
基于OpenCV和Keras的人脸识别系列手记:
项目完整代码参见Github仓库。
项目完整代码参见Github仓库。
本篇手记是上面这一系列的第七篇。
在系列的上一篇手记里,我完成了将图片转化为128维特征向量的工作,这篇要用这些128维特征向量的数据来训练一个KNN模型。
KNN算法的基本思想
先来看看KNN算法的基本思想,KNN是K nearest neighbor的缩写,中文名称是k-近邻算法。一开始学习这个算法,我是通过斯坦福的计算机视觉课程cs231n,里面有一节专门介绍了KNN算法并且还有配套的编程作业,学过以后我觉得KNN算法就是对需要预测的数据,将其与所有训练数据比较,得到训练数据中k个距离(通常是欧氏距离)预测数据最近的样本,统计其分类,最后将k个样本中占最多数的分类作为对预测数据的分类预测。KNN算法中,k值是一个需要调整的超参数。
如果说上面的通用描述还比较抽象,不好理解,我来把它引申到这个人脸识别项目里:假如现在摄像头实时探测到一张人脸,先计算这张人脸图像和我之前准备的两千多张人脸图像128维特征向量的欧氏距离,就会得到两千多个欧氏距离,假设k取7,在这两千多个欧氏距离里取7个最小的,如果其中有四个以上欧氏距离所对应的分类标签都是“我”,那么就预测这张探测到的人脸就是我。
可以看到,KNN算法的思想很简单,也确实是所有机器学习算法里最简单的之一,不过,我在实际使用的时候发现还是有许多细节需要注意。下面就来讲解我是如何实现用KNN算法识别人脸的。
scikit-learn
在这个项目里,我是用scikit-learn这个基于Python的机器学习库来实现KNN算法的,scikit-learn覆盖了数据集的加载、预处理,模型的建立、训练、预测和持久化以及性能评估等机器学习的完整流程,利用scikit-learn能很方便地实现KNN、SVM等机器学习常用算法。
Holdout验证与K折交叉验证
Facenet+KNN方案整体的思路其实和利用人脸数据训练一个简单的神经网络模型里类似,只是训练数据由人脸图片变成了经过Facenet提取的128维人脸特征,最终的预测模型由CNN变成了KNN,然后值得一提的一个不同就是我在这里使用了K折交叉验证。
继续抽象的理论之前还是先上一些代码,首先是建立一个KNN模型的类,用来建立、训练、测试和持久化KNN模型:
class Knn_Model:
# 初始化构造方法
def __init__(self):
self.model = None
在系列前一篇手记的最后我提到了,在准备训练数据的时候我没有像之前用简单CNN的方案中那样,将准备好的训练数据随机按70%/30%的比例划分为训练集和测试集,这种一部分数据集用于训练,一部分数据集用于测试的方式叫做Holdout验证,由于训练数据和测试数据并没有交叉使用,这种验证方式并不能算是交叉验证。一开始训练KNN模型的时候我是沿用了Holdout验证,将Facenet提取的128维人脸特征七比三随机划分为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X_embedding, labels, test_size = 0.3, random_state = random.randint(0, 100))
上面train_test_split方法的random_state参数的值是一个0到100之间的随机整数,因此每次运行程序时数据的划分都不一样,我在实际运行程序的时候发现,有的时候KNN模型的测试准确率能达到90%+,有的时候只有80%+。虽然最后实际运行人脸识别程序的时候效果差不多,但是在训练一个模型的时候,我肯定希望准确率越高越好,因此,我改用了K折交叉验证:
K次交叉验证,将训练集分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10次交叉验证是最常用的。
在K折交叉验证里,由于训练数据和测试数据交叉使用,最终的结果会更稳定、准确,受数据划分的影响也大大减小。
下面在Knn_Model类里定义一个cross_val_and_build_model方法用来实现K折交叉验证并选择最佳的模型(超参数k):
def cross_val_and_build_model(self, dataset):
k_range = range(1,31)
# k_range = range(1,60)
k_scores = []
print("k vs accuracy:")
for k in k_range:
knn = KNeighborsClassifier(n_neighbors = k)
# cv = KFold(n_splits = 10, shuffle = True, random_state = 0)
# https://github.com/scikit-learn/scikit-learn/issues/6361
# http://scikit-learn.org/stable/modules/cross_validation.html#computing-cross-validated-metrics
# cv = ShuffleSplit(random_state = 0) # n_splits : int, default 10; test_size : float, int, None, default=0.1,设置了random_state = 0,每次的数据划分相同,训练结果也相同
score = cross_val_score(knn, dataset.X_train, dataset.y_train, cv = 10, scoring = 'accuracy').mean() # cv参数取整数的时候默认用KFold方法划分数据,这里两次运行的结果一样,可能说明KFold里的random_state参数设为了整数
