
“Python有什么好学的”这句话可不是反问句,而是问句哦。
主要是煎鱼觉得太多的人觉得Python的语法较为简单,写出来的代码只要符合逻辑,不需要太多的学习即可,即可从一门其他语言跳来用Python写(当然这样是好事,谁都希望入门简单)。
于是我便记录一下,如果要学Python的话,到底有什么好学的。记录一下Python有什么值得学的,对比其他语言有什么特别的地方,有什么样的代码写出来更Pythonic。一路回味,一路学习。
为什么是斐波那契
谈到生成器/迭代器,人们总是喜欢用斐波那契数列来举例。
斐波那契数列,数学表示为a(1)=0, a(2)=1, a(i)=a(i-1)+a(i-2) (i>=3):
0 1 1 2 3 5 8 13 21 ...
用一句话说,就是第三位数起,当前这位数是前两位的和。
当然,使用斐波那契来举例是一个很合适的选择。
那么,为什么说到生成器/迭代器就喜欢斐波那契,而不是其他呢?
斐波那契数列有一个特征:当前这位数的值,可以通过前两位数的值推导出来。比如,我知道了第n位数是5,第n+1位数是8,那我就可以轻易地得出,第n+2位必然是5+8=13。
即,斐波那契数是可以通过推导式得出的。
就是这样一种类似于冥冥注定的感觉:当前的平行空间,是由你之前的选择决定的。而且是钦定好的,你接下来的每一步,其实都已经被决定了,由什么决定呢,由你以前走过的路决定的。
那么,换句话来说,即能由推导式得出的数列,其实都可以用来做生成器/迭代器的例子。例如,煎鱼用一条式子y(n)=y(n-1)^2 + 1 (n>=1), y(1)=1,一样能拿来当例子。
既然这样,那就用y(n)=y(n-1)^2 + 1 (n>=1), y(1)=1吧。
原始低效的循环
一开始,人们的思想很简单,如果要求y(n)=y(n-1)^2 + 1 (n>=1), y(1)=1中y数列的第13位,即y(13),那很简单,就轮询到13个就好了。
def y():
y_current = 1
n = 1
while n < 13:
y_current = y_current ** 2 + 1
n += 1
print(n, y_current)
输出也挺长的,就截个图算了:
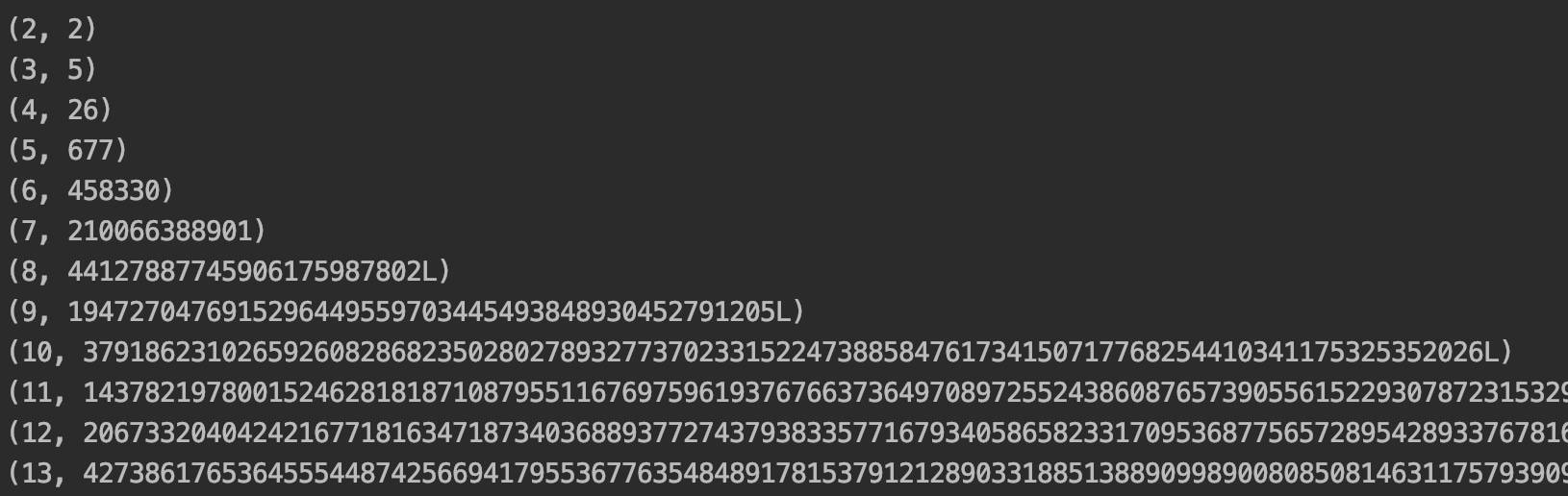
这个时候,这个代码是完全够用的。接下来,煎鱼加点需求(PM般的狞笑):
- 暴露n的值,n值可以作为参数输入,即我需要控制数列计算到哪
- 函数返回(输出)整个数列
接下来,函数改成:
def y(n_max):
y_current = 0
n = 0
ret_list = []
while n < n_max:
y_current = y_current ** 2 + 1
n += 1
ret_list.append(y_current)
return ret_list
