0",end='')
if (i+1)%N == 0 :
print()
#得到在num目录下所有文件的名称组成的列表
filenames = os.listdir(r"png1")
#得到所有训练图像向量的矩阵
pic = GetTrainPicture(filenames)
#print('图像向量的矩阵',pic)
#调用show_ndarray()函数:用字符矩阵打印图片
show_ndarray(pic)
N*N,手写数字识别(DIY版)
先来几点说明:
处理的图片大小要小于设定的N
测试集图片名称的首字母要是真实值
当前训练集库所包含的样本比较少,需多添加
代码如下:(具体的注释随代码附上)
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing
# -*- 2017/12/30
# -*- python3.5
import operator
import datetime
import numpy as np
from numpy import *
from os import listdir
from skimage import io
print('程序处理的图片大小,建议不要超过200*200\n')
N = int(input('需要处理的图片的大小(100至200),N='))
#N = 120 # 图片大小:N*N
color = 100 / 255 # 灰度阈值
#KNN算法主体
def KNN(test_data,train_data,train_label,k):
#已知分类的数据集(训练集)的行数
dataSetSize = train_data.shape[0]
#求所有距离:tile函数将输入点拓展成与训练集相同维数的矩阵,并计算测试样本与每一个训练样本的距离
all_distances = np.sqrt(np.sum(np.square(tile(test_data,(dataSetSize,1))-train_data),axis=1))
#按all_distances中元素进行升序排序后得到其对应索引的列表
sort_distance_index = all_distances.argsort()
#选择距离最小的k个点
all_predictive_value = {}
for i in range(k):
#返回最小距离的训练集的索引(预测值)
predictive_value = train_label[sort_distance_index[i]]
print('第',i+1,'次预测值',predictive_value)
all_predictive_value[predictive_value] = all_predictive_value.get(predictive_value,0)+1
#求众数:按classCount字典的第2个元素(即类别出现的次数)从大到小排序
sorted_class_count = sorted(all_predictive_value.items(), key = operator.itemgetter(1), reverse = True)
return sorted_class_count[0][0]
#训练集:得到训练集数据矩阵、下标签索引
def get_all_train_data():
train_label = []
train_file_list = listdir('trainlist') #获取目录内容
m = len(train_file_list) #m维向量的训练集
#get_train_data函数:得到所有训练集图像的向量矩阵
train_data = get_all_data(train_file_list,1)
for i in range(m):
file_name = train_file_list[i] #fileNameStr:所有训练集文件名
train_label.append(get_number_cut(file_name)) #得到训练集下标
return train_label,train_data
#得到所有训练集/测试集的向量矩阵(k=1训练集传入;k=0测试集传入)
def get_all_data(file_list,k):
train_data = np.zeros([len(file_list), N**2])
#enumerate函数用于遍历序列中的元素以及它们的下标(i是下标,item是元素信息)
for i, item in enumerate(file_list):
if k == 1:
#训练集:读取图片并转为灰度值(黑字体为0,白底为255)
img = io.imread('./trainlist/'+ item, as_grey = True)
else:
#测试集:读取图片并转为灰度值(黑字体为0,白底为255)
img = io.imread('./testlist/' + item, as_grey = True)
#降噪处理
img[img>color] = 1
#将图片进行切割,保留有值的部分
img = get_cut_picture(img)
#将图片进行拉伸,得到需求大小:N*N
img = get_stretch_picture(img).reshape(N**2)
#将处理后的图片信息存入矩阵
train_data[i, 0:N**2] = img
#若将图片的真实值存入矩阵(需要存入图片索引,上面语句改train_data = np.zeros([len(file_list), N**2+1])
#train_data[i, N**2] = float(item[0])
return train_data
#切割图象
def get_cut_picture(img):
#初始化新大小
size = []
#图片的行数
length = len(img)
#图片的列数
width = len(img[0,:])
#计算新大小