# score = cross_val_score(knn, dataset.X_train, dataset.y_train, cv = cv, scoring = 'accuracy').mean() # numpy.ndarray.mean
k_scores.append(score)
print(k, ":", score)
# 可视化结果
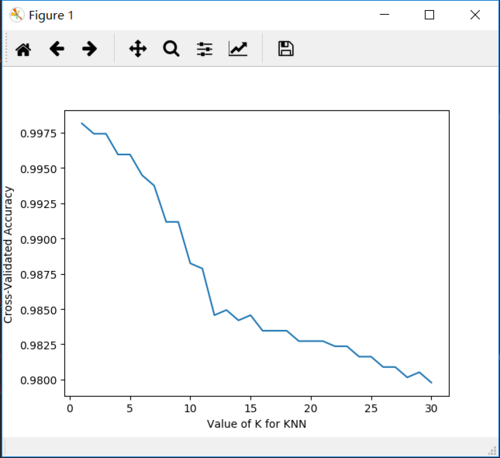
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
n_neighbors_max = np.argmax(k_scores) + 1
print("The best k is: ", n_neighbors_max)
print("The accuracy is: ", k_scores[n_neighbors_max - 1], "When n_neighbor is: ", n_neighbors_max)
self.model = KNeighborsClassifier(n_neighbors = n_neighbors_max)
# 目前k=1时最佳,准确率达到88%+,可能原因参考https://stackoverflow.com/questions/36637112/why-does-k-1-in-knn-give-the-best-accuracy
# Data tests have high similarity with the training data; The boundaries between classes are very clear
# In general, the value of k may reduce the effect of noise on the classification, but makes the boundaries between each classification becomes more blurred.
# 使用shuffle后准确率显著提升,k=1时达到98.9%+,我理解的是shuffle后训练集和测试集的数据类别分布更均衡,shuffle前可能数据的类别分布不均衡,导致准确率较低。
在上面的代码里,我在k=1到30的范围内对KNN模型进行了10折交叉验证,实现交叉验证的方法是cross_val_score,值得一提的是其中的cv参数,这个参数决定了交叉验证中数据划分的策略,因为要用10折交叉验证,所以可以直接取10。
迭代改进的过程
上面讲的还是比较抽象,下面看看我实际运行程序迭代、改进的过程,实际中我并不是先了解了全部理论再建立一个完美的KNN模型,而是在发现模型准确率不够高的情况下去探究是什么因素影响了准确率,然后再尝试改进,最后再总结影响KNN模型准确率的因素。
先在face_knn_classifier.py的最后添加如下代码:
if __name__ == "__main__":
dataset = Dataset('./dataset/')
dataset.load()
model = Knn_Model()
model.cross_val_and_build_model(dataset)
一开始我没有对Facenet提取的128维人脸特征进行L2_normalization操作,也就是在img_to_encoding函数(详见用Facenet模型提取人脸特征篇)里没有下面这一段代码:
embedding = embedding / np.linalg.norm(embedding, axis = 1, keepdims = True)
此时运行face_knn_classifier.py,得到结果:
Number of classes: 2
Number of the sample of class 0 : 938
Number of the sample of class 1 : 1311
X_train shape (2249, 128)
y_train shape (2249,)
2249 train samples
k vs accuracy:
1 : 0.8816841726366063
2 : 0.8158664313808119
3 : 0.8425431240342747
4 : 0.7834138748419723
5 : 0.8069774195814018
6 : 0.7674197043124035
7 : 0.7803165472678748
8 : 0.7505386641382216
9 : 0.7629752247506671
10 : 0.7327449431099874
