Python“charmap”编解码器上的 Docx (xml) 文件解析错误无法解码位置 7618
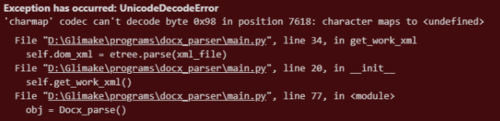
我正在尝试解析 docx 文件。我先解压缩它,然后尝试读取 Document.xml 文件,with open(..)并引发错误“'charmap'编解码器无法解码位置 7618 中的字节 0x98:字符映射到”。XML 是“UTF-8”编码:

错误:
我写了以下代码:
with open(self.tempDir + self.CONFIG['main_xml']) as xml_file: self.dom_xml = etree.parse(xml_file)
我尝试强制编码为 UTF-8,但随后我无法etree.fromstring(..)正确读取
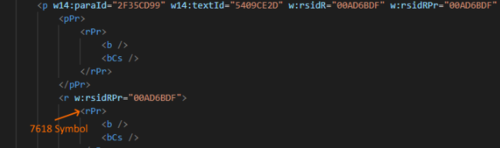
7618 符号(来自错误)是:
请帮我。如何正确读取xml文件?谢谢
 慕妹3146593
慕妹3146593浏览 202回答 1
1回答
-

蝴蝶刀刀
这对您的文件没有错误:import zipfileimport xml.etree.ElementTree as ETzipfile.ZipFile('file.docx').extractall()root = ET.parse('word/document.xml').getroot()

相关分类
 Python
Python