size.append(get_edge(img, length, 0, [-1, -1]))
size.append(get_edge(img, width, 1, [-1, -1]))
size = np.array(size).reshape(4)
#print('图像尺寸(高低左右):',size)
return img[size[0]:size[1]+1, size[2]:size[3]+1]
#获取切割边缘(高低左右的索引)
def get_edge(img, length, flag, size):
for i in range(length):
#判断是行是列
if flag == 0:
#正序判断该行是否有手写数字
line1 = img[img[i,:]<color]
#倒序判断该行是否有手写数字
line2 = img[img[length-1-i,:]<color]
else:
line1 = img[img[:,i]<color]
line2 = img[img[:,length-1-i]<color]
#若有手写数字,即到达边界,记录下行
if len(line1)>=1 and size[0]==-1:
size[0] = i
if len(line2)>=1 and size[1]==-1:
size[1] = length-1-i
#若上下边界都得到,则跳出
if size[0]!=-1 and size[1]!=-1:
break
return size
#拉伸图像
def get_stretch_picture(img):
newImg = np.ones(N**2).reshape(N, N)
newImg1 = np.ones(N ** 2).reshape(N, N)
#对每一行/列进行拉伸/压缩
#每一行拉伸/压缩的步长
step1 = len(img[0])/N
#每一列拉伸/压缩的步长
step2 = len(img)/N
#对每一行进行操作
for i in range(len(img)):
for j in range(N):
newImg[i, j] = img[i, int(np.floor(j*step1))]
#对每一列进行操作
for i in range(N):
for j in range(N):
newImg1[j, i] = newImg[int(np.floor(j*step2)), i]
return newImg1
#从文件名中分解出第一个数字(真实值)
def get_number_cut(file_name):
fileStr = file_name.split('.')[0] #文件名格式为:0_3.txt
classNumStr = int(fileStr.split('_')[0])
return classNumStr
#用字符矩阵打印图片
def get_show(test_data):
for i in range(N**2):
if(test_data[0,i] == 0):
print ("1",end='')
else:
print ("0",end='')
if (i+1)%N == 0 :
print()
def main():
t1 = datetime.datetime.now() # 计时开始
Nearest_Neighbor_number = int(input('选取最邻近的K个值(建议小于7),K='))
#训练集:get_train_data()函数得到训练集数据矩阵、下标签索引
train_label, train_data = get_all_train_data()
#测试集:根据路径,获取测试集地址
test_file_list = listdir('testlist')
file_name = test_file_list[0]
#测试集:运用切片函数,得到测试集下标索引(真实值)
test_index = get_number_cut(file_name)
#测试集:得到训练集图像的向量矩阵
test_data = get_all_data(test_file_list,0)
#测试集:get_show()函数:用字符矩阵打印图片
#get_show(test_data)
#调用knn算法进行测试
Result = KNN(test_data, train_data, train_label, Nearest_Neighbor_number)
print ("最终预测值为:",Result," 真实值:",test_index)
t2 = datetime.datetime.now()
print('耗 时 = ', t2 - t1)
if __name__ == "__main__":
main()
结果如下:

评价:效果看起来还马马虎虎了,但是对于那些书写不标准的,识别度还是较低,改善空间还是很大,欢迎大家相互指正,相互学习。
—-—-—-—-—-—-—-—-—-—-—-—–—-—-—-—-—-—-—-——-—-—-—-—-—-—-—-—-—-—-—-—-—-——-
这里还有一篇很好玩的实现方法,用到的是openCV
代码链接:http://blog.csdn.net/littlethunder/article/details/51615237
视频链接:http://www.bilibili.com/video/av4904541/
真心有意思
–—-—-—-—-—-—-—-—-—-—-—-—–—-—-—-—-—-—-—-——-—-—-—-—-—-—-—-—-—-—-—-—-—-——-
本篇所有的源码资源都已上传:https://download.csdn.net/download/zzz_cming/10377414
–—-—-—-—-—-—-—-—-—-—-—-—–—-—-—-—-—-—-—-——-—-—-—-—-—-—-—-—-—-—-—-—-—-——-
总结
KNN算法是一种比较简单的分类方法,人工智能入门级吧
KNN算法缺陷在于没有考虑不同数字间在结构特征上的差异