11 : 0.7438541578873438
12 : 0.7162984443039753
13 : 0.7274096256496699
14 : 0.7034035679168422
15 : 0.7118480825958702
16 : 0.6914015662312122
17 : 0.7007310015451609
18 : 0.6869531184155078
19 : 0.6949590883551061
20 : 0.6762903673268718
21 : 0.6860681802219412
22 : 0.6700739745750808
23 : 0.6762922987779183
24 : 0.6660779252704032
25 : 0.6705223872734934
26 : 0.6598536662452591
27 : 0.6669667790420004
28 : 0.6545242836072482
29 : 0.6598596010675657
30 : 0.6518536486866132
The best k is: 1
The accuracy is: 0.8816841726366063 When n_neighbor is: 1

可以看到,没有对128维人脸特征进行L2_normalization操作的时候KNN模型的准确率比较低,k=1的时候最高也只有88%+,显然不够好。L2_normalization是对128维特征向量取L2范数,然后在128维的每一维上都除以L2范数。下面我加上这一步,也就是在img_to_encoding函数里加上:
embedding = embedding / np.linalg.norm(embedding, axis = 1, keepdims = True)
再次运行face_knn_classifier.py,得到结果如下:
Number of classes: 2
Number of the sample of class 0 : 938
Number of the sample of class 1 : 1311
X_train shape (2249, 128)
y_train shape (2249,)
2249 train samples
k vs accuracy:
1 : 0.9719781043685911
2 : 0.9617538277848012
3 : 0.967523739289226
4 : 0.9590832104228122
5 : 0.9648629723275739
6 : 0.9573014643910662
7 : 0.9608609882005901
8 : 0.9541843833403567
9 : 0.9586367818513837
10 : 0.953295494451468
11 : 0.9568491009973309
12 : 0.9532915437561454
13 : 0.9559641803624104
14 : 0.947956243854474
15 : 0.9515177517909817
16 : 0.9466209088355105
17 : 0.947956243854474
18 : 0.9412836248068551
19 : 0.9439503090321676
20 : 0.9394998946481248
21 : 0.9399463232195533
22 : 0.9372756882989183
23 : 0.9394999122067705
24 : 0.9368292597274896
25 : 0.9372737041719341
26 : 0.9354939422671723
27 : 0.9363848152830455
28 : 0.9323808470290771
29 : 0.9359423549655851
30 : 0.933269735917966
The best k is: 1
The accuracy is: 0.9719781043685911 When n_neighbor is: 1

可以看到模型的准确率有显著提升,k=1的时候最高达到了97%+。
为什么L2_normalization会对结果有这么显著的提升呢?
因为我所用的KNN算法在预测人脸的时候是比较两个人脸128维特征向量的欧氏距离,也就是每个维度分别计算平方差再求和再开根号,假如不同维特征值的取值范围差别很大,比如维度一特征值的范围是±100,而其他维度只有±1,那计算距离的时候维度一的特征值就对结果影响很大,而其他维度的特征值则几乎不起作用,这显然不是我们所希望的,也会对准确率造成影响。关于这个问题更具体的例子可以参考一文搞懂k近邻(k-NN)算法(一)
要解决这个问题就要对数据进行归一化,将不同维度的数据缩放到相近的范围内(通常是0~1).L2_normalization其实是一种归一化的方式,常用的归一化方式还有线性归一化(Min-Max scaling) 和 0均值标准化(Z-score standardization), 因为这个项目里暂时没有用到,就不详细介绍,感兴趣可以参考KNN算法的算法思想。
现在这个KNN模型的准确率达到了达到了97%+,看起来已经很不错了,那是不是就不能再提升了呢?