if __name__ == '__main__':
for i in y(13):
print(i)
看起来没什么毛病,完全符合要求。但是,问题出现在当函数的参数n_max较大的时候。要多大呢,煎鱼尝试输出n_max=13000000,即:
if __name__ == '__main__':
for i in y(13000000):
print(i)
我们看得出来,这个函数的计算量十分大,以煎鱼当前的电脑配置(Macbook pro 2017 i5 8G RAM),等了一两分钟还没结束,只好强行中断了。
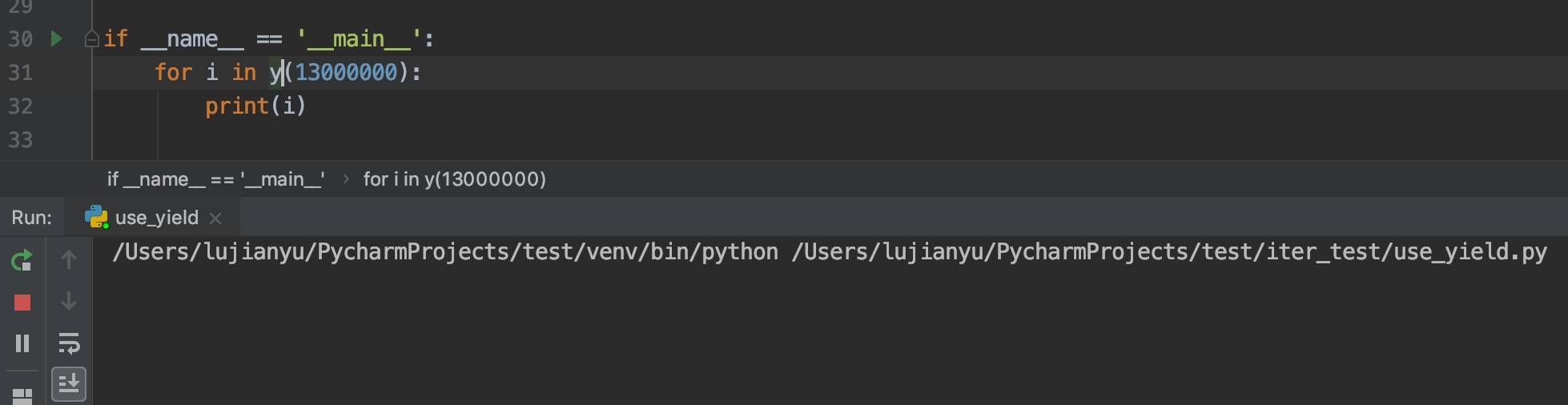
程序为什么卡那么久呢。因为在函数的逻辑中,程序试图将13000000个值都计算出来再返回list以供外接轮询,而且这13000000个一个比一个难算(越来越大,指数增长)。同时,该list也占了庞大的内存空间。
到了这个时候,煎鱼终于要引入生成器了。
生成器的小试牛刀
其实煎鱼就加入了一个yield,并稍作修改:
def y_with_yield(n_max):
y_current = 0
n = 0
while n < n_max:
y_current = y_current ** 2 + 1
n += 1
yield y_current
if __name__ == '__main__':
for i in y_with_yield(13000000):
print(i)
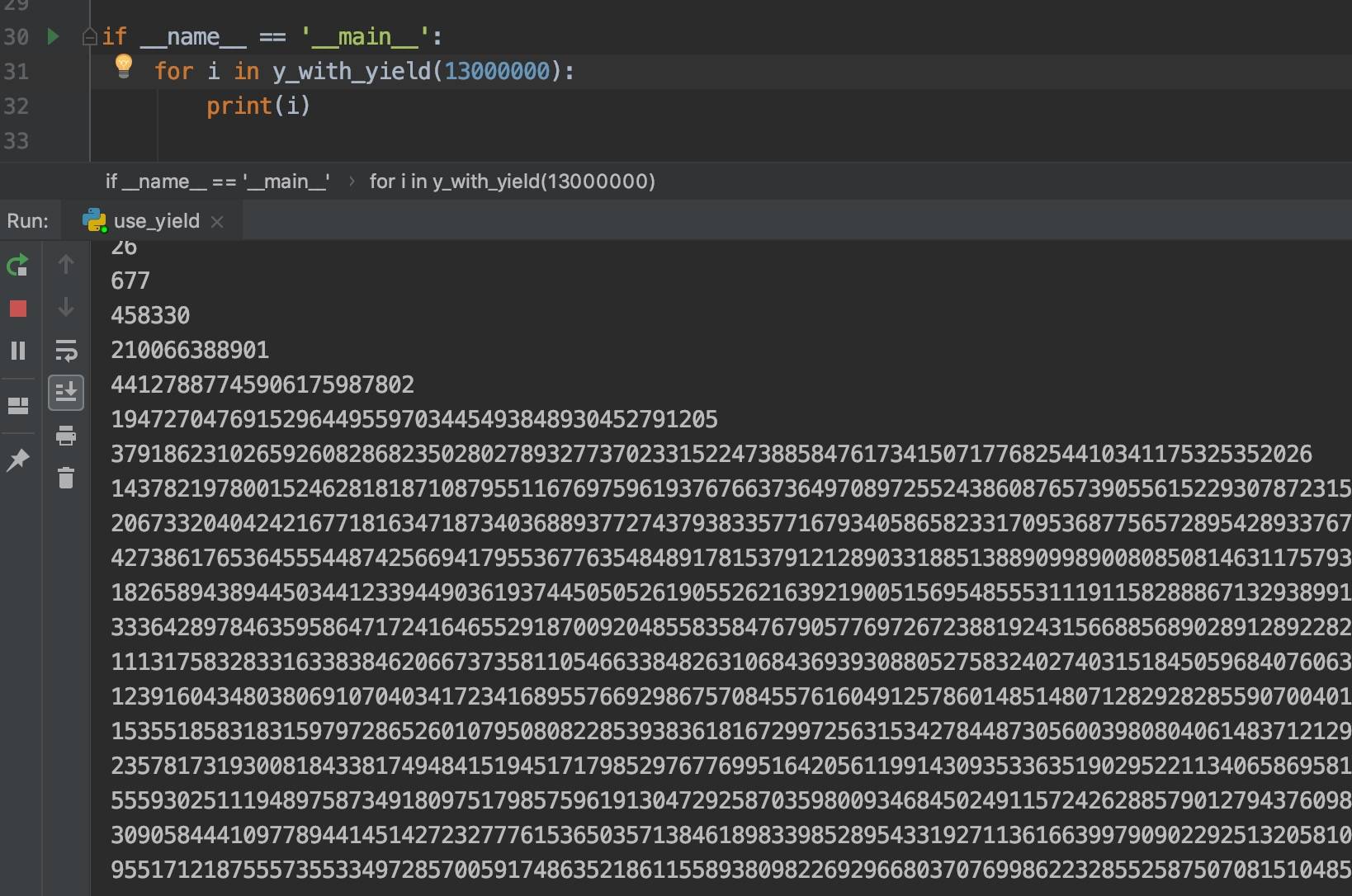
虽然屏幕滚动得很慢,但是起码是在实时地滚动的。
加入了yield变成这样,其实就是搞成了一个简单的生成器。在这里,生成器的作用有:
for i in y_with_yield(13000000)的循环中,每一次循环程序才会进入函数去计算,而不会把全部结果都计算出来再返回- 由于不会把全部结果都计算出来再返回,程序运行所需的内存也大幅地减少
暂时给出初步结论:
- 这个小生成器在较大数据的计算量时,有较大的优势
- 程序把推导式的计算通过yield分散了,降低了cpu和内存的压力
- 如果没有煎鱼的需求,这一切都白搭且多余
我们再来看下生成器的其他用途吧。
通过缓存机制读取文件
在读文件或处理文件时使用缓存是很有必要的,因为我们总是不知道文件会有多大,文件的大小会不会把程序给拖垮。
煎鱼新建一个文件(假设叫test.txt),并往其中写入文本,运行以下代码:
def read_file(file_path):
BLOCK_SIZE = 100
with open(file_path, 'rb') as f:
while True:
block = f.read(BLOCK_SIZE)
if block:
yield block
else:
return
