加快 Pandas 中 csv 文件的条件行读取速度?
我修改了这篇文章中的一行,以有条件地从 csv 文件中读取行:
filename=r'C:\Users\Nutzer\Desktop\Projects\UK_Traffic_Data\test.csv'
df = (pd.read_csv(filename, error_bad_lines=False) [lambda x: x['Accident_Index'].str.startswith('2005')])这条线对于小型测试数据集来说效果非常好。但是,我确实有一个很大的 csv 文件需要读取,并且读取该文件需要很长时间。事实上,最终还是NotebookApp.iopub_data_rate_limit达到了。我的问题是:
有没有办法改进这段代码及其性能?
“Accident_Index”列中的记录已排序。因此,如果达到“Accident_Index”不等于的值,则中断读取语句可能是一种解决方案
str.startswith('2005')。您对如何做到这一点有什么建议吗?
这是一些示例数据:
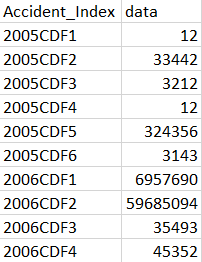
所需的输出应该是包含前六条记录的 pandas 数据框。
 慕虎7371278
慕虎7371278浏览 345回答 1
1回答
-

慕尼黑的夜晚无繁华
我们最初可以根据上述条件仅读取我们想要过滤的特定列(假设这会显着减少读取开销)。#reading the mask columndf_indx = (pd.read_csv(filename, error_bad_lines=False,usecols=['Accident_Index']) [lambda x: x['Accident_Index'].str.startswith('2005')])然后,我们可以使用该列中的值,使用skiprows和nrows属性从文件中读取剩余的列,因为它们是输入文件中的排序值df_data= (pd.read_csv(filename, error_bad_lines=False,header=0,skiprows=df_indx.index[0],nrows=df_indx.shape[0]))df_data.columns=['Accident_index','data']这将给出我们想要的数据的子集。我们可能不需要单独获取列名。

相关分类
 Python
Python