不是的,接下来我要在数据划分的时候对数据增加一步随机打散的操作,之前cross_val_score方法里的cv参数是直接取10,这次我自己设一个交叉验证生成器对象:
cv = ShuffleSplit(random_state = 0)
ShuffleSplit方法用于生成随机打乱的数据划分,这里我省略了一个参数n_splits,表示划分的份数,默认是10,也就是10折交叉验证。
再次运行face_knn_classifier.py,得到结果如下:
Number of classes: 2
Number of the sample of class 0 : 938
Number of the sample of class 1 : 1311
X_train shape (2249, 128)
y_train shape (2249,)
2249 train samples
k vs accuracy:
1 : 0.9897777777777778
2 : 0.9826666666666666
3 : 0.9853333333333334
4 : 0.9791111111111113
5 : 0.9813333333333334
6 : 0.976
7 : 0.9782222222222223
8 : 0.9764444444444444
9 : 0.9782222222222223
10 : 0.9764444444444444
11 : 0.9777777777777779
12 : 0.9751111111111112
13 : 0.9751111111111112
14 : 0.9737777777777776
15 : 0.9742222222222221
16 : 0.9720000000000001
17 : 0.9742222222222221
18 : 0.9733333333333333
19 : 0.9746666666666666
20 : 0.9728888888888887
21 : 0.9737777777777776
22 : 0.9728888888888887
23 : 0.9742222222222221
24 : 0.9706666666666667
25 : 0.9724444444444444
26 : 0.9693333333333334
27 : 0.9706666666666666
28 : 0.9688888888888888
29 : 0.9697777777777776
30 : 0.968
The best k is: 1
The accuracy is: 0.9897777777777778 When n_neighbor is: 1

可以看到,k=1时最高准确率接近99%,比之前又有了几个百分比的提升,这又是为什么呢?
在load_dataset函数里我是按类别的顺序读取图片数据的,如果在数据划分的时候不对数据增加一步随机打散的操作,很可能出现在测试集或者训练集中某一类数据远高于其他类数据,比如在测试集中,“我”的人脸远多于其他人脸。之所以要在数据划分的时候对数据进行shuffle操作,目的是为了让交叉验证中的训练集和测试集的数据类别分布更平衡。
在最开始讲解KNN算法的原理的时候已经说过了,KNN预测的时候是在训练集里选取k个距离预测样本最近的样本,然后进行投票,取k个样本中占最多数的类别作为预测的类别,假如由于样本分布不平衡导致在k个样本中错误的类别占到了最多数,就会导致预测错误,因此,样本分布越不平衡,KNN的预测错误率就可能越高,这也是KNN算法的一个特点,就是对样本平衡度的依赖较高。
这个项目里shuffle操作提升了几个百分比的准确率,看起来效果不是太明显,个人感觉可能是因为搜集的数据类别分布还比较平衡(938:1311),然后10折交叉验证也压缩了数据随机划分导致的数据类别分布不平衡,但不管怎样,shuffle操作还是很有必要的,应该作为机器学习问题标准流程中的一环。
最终,我的KNN模型准确率达到了将近99%,k的最佳值取1,这可能是因为我的两类人脸数据——“我”和“其他人”——之间的区分还是比较明显,也就是说Facenet提取的人脸特征效果不错。
建立最佳模型并持久化
得到了效果最佳的模型,接着就把模型保存下来,在Knn_Model这个类里再定义几个函数:
def train(self, dataset):
self.model.fit(dataset.X_train, dataset.y_train)
