
摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题。原始数据存在大量不完整、不一致、有异常的数据,严重影响到数据建模的执行效率,甚至可能导致模型结果的偏差,因此要数据预处。数据预处理主要是将原始数据经过文本抽取、数据清理、数据集成、数据处理、数据变换、数据降维等处理后,不仅提高了数据质量,而且更好的提升算法模型性能。数据预处理在数据挖掘、自然语言处理、机器学习、深度学习算法中起着重要的作用。(本文原创,转载必须注明出处.)
1 什么是数据预处理
数据预处理简而言之就是将原始数据装进一个预处理的黑匣子之后,产生出高质量数据用来适应相关技术或者算法模型。为了大家更明确的了解数据预处理,我们举个新闻分类的例子:
将原始的数据直接进行分类模型训练,分类器准确率和召回率都比较低。因为我们原始数据存在很多干扰项,比如
的,是等这些所谓停用词特征对分类起的作用不大,很难达到工程应用。我们将原始数据放假预处理黑匣子后,会自动过滤掉干扰数据,并且还会按照规约的方法体现每个词特征的重要性,然后将词特征压缩变换在数值型矩阵中,再通过分类器就会取得不错的效果,可以进行工程应用。
总结:数据预处理前的数据存在不完整、偏态、噪声、特征比重、特征维度、缺失值、错误值等问题;数据预处理后的数据存在完整、正态、干净、特征比重合适、特征维度合理、无缺失值等优点。
数据预处理方法:
数据清理:通过填写缺失的值、光滑噪声数据、识别或删除离群点并解决不一致性来清理数据。主要目标:格式标准化,异常数据清除,错误纠正,重复数据的清除。
数据集成:将数据由多个数据源合并成一个一致的数据存储,如数据仓库。
数据变换:通过平滑聚集,数据概化,规范化等方式将数据转换成适用于的形式。如把数据压缩到0.0-1.0区间。
数据归约:往往数据量非常大,在少量数据上进行挖掘分析需要很长的时间,数据归约技术可以用来得到数据集的归约表示,它小得多,但仍然接近于保持原数据的完整性,并结果与归约前结果相同或几乎相同。可以通过如聚集、删除冗余特征或聚类来降低数据的规模。
2 为什么做这门课程
在初期学习阶段,大家精力着重于算法模型和调参上。实际情况是,有时候在算法改进上花费很多功夫,却不如在数据质量上的些许提高来的明显。另外,习惯于数据语料的拿来主义之后,当面对新的任务时候,却不知道如何下手?有的同学在处理英语时候游刃有余,面对中文数据预处理却不知所措。基于以上几个问题,结合作者工程经验,整理出了‘数据预处理’学习资料,本教程主要面对文本信息处理,在图片语音等数据语料处理上是有所区别的。
3 本课程能学到什么
文本批量抽取:涉及技术点包括pywin32插件安装使用、文档文本提取、PDF文本提取、文本抽取器的封装、方法参数的使用、遍历文件夹、编码问题、批量抽取文本信息。
数据清洗:包括yield生成器、高效读取文件、正则表达式的使用、清洗网页数据、清洗字符串、中文的繁简互相转换、缺失值的处理、噪声数据、异常数据清洗、批量清洗30万条新闻数据。
数据处理:包括结巴分词精讲、HanLP精讲、停用词的处理、NLTK的安装使用、高频词和低频词的处理、词性的选择、特征数据的提取、批量预处理30万条新闻数据。
数据向量化:包括词袋模型、词集模型、词向量的转化、缺失值和数据均衡、语料库技术、TFIDF、特征词比重、主成分分析、主题模型等、批量进行30万条数据向量化。
可视化技术:包括条形图、柱形图、散点图、饼图、热力图等,还有matplotlib、seabom、Axes3D综合使用进行三维可视化。
XGBoost竞赛神器:包括监督学习、文本分类、XGBoost原理、XGBoost算法实现、XGBoost调参、算法性能评估、30万条文档生成词典、30万条文档转化TFIDF、30万条文档转化生成LSI、训练分类器模型、抽样改进模型算法、特征维度改进模型算法、XGBoost实现30万条新闻数据文本分类
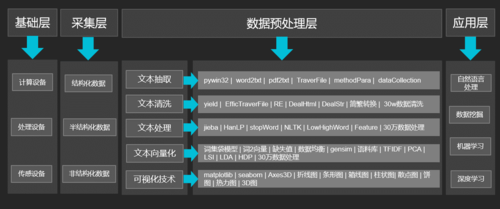
综上所述:数据预处理整体包括数据抽取-->数据清洗-->数据处理-->数据向量化-->可视化分析-->模型构建。在整个过程中,我们每个章节相关性很强,首先对整个章节最终实现效果进行演示,然后拆分知识点分别讲解,最后将所有知识点整合起来做小节的实战。每个小节实战数据为下一个章节做铺垫,最后,一个综合实战分类案例串联所有知识点。
4 开发环境说明
开发语言: Python3.5.3
系统环境:window10操作系统
编程环境:Sublime
软件环境:Anaconda4.4.0
插件版本:均支持最新版本
sublime激活:打开Help >Enter LICENSE
----- BEGIN LICENSE -----sgbteamSingle User LicenseEA7E-11532598891CBB9 F1513E4F 1A3405C1 A865D53F115F202E 7B91AB2D 0D2A40ED 352B269B76E84F0B CD69BFC7 59F2DFEF E267328F215652A3 E88F9D8F 4C38E3BA 5B2DAAE4969624E7 DC9CD4D5 717FB40C 1B9738CF20B3C4F1 E917B5B3 87C38D9C ACCE7DD85F7EF854 86B9743C FADC04AA FB0DA5C0F913BE58 42FEA319 F954EFDD AE881E0B------ END LICENSE ------ |
解决Package Control报错:Package Control.sublime-settings]修改方法:Preferences > Package Settings > Package Control > Settings - User 添加:
"channels": [ "http://cst.stu.126.net/u/json/cms/channel_v3.json", //"https://packagecontrol.io/channel_v3.json", //"https://web.archive.org/web/20160103232808/https://packagecontrol.io/channel_v3.json", //"https://gist.githubusercontent.com/nick1m/660ed046a096dae0b0ab/raw/e6e9e23a0bb48b44537f61025fbc359f8d586eb4/channel_v3.json" ] |
5 项目演示
5.1 原始数据

