如何使用动态 HTML (Python) 从网页中抓取数据?
我试图弄清楚如何从以下网址中抓取数据:https://www.aap.org/en-us/advocacy-and-policy/aap-health-initiatives/nicuverification/Pages/NICUSearch.aspx
这是数据类型:
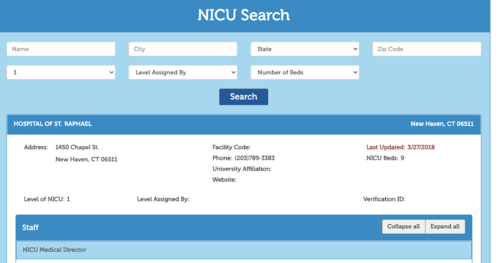
看起来所有内容都是从数据库填充并通过 JavaScript 加载到网页中。
我过去使用seleniumand做过类似的事情PhantomJS,但我不知道如何在 Python 中获取这些数据字段。
正如预期的那样,我不能用于pd.read_html此类问题。
是否可以解析以下结果:
from selenium import webdriver
url="https://www.aap.org/en-us/advocacy-and-policy/aap-health-initiatives/nicuverification/Pages/NICUSearch.aspx"
browser = webdriver.PhantomJS()
browser.get(url)
content = browser.page_source
或者也许可以访问实际的底层数据?
如果没有,除了几个小时的复制和粘贴之外,还有什么其他方法?
编辑:
基于下面的答案,来自 @thenullptr,我已经能够访问该材料,但仅限于第 1 页。我如何调整它以遍历所有页面 [正确解析的建议]?我的最终目标是将其放入 pandas 数据框中
import requests
from bs4 import BeautifulSoup
r = requests.post(
url = 'https://search.aap.org/nicu/',
data = {'SearchCriteria.Level':'1', 'X-Requested-With':'XMLHttpRequest'},
) #key:value
html = r.text
# Parsing the HTML
soup = BeautifulSoup(html.split("</script>")[-1].strip(), "html")
div = soup.find("div", {"id": "main"})
div = soup.findAll("div", {"class":"blue-border panel list-group"})
def f(x):
ignore_fields = ['Collapse all','Expand all']
output = list(filter(bool, map(str.strip, x.text.split("\n"))))
output = list(filter(lambda x: x not in ignore_fields, output))
return output
results = pd.Series(list(map(f, div))[0])
 GCT1015
GCT10151回答
-

Smart猫小萌
继我上一条评论之后,下面的内容应该为您提供一个很好的起点。在查看 XHR 调用时,您只想查看每个调用发送和接收的数据,以查明您需要的数据。下面是进行搜索时发送到 API 的原始 POST 数据,看起来您需要至少使用一个并包含最后一个。{ "SearchCriteria.Name": "smith", "SearchCriteria.City": "", "SearchCriteria.State": "", "SearchCriteria.Zip": "", "SearchCriteria.Level": "", "SearchCriteria.LevelAssigner": "", "SearchCriteria.BedNumberRange": "", "X-Requested-With": "XMLHttpRequest"}这是一个简单的示例,说明如何使用 requests 库发送 post 请求,网页将回复原始数据,以便您可以使用 BS 或类似的方法来解析它以获取您需要的信息。import requestsr = requests.post('https://search.aap.org/nicu/', data = {'SearchCriteria.Name':'smith', 'X-Requested-With':'XMLHttpRequest'}) #key:valueprint(r.text)印刷 <strong class="col-md-8 white-text">JOHN PETER SMITH HOSPITAL</strong>...https://requests.readthedocs.io/en/master/user/quickstart/

相关分类
 Python
Python