卷积在时间步长为 1 的网络上有用吗?
此代码来自https://www.kaggle.com/dkaraflos/1-geomean-nn-and-6featlgbm-2-259-private-lb,本次比赛的目标是利用地震信号来预测实验室的时间地震。这个环节的人在4000多个团队中获得了第一名
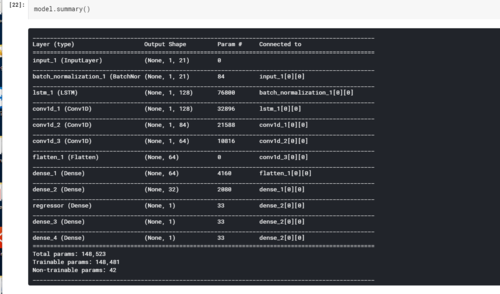
def get_model():
inp = Input(shape=(1,train_sample.shape[1]))
x = BatchNormalization()(inp)
x = LSTM(128,return_sequences=True)(x) # LSTM as first layer performed better than Dense.
x = Convolution1D(128, (2),activation='relu', padding="same")(x)
x = Convolution1D(84, (2),activation='relu', padding="same")(x)
x = Convolution1D(64, (2),activation='relu', padding="same")(x)
x = Flatten()(x)
x = Dense(64, activation="relu")(x)
x = Dense(32, activation="relu")(x)
#outputs
ttf = Dense(1, activation='relu',name='regressor')(x) # Time to Failure
tsf = Dense(1)(x) # Time Since Failure
classifier = Dense(1, activation='sigmoid')(x) # Binary for TTF<0.5 seconds
model = models.Model(inputs=inp, outputs=[ttf,tsf,classifier])
opt = optimizers.Nadam(lr=0.008)
# We are fitting to 3 targets simultaneously: Time to Failure (TTF), Time Since Failure (TSF), and Binary for TTF<0.5 seconds
# We weight the model to optimize heavily for TTF
# Optimizing for TSF and Binary TTF<0.5 helps to reduce overfitting, and helps for generalization.
model.compile(optimizer=opt, loss=['mae','mae','binary_crossentropy'],loss_weights=[8,1,1],metrics=['mae'])
return model
不过,根据我的推导,我认为x = Convolution1D(128, (2),activation='relu', padding="same")(x)和x = Dense(128, activation='relu ')(x)具有相同的效果,因为卷积核以时间步长为1对序列进行卷积。原则上,它与全连接层非常相似。为什么这里使用conv1D而不是直接使用全连接层呢?我的推导有错误吗?
 手掌心
手掌心1回答
-

拉莫斯之舞
1) 假设您将一个序列输入到 LSTM(正常用例):它不会相同,因为 LSTM 返回一个序列 ( return_sequences=True),从而不会降低输入维度。因此,输出形状为(Batch, Sequence, Hid)。这被馈送到在维度(即 )Convolution1D上执行卷积的层。因此,实际上,一维卷积的目的是在 LSTM 之后提取局部一维子序列/补丁。Sequence(Sequence, Hid)如果有的话return_sequences=False,LSTM 将返回最终状态h_t。为了确保与密集层具有相同的行为,您需要一个完全连接的卷积层,即长度为长度的内核Sequence,并且我们需要与Hid输出形状中一样多的滤波器。这将使一维卷积相当于密集层。2)假设您没有向 LSTM 输入序列(您的示例):在您的示例中,LSTM 用作密集层的替代品。它具有相同的功能,但它给出的结果略有不同,因为门会进行额外的转换(即使我们没有序列)。(Sequence, Hid)由于随后在=上执行卷积(1, Hid),因此它确实是按时间步进行操作的。由于我们有 128 个输入和 128 个过滤器,因此它是完全连接的,并且内核大小足以在单个元素上进行操作。这符合上面定义的一维卷积相当于密集层的标准,所以你是对的。附带说明一下,这种类型的架构通常是通过神经架构搜索获得的。这里使用的“替代品”并不常见,并且通常不能保证比更成熟的替代品更好。然而,在很多情况下,使用强化学习或进化算法可以使用“非传统”解决方案获得稍微更高的准确性,因为非常小的性能提升可能只是偶然发生,并且不一定反映架构的有用性。

相关分类
 Python
Python