5.2 数据预览

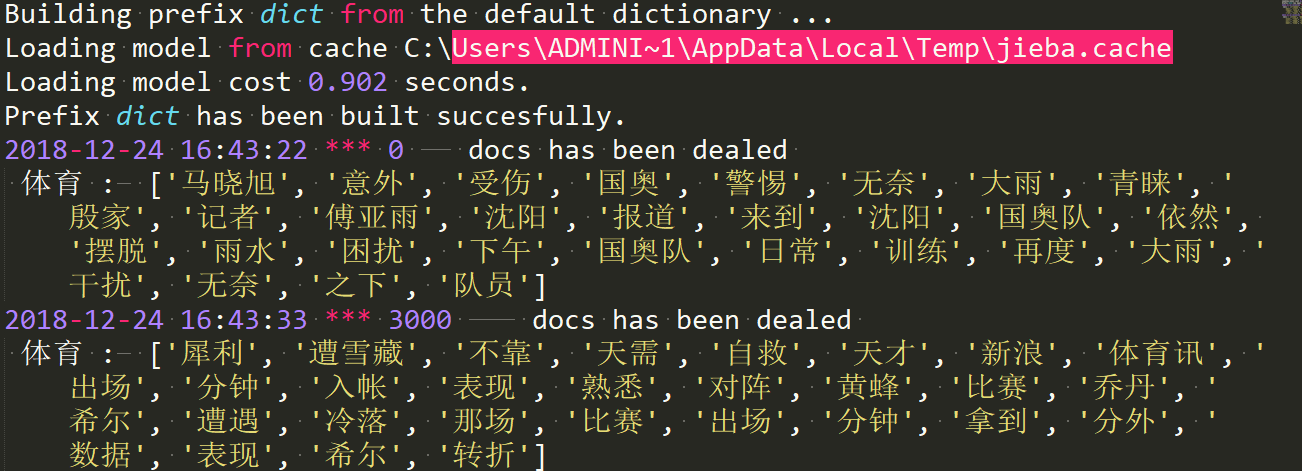
5.3 数据清洗

5.4 生成词典
5.5 生成特征向量

5.6 生成LSI
5.7 XGBoost新闻数据文本分类






