如何通过字典在 pandas 中创建新行
我对 pandas DataFrame 有问题 - 我不明白如何创建新行并将它们与字典合并。
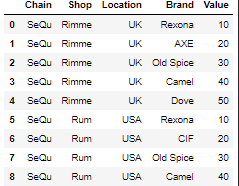
例如,我有这个数据框:
shops = [{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'Rexona', 'Value': 10},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'AXE', 'Value': 20},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'Old Spice', 'Value': 30},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'Camel', 'Value': 40},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'Dove', 'Value': 50},
{'Chain': 'SeQu', 'Shop': 'Rum', 'Location': 'USA', 'Brand': 'Rexona', 'Value': 10},
{'Chain': 'SeQu', 'Shop': 'Rum', 'Location': 'USA', 'Brand': 'CIF', 'Value': 20},
{'Chain': 'SeQu', 'Shop': 'Rum', 'Location': 'USA', 'Brand': 'Old Spice', 'Value': 30},
{'Chain': 'SeQu', 'Shop': 'Rum', 'Location': 'USA', 'Brand': 'Camel', 'Value': 40}]
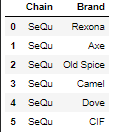
同时,我有一个具有 Chain-Brand 连接的字典数据框:
chain_brands = [{'Chain': 'SeQu', 'Brand': 'Rexona'},
{'Chain': 'SeQu', 'Brand': 'Axe'},
{'Chain': 'SeQu', 'Brand': 'Old Spice'},
{'Chain': 'SeQu', 'Brand': 'Camel'},
{'Chain': 'SeQu', 'Brand': 'Dove'},
{'Chain': 'SeQu', 'Brand': 'CIF'}]
因此,我需要创建新行并用 0 填充它们(如果品牌为 Null)。它应该看起来像这样:
output = [{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'Rexona', 'Value': 10},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'AXE', 'Value': 20},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'Old Spice', 'Value': 30},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'Camel', 'Value': 40},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'Dove', 'Value': 50},
{'Chain': 'SeQu', 'Shop': 'Rimme', 'Location': 'UK', 'Brand': 'CIF', 'Value': 0},
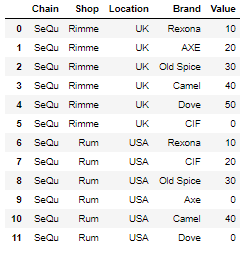
谢谢!
 Smart猫小萌
Smart猫小萌1回答
-

慕尼黑5688855
您可以从数据帧创建多索引chain_brands,然后groupby与 一起使用reindex来解决此问题:mi = pd.MultiIndex.from_arrays(chain_brands.values.T, names=['Chain', 'Brand'])s = shops.set_index(['Chain', 'Brand']).\ groupby(['Location', 'Shop']).\ apply(lambda x: x.reindex(mi, fill_value=0)).\ drop(columns=['Location', 'Shop']).\ reset_index()结果: Location Shop Chain Brand Value0 UK Rimme SeQu Rexona 101 UK Rimme SeQu Axe 02 UK Rimme SeQu Old Spice 303 UK Rimme SeQu Camel 404 UK Rimme SeQu Dove 505 UK Rimme SeQu CIF 06 USA Rum SeQu Rexona 107 USA Rum SeQu Axe 08 USA Rum SeQu Old Spice 309 USA Rum SeQu Camel 4010 USA Rum SeQu Dove 011 USA Rum SeQu CIF 20

相关分类
 Python
Python