熊猫数据框索引排序不正确
我想问一个关于 python 中 panda 的问题 - 特别是关于它的DataFrame()功能。
我有以下数据想要转换为数据框:
pop = {'Nevada': {2001: 2.4, 2002: 2.9}, 'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame3 = pd.DataFrame(pop)
我期望嵌套字典的外部键是列名称,内部键是索引名称:
请注意,解释器语法是在 Jupyter Notebook Python 3 上运行的 iPython
Nevada Ohio
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6
但是,我不断获取密钥排列错误的数据:
>> frame3
Nevada Ohio
2001 2.4 1.7
2002 2.9 3.6
2000 NaN 1.5
我似乎无法使索引按我想要的顺序出现。
为什么会发生这种情况?我该如何纠正这个问题?
奇怪的是,这是我的 Jupyter 笔记本中出现的内容:
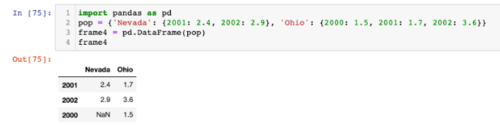
但是当使用 的learnpython.orgIDE 时,我得到以下预期输出:

同样,在我的 iPython 上观察到相同的错误输出:
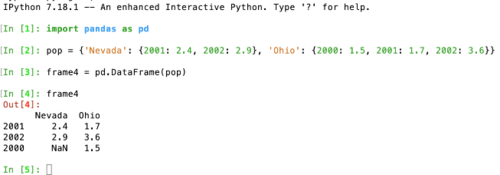
 翻阅古今
翻阅古今浏览 351回答 2
2回答
-

翻翻过去那场雪
一种简单的解决方案可以是:pop = {'Nevada': {2000:np.nan,2001: 2.4, 2002: 2.9}, 'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}frame3 = pd.DataFrame(pop)或者在创建数据框后对索引进行排序:frame3 = pd.DataFrame(pop).sort_index()结果就是你想要的: Nevada Ohio2000 NaN 1.52001 2.4 1.72002 2.9 3.6 -

狐的传说
您只需将其放入数据框中并对其进行排序即可。看一下这个 :pandas_dataframe = pd.DataFrame(pop).sort_index()print(pandas_dataframe)Out[128]: Nevada Ohio2000 NaN 1.52001 2.4 1.72002 2.9 3.6


相关分类
 Python
Python