if __name__ == '__main__':
for i in read_file('./test.txt'):
print(i)
print('--------------block-split--------------')
我们把100个长度分为一个block,这个block就相当于我们的缓存:先从文件中读100个,然后让程序处理这100个字符(此处处理为print),再读下一个100。其中block-split的输出是为了让我们更好地辩识出block的头尾。
生成器类和生成器对象
通过yield瞎搞出来的简易生成器有一个很大的限制,就是必须要在循环内。
虽然“迭代”和“循环”有关联,但是当生成器的生成逻辑无比复杂时,比如“推导”的方法已经无法用数学推导式表达时,或者某种场景下的业务逻辑比较复杂以至于无法直接通过循环表达时,生成器类来了。
生成器类看起来很简单,其实就是将煎鱼在上面写的简单生成器写成一个类。
重点就是,我们得找到“推导”,推导在这里是指next函数 —— 我们实现的生成器类最重要的就是next()。
我们来实现上面的y函数的生成器类:
class Y(object):
def __init__(self, n_max):
self.n_max = n_max
self.n = 0
self.y = 0
def __iter__(self):
return self
def next(self):
if self.n < self.n_max:
self.y = self.y ** 2 + 1
self.n += 1
return self.y
raise StopIteration()
if __name__ == '__main__':
y = Y(13)
for i in y:
print(i)
有几点是需要注意的:
- 类需要包含
__iter__()函数,而返回的不一定是self,但是需要生成器 - 实现next方法,“迭代”的逻辑请放到该函数里面
- 如果需要引入别的库或者写别的函数,可以在类中随便加
接下来,煎鱼带来一段很无聊的表演,来表示__iter__()函数而返回的不一定是self:
class SuperY(object):
def __init__(self, n_max):
self.n_max = n_max
def __iter__(self):
return Y(self.n_max)
if __name__ == '__main__':
sy = SuperY(13)
for i in sy:
print(i)
这段代码的输出和上一段一模一样。
生成器的照妖镜
这里照妖镜的意思,指一个能鉴别某对象(甚至不是对象)是否一个生成器的东西。
说起来,可能会有点多余而且零碎。
其中有三个函数:
- isgeneratorfunction(),字面意思,是否生成器函数
