修复了 one-hot 编码中的冗余,但在尝试反转时仍然出现错误
我正在进行 one-hot 编码并使用 𝜃̂ =((𝕏𝑇𝕏)^−1) * 𝕏𝑇𝕪 来估计 theta。由于冗余,我收到了错误,因此我决定删除有冗余的列。
这是在删除列之前:

这是我的代码,因为我尝试删除具有冗余的列:
def one_hot_encode_revised(data):
all_columns = data.columns
records = data[all_columns].to_dict(orient='records')
encoder = DictVectorizer(sparse=False)
encoded_X = encoder.fit_transform(records)
df = pd.DataFrame(data=encoded_X, columns=encoder.feature_names_)
return df.drop(['day=Fri', 'sex=Male', 'smoker=No', 'time=Dinner'], axis =1)
one_hot_X_revised = one_hot_encode_revised(X)
输出如下:
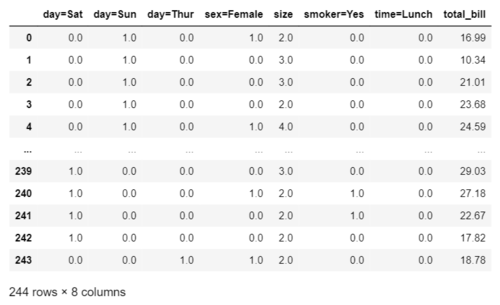
然后,我使用这个函数根据上面的方程估计 theta:
def get_analytical_sol(X, y):
"""
Computes the analytical solution to our least squares problem
Parameters
-----------
X: a 2D dataframe of numeric features (one-hot encoded)
y: a 1D vector of tip amounts
Returns
-----------
The estimate for theta
"""
return np.linalg.inv(X.T * X) * (X.T * y)
运行这个:
revised_analytical_thetas = get_analytical_sol(one_hot_X_revised, tips)
我的错误是: ValueError: 无法强制转换为 DataFrame,形状必须是 (8, 244): 给定 (252, 252)
作为参考,提示是这样的:

我是否正确地消除了冗余,如果是,为什么仍然有错误?
 慕勒3428872
慕勒34288721回答
-

偶然的你
您在这一行中有一个错误return np.linalg.inv(X.T * X) * (X.T * y)。你想要做的是矩阵乘法。在 pandas 数据框中,符号*不用于矩阵乘法。您需要使用@或dot()数据框的方法。

相关分类
 Python
Python