
正则表达式(Regular Expression) 能够有效地实现对复杂字符串的分析并提取出相关信息,Python 的 re 模块提供各种正则表达式的匹配操作,将正则表达式转化为字节码,利用 C 语言的匹配引擎进行深度优先的匹配。
首先定义需要分析的字符串,如下所示:
f_str = r'<div class="small_header">Executed Tests</div> \
<td align="right" width="40%"><a class="gray_red_link" \
href="javascript:expandExecDetails()">Expand All</a> " \
<a class='
打印后显示如下:
<div class="small_header">Executed Tests</div> \
<td align="right" width="40%"><a class="gray_red_link" \
href="javascript:expandExecDetails()">Expand All</a> " \
<a class=
Python特别设计了原始字符串(raw string),用’r’作为字符串的前缀会自动将字符串内的反斜杠转义,比如r”\n”表示两个字符”\”和”n”,而不是换行符。因此一个字符串如果包含很多需要转义的字符,可以使用raw string,而无需对每一个字符都进行转义。
大家可能发现了r’…‘表示法不能表示多行字符串,字符串中的续行符“\”被作为一个字符处理,如果不添加续行符“\”,那么字符串在语法上是错误的。因此如果要表示多行字符串,可以用三引号’’’…’’'表示,如下所示:
f_str = r'''<div class="small_header">Executed Tests</div>
<td align="right" width="40%"><a class="gray_red_link"
href="javascript:expandExecDetails()">Expand All</a> "
<a class='''
打印后显示如下:
<div class="small_header">Executed Tests</div>
<td align="right" width="40%"><a class="gray_red_link"
href="javascript:expandExecDetails()">Expand All</a> "
<a class=
接下来分别详解下正则表达式的使用。
正则表达式使用反斜杠“\”来代表特殊形式或用作转义字符,在Python的语法中需要用“\ ” 转义正则表达式中的“\”,因此每一个“\”都需要转义为“\”。为了使正则表达式具有更好的可读性,可以用原始字符串(raw string),即用’r’作为字符串的前缀。Python中写正则表达式时推荐使用这种形式。
re.findall(pattern, string[, flags])方法能够以列表的形式返回能匹配的子串。比如以下例子中以列表类型返回字符串中所有匹配的任意非空白字符(\S+):
ret = re.findall(r'(\S+)', f_str)
打印后显示如下:
['<div', 'class="small_header">Executed', 'Tests</div>', '<td', 'align="right"', 'width="40%"><a', 'class="gray_red_link"', 'href="javascript:expandExecDetails()">Expand', 'All</a> "', '<a', 'class=']
比如以下例子中可以精确返回'javascript:expandExecDetails()'字符串:
ret = re.findall(r'href.*"(\S+)".*Expand', f_str)
打印后显示如下:
['javascript:expandExecDetails()']
re.compile(strPattern[, flag])这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象,实现更有效率的匹配。第二个参数flag是匹配模式,取值可以使用运算符,比如re.I | re.M。另外,可选值有:
re.I(IGNORECASE): 忽略大小写
re.M(MULTILINE): 多行模式,改变’^‘和’$‘的行为
re.S(DOTALL): 在匹配时为点任意匹配模式,改变’.‘的行为,’.'也可以代表换行符
re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
re.X(VERBOSE): 详细模式。该模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
将以上的例子更改为re.compile方式,如下所示:
regex = re.compile(r'href.*"(\S+)".*Expand')
ret = regex.findall(f_str)
Python还提供了两种不同的原始操作:match和search。match是从字符串的起点开始做匹配,只有在开始位置匹配成功时候才返回,否则返回none。search扫描整个字符串查找匹配并返回第一个成功的匹配。两者都提供了group()方法,返回被RE匹配的字符串。
print re.match("class",f_str)
print re.search("class", f_str).group(0)
打印后显示如下:
None
class
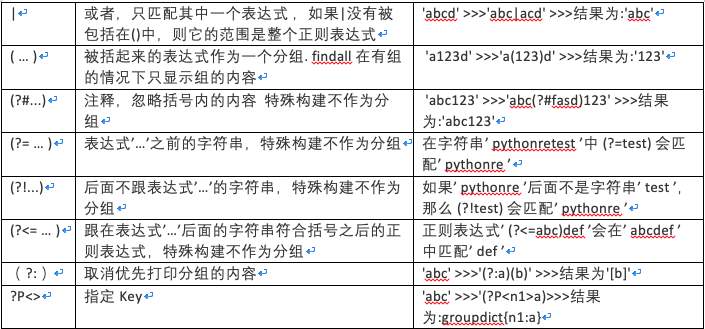
附:正则表达式元字符和语法

·······································
欢迎大家订阅《教你用 Python 进阶量化交易》专栏!