- isgenerator(),还是字面意思,是否生成器
- isinstance(),这个指某对象是否为某个类的实例
我们把前面写过的y(带yield的函数),和Y(生成器类)导入后,进行实验观察:
from use_yield import y_with_yield as y
from iter_obj import Y
from inspect import isgeneratorfunction, isgenerator
from types import GeneratorType
from collections import Iterator
if __name__ == '__main__':
print(isgeneratorfunction(y)) # True
print(isgeneratorfunction(Y)) # False
print(isgeneratorfunction(y(5))) # False
print(isgeneratorfunction(Y(5))) # False
print(isgenerator(y)) # False
print(isgenerator(Y)) # False
print(isgenerator(y(5))) # True
print(isgenerator(Y(5))) # False
print("")
print(isinstance(y, GeneratorType)) # False
print(isinstance(y(5), GeneratorType)) # True
print(isinstance(Y, GeneratorType)) # False
print(isinstance(Y(5), GeneratorType)) # False
print("")
print(isinstance(y, Iterator)) # False
print(isinstance(y(5), Iterator)) # True
print(isinstance(Y, Iterator)) # False
print(isinstance(Y(5), Iterator)) # True
实验的结论为:
- 带yield的y函数是一个生成器函数,带yield的y函数带上参数5后,称为了生成器。因为y是函数的引用,而带上了参数5后,y(5)就不再是函数了,而是通过yield进化成了生成器。
- 生成器是类GeneratorType的实例,但很遗憾的是,生成器类的实例不是生成器(黑人问号)。
- 然而,生成器y(5)和生成器类的实例都属于迭代器。
其他乱七八糟的
Python里面,range和xrange有什么不同,用哪个更好,为什么?
对的,就是和生成器有关系,嘿嘿。
先这样吧
若有错误之处请指出,更多地请关注造壳。