def save_model(self, file_path):
#save model
joblib.dump(self.model, file_path)
def load_model(self, file_path):
self.model = joblib.load(file_path)
注意KNN的train方法只要让得到的最佳模型把训练数据记下来即可,save_model和load_model限于篇幅就不再详细讲解了。
最后再定义一个predict方法作为接口供实时人脸识别程序调用:
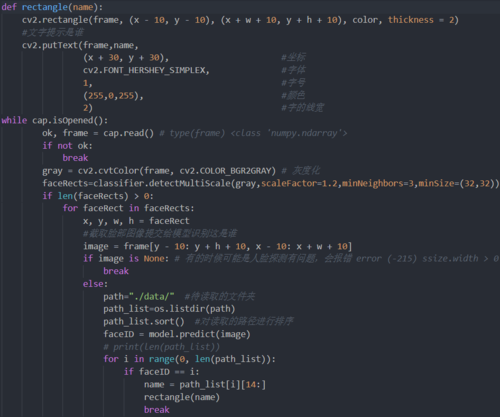
def predict(self, image):
image = resize_image(image)
image_embedding = img_to_encoding(np.array([image]), facenet)
label = self.model.predict(image_embedding) # predict方法返回值是array of shape [n_samples],因此下面要用label[0]从array中取得数值,https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier.predict
return label[0]
后续的实时人脸识别程序和之前的基本相同,只需把其中的face_predict换成predict即可。
我运行实时人脸识别的时候也基本达到了和之前差不多的效果,识别准确率还是很高的,不过也不是100%的准确,有的时候当女朋友离镜头较远的时候也能探测到她的人脸,会错误识别成我,后续考虑收集她离镜头较远的人脸数据继续训练或者对人脸做其他处理等。
总结
唔,这篇好长,能看到这里的童鞋一定是对这个项目有点兴趣吧,这里把完整代码奉上,大家可以参考,关注,后续还会有改进更新。
从以上我探索的过程可以看出,数据类别的平衡度和是否归一化对KNN算法的性能都有影响,从之前的手记里也能看到,数据的收集,不良数据的剔除也对CNN模型性能有很大影响,由此我们可以得出一个结论:数据的收集、整理和预处理是提升机器学习模型准确率的一个关键因素。而同样重要的则是机器学习算法的选择,在选择机器学习算法的时候最好能先了解影响算法准确率的因素以及算法的优缺点,提到这个,我要说一下,在实际运行实时人脸识别程序的时候发现识别速度明显比之前用CNN模型的时候要慢,这是因为KNN算法在预测的时候要将新样本与所有训练样本进行比较(时间复杂度达到O(n),n代表已知样本数),还是比较耗时的,这样一来实时性就不够了。作为一个工程师,既然还有问题,那就要继续改进,这个系列就还要继续,至于如何继续,我先放一张图:
欲知详情,且听下回分解。
参考资料
本作品采用知识共享 署名-非商业性使用-相同方式共享 4.0 国际 许可协议进行许可。要查看该许可协议,可访问 http://creativecommons.org/licenses/by-nc-sa/4.0/ 或者写信到 Creative Commons, PO Box 1866, Mountain View, CA 94042, USA。








热门评论
-

慕婉清73317202018-11-26 2
-

慕婉清73317202018-11-23 2
-

慕婉清73317202018-11-26 2



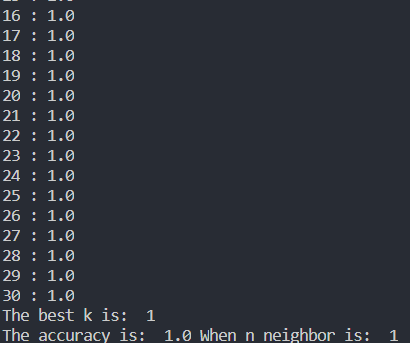
查看全部评论你好!我做了实验,加上了lfw的数据集放在other这一目录下.knn的值发生了变化.我设置的是除我跟我朋友以外其它人显示为other,可能是采取的图片数量不够,因而分辨除我三人以外的其它人的时候依旧有很大的误差.
最后一张截图,是我对最后识别的一丁点改进.蟹蟹你的帮助.[期待你后续的讲解]
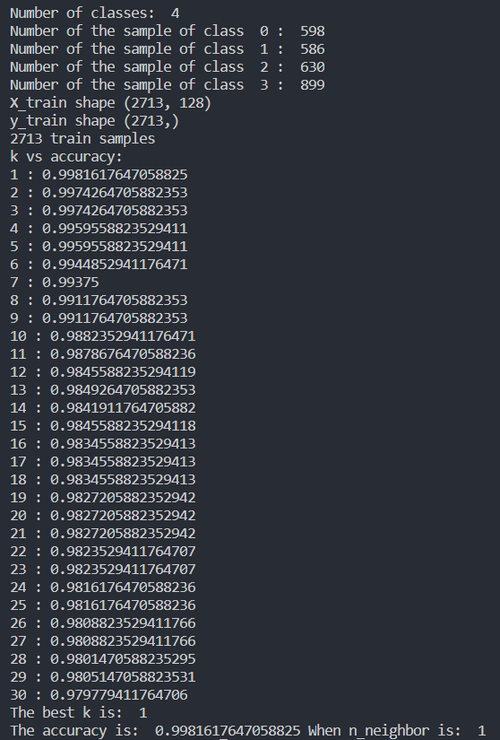
您好!我用的是我的图片630张,我一个朋友的图片590张 knn后的结果全是1 正常吗?
然后我进行了人脸识别 在光线好的状况下能准确识别出 识别率很高.
你好!我做了实验,加上了lfw的数据集放在other这一目录下.knn的值发生了变化.我设置的是除我跟我朋友以外其它人显示为other,可能是采取的图片数量不够,因而分辨除我三人以外的其它人的时候依旧有很大的误差.
最后一张截图,是我对最后识别的一丁点改进.蟹蟹你的帮助.[期待你后续的